
ホームページ >テクノロジー周辺機器 >AI >ビデオ タイミング ポジショニングにおいて清華大学が開発した LLM4VG ベンチマークのパフォーマンスを評価する
ビデオ タイミング ポジショニングにおいて清華大学が開発した LLM4VG ベンチマークのパフォーマンスを評価する

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-01-04 22:38:141271ブラウズ

12 月 29 日のニュースでは、大規模言語モデル (LLM) の範囲が、単純な自然言語処理から、テキスト、オーディオ、ビデオなどのマルチモーダル分野まで拡大しました。鍵の 1 つは、ビデオ タイミング ポジショニング (ビデオ グラウンディング、VG) です。
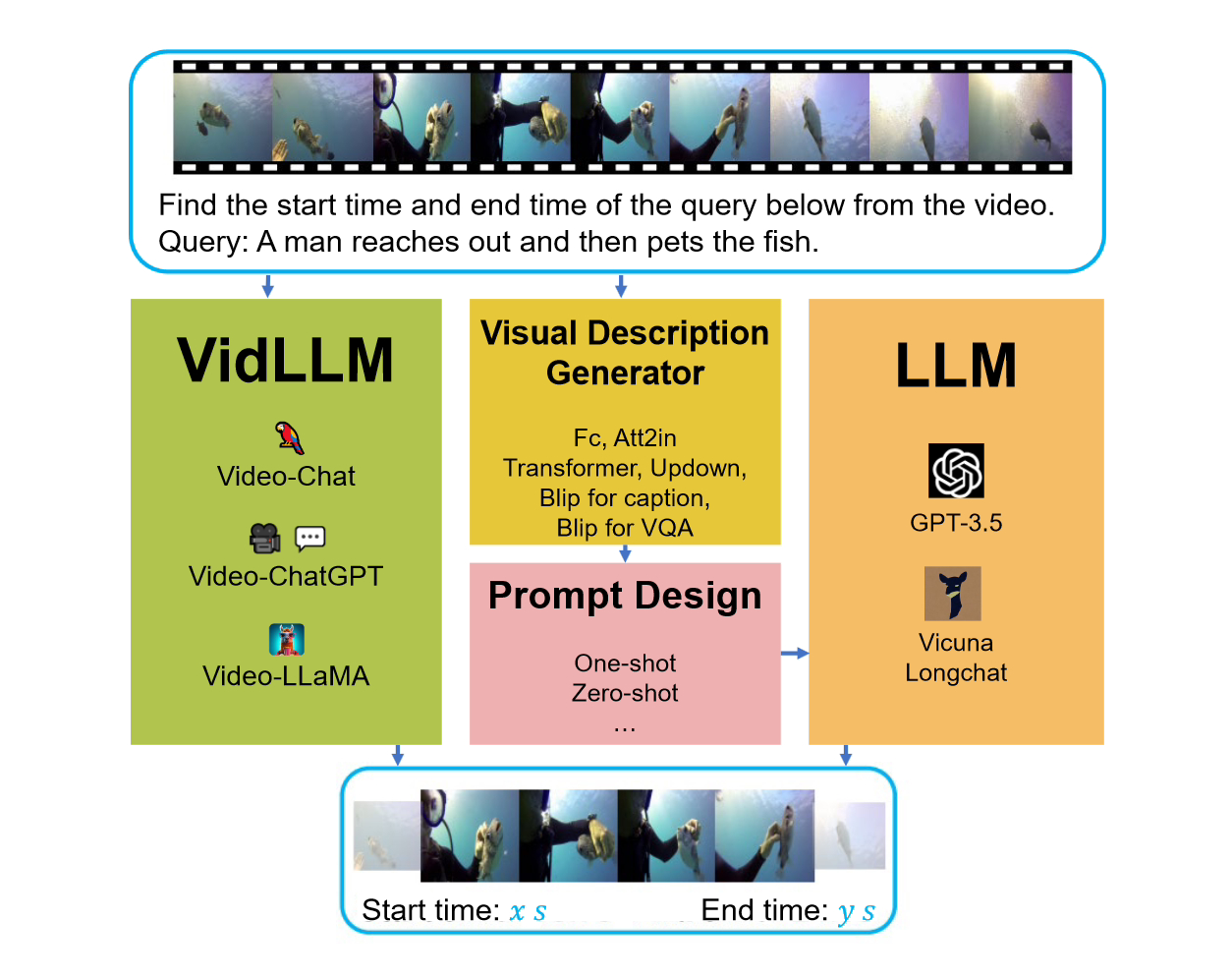
LLM4VG」ベンチマークを開始しました。
このベンチマークを検討する際には、2 つの主要な戦略が検討されました。最初の戦略は、ビデオ言語モデル (LLM) をテキスト ビデオ データセット (VidLLM) 上で直接トレーニングすることです。この方法では、大規模なビデオ データ セットでトレーニングすることでビデオと言語の関連性を学習し、モデルのパフォーマンスを向上させます。 2 番目の戦略は、従来の言語モデル (LLM) と事前トレーニングされたビジョン モデルを組み合わせることです。この方法は、ビデオの視覚的特性を組み合わせた事前トレーニング済みのビジュアル モデルに基づいており、1 つの戦略では、VidLLM モデルがビデオ コンテンツと VG タスク命令を直接処理し、トレーニング出力を実行してテキストとビデオの関係を予測します。 2 番目の戦略はより複雑で、LLM (言語および視覚モデル) と視覚的記述モデルの使用が含まれます。これらのモデルは、VG (ビデオ ゲーム) タスクの指示と組み合わせたビデオ コンテンツのテキスト説明を生成でき、これらの説明は慎重に設計されたプロンプトを使用して実装されます。 これらのプロンプトは慎重に設計されており、その目的は、VG の指示と提供される視覚的な説明を効果的に組み合わせて、LLM がタスク関連のビデオ コンテンツを処理および理解できるようにすることです。
