###導入###
| コンテナは、初期の技術実験や概念実証から、開発、テスト、展開、サポートに至るまで、ソフトウェアのライフサイクル全体に革命をもたらしています。
|
###導入###
MongoDB をラップトップで試してみませんか?コマンドを実行するだけで、軽量で自己完結型のサンドボックスが完成します。完了したら、行った操作の痕跡をすべて削除できます。
同じアプリケーション スタック コピーを複数の環境で使用したいですか?独自のコンテナ イメージを構築し、開発、テスト、運用、サポート チームが同じ環境クローンを使用できるようにします。
コンテナは、初期の技術実験や概念実証から、開発、テスト、展開、サポートに至るまで、ソフトウェアのライフサイクル全体に革命をもたらしています。
オーケストレーション ツールは、複数のコンテナーを作成、アップグレードし、コンテナーの可用性を高める方法を管理するために使用されます。オーケストレーションは、複数のマイクロサービス コンテナーから複雑なアプリケーションを構築するためにコンテナーを接続する方法も制御します。
豊富な機能、シンプルなツール、強力な API により、コンテナとオーケストレーション機能は、継続的インテグレーション (CI) および継続的デリバリー (CD) ワークフローに統合する DevOps チームにとっての最初の選択肢となります。
この記事では、コンテナー内で MongoDB を実行およびオーケストレーションするときに遭遇する追加の課題を検討し、それらを克服する方法について説明します。
MongoDB に関する注意事項
コンテナとオーケストレーションを使用して MongoDB を実行する場合は、さらにいくつかの考慮事項があります。
MongoDB データベース ノードはステートフルです。コンテナーに障害が発生して再スケジュールされると、データが失われます (レプリカ セット内の他のノードから復元できますが、時間がかかります)。これは望ましくないことです。この問題を解決するには、Kubernetes のボリューム抽象化などの機能を使用して、コンテナ内の一時的な MongoDB データ ディレクトリを永続的な場所にマップし、コンテナの障害やプロセスの再スケジュールに耐えられるようにデータを保存できます。
レプリカ セット内の MongoDB データベース ノードは、再スケジュール後も含めて相互に通信できる必要があります。レプリカ セット内のすべてのノードは、すべてのピアのアドレスを知っている必要がありますが、コンテナーが再スケジュールされると、別の IP アドレスで再起動される可能性があります。たとえば、Kubernetes ポッド内のすべてのコンテナは IP アドレスを共有し、ポッドが再オーケストレーションされると、IP アドレスが変更されます。 Kubernetes では、これは Kubernetes サービスを各 MongoDB ノードに関連付けることによって処理され、Kubernetes DNS サービスを使用して「ホスト名」を提供し、再オーケストレーション間でサービスを変更しないようにします。
個々の MongoDB ノードが (それぞれ独自のコンテナー内で) 実行されたら、レプリカ セットを初期化し、各ノードをレプリカ セットに追加する必要があります。これには、オーケストレーション ツールの外部で追加の処理が必要になる場合があります。具体的には、ターゲット レプリカ セット内の MongoDB ノードを使用して、rs.initiate および rs.add コマンドを実行する必要があります。
オーケストレーション フレームワークがコンテナー (Kubernetes など) の自動再オーケストレーションを提供する場合、失敗したレプリカ セット メンバーが自動的に再作成され、人間の介入なしで完全な冗長レベルを復元できるため、MongoDB の回復力が向上します。
オーケストレーション フレームワークはコンテナーのステータスを監視する可能性がありますが、コンテナー内で実行されているアプリケーションを監視したり、そのデータをバックアップしたりする可能性は低いことに注意してください。これは、MongoDB Enterprise Advanced や MongoDB Professional に含まれる MongoDB Cloud Manager のような強力な監視およびバックアップ ソリューションを使用することが重要であることを意味します。好みの MongoDB バージョンと MongoDB Automation Agent を含む独自のイメージを作成することを検討してください。