これらのプロンプトは慎重に設計されており、その目的は、VG の指示と提供される視覚的な説明を効果的に組み合わせて、LLM がタスク関連のビデオ コンテンツを処理および理解できるようにすることです。
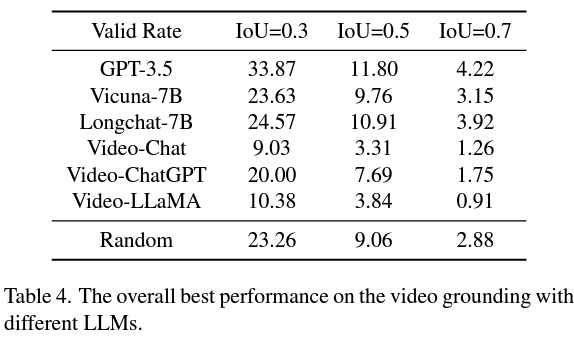
VidLLM はビデオ コンテンツで直接トレーニングされているにもかかわらず、満足のいく VG パフォーマンスを達成するには依然として大きなギャップがあることが観察されています。この調査結果は、パフォーマンスを向上させるために、時間に関連するビデオ タスクをトレーニングにさらに組み込む必要性を浮き彫りにしています。
2 番目の戦略は VidLLM よりも優れており、将来の研究に有望な方向性を示しています。この戦略は主に、ビジュアル モデルとキュー ワードの設計の制限によって制限されるため、詳細で正確なビデオ説明を生成できるようになり、より洗練されたグラフィック モデルによって LLM の VG パフォーマンスが大幅に向上します。
 https://www.php.cn/link/a7fd9fd835f54f0f28003c679fd44b39
https://www.php.cn/link/a7fd9fd835f54f0f28003c679fd44b39
以上がビデオ タイミング ポジショニングにおいて清華大学が開発した LLM4VG ベンチマークのパフォーマンスを評価するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
声明:
この記事は51cto.comで複製されています。侵害がある場合は、admin@php.cn までご連絡ください。