Docker と Kubernetes を使用して MongoDB レプリカ セットを実装する
前のセクションで説明したように、分散データベース (MongoDB など) をオーケストレーション フレームワーク (Kubernetes など) を使用してデプロイする場合は、ある程度の注意が必要です。このセクションでは、これを実現する方法について詳しく説明します。
まず、MongoDB レプリカ セット全体を単一の Kubernetes クラスター内に作成します (通常はデータ センター内にあり、明らかに地理的な冗長性が提供されません)。実際には、複数のクラスターにわたって実行するために変更が必要になることはほとんどありません。これらの手順については後で説明します。
レプリカ セットの各メンバーは独自のポッドとして実行され、公開された IP アドレスとポートを使用してサービスを提供します。この「固定」IP アドレスは、外部アプリケーションと他のレプリカ セット メンバーの両方がポッドの再スケジュールの際に変更されないままであることを信頼できるため、重要です。
次の図は、ポッドの 1 つと、関連するレプリケーション コントローラーおよびサービスを示しています。
 図 1: Kubernetes ポッドとして構成され、サービスとして公開される MongoDB レプリカ セットのメンバー
図 1: Kubernetes ポッドとして構成され、サービスとして公開される MongoDB レプリカ セットのメンバー
図 1: MongoDB レプリカ セットのメンバーが Kubernetes ポッドとして構成され、サービスとして公開される
この構成で説明されているリソースをステップ実行します:
コアから始めると、mongo-node1 という名前のコンテナーがあります。 mongo-node1 には mongo という名前のイメージが含まれています。これは、Docker Hub でホストされている公開されている MongoDB コンテナー イメージです。コンテナーはクラスター内のポート 27107 を公開します。
Kubernetes のデータ ボリューム機能は、コネクタの /data/db ディレクトリを mongo-persistent-storage1 という名前の永続ストレージにマッピングするために使用されます。この永続ストレージは、Google Cloud で作成された mongodb-disk1 という名前のディスクにマッピングされます。これは、MongoDB がデータを保存する場所であり、コンテナーが再オーケストレーションされた後もデータが保持されます。
コンテナーは、 mongo-node という名前のラベルと、 rob という名前の (任意の) サンプルを持つポッド内に保持されます。
mongo-node1 ポッドの単一インスタンスが常に実行されるように、mongo-node1 レプリケーション コントローラーを構成します。
mongo-svc-a という名前の負荷分散サービスは、コンテナーの同じポート番号にマッピングされている IP アドレスとポート 27017 を外部に開きます。サービスはセレクターを使用してポッド ラベルを照合し、正しいポッドを決定します。外部 IP アドレスとポートは、アプリケーションとレプリカ セット メンバー間の通信に使用されます。各コンテナーにもローカル IP アドレスがありますが、コンテナーが移動または再起動されると、これらの IP アドレスは変更されるため、レプリカ セットには使用されません。
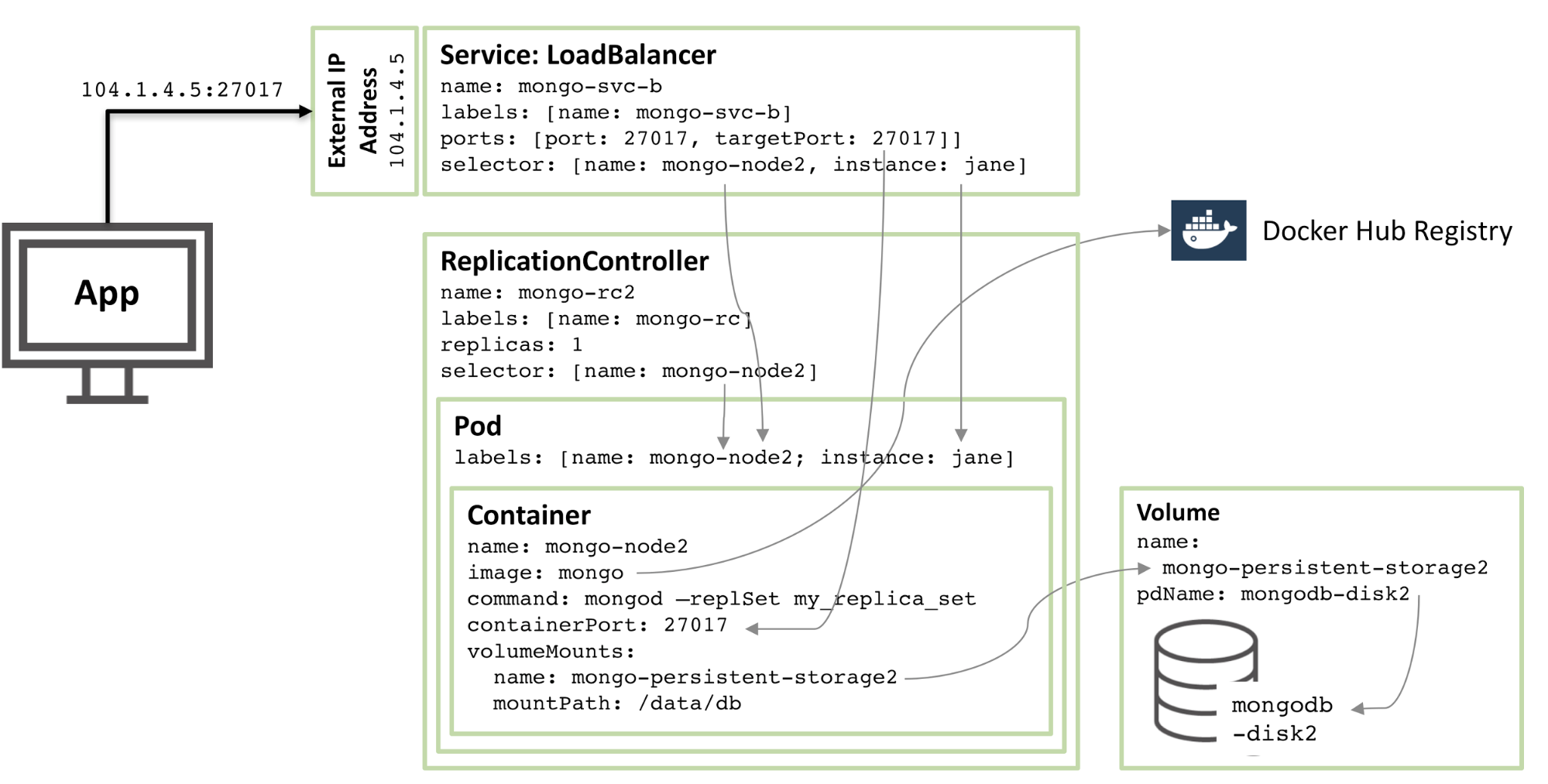
次の図は、レプリカ セットの 2 番目のメンバーの構成を示しています。
図 2: Kubernetes ポッドとして構成された 2 番目の MongoDB レプリカ セット メンバー
図 2: Kubernetes ポッドとして構成された 2 番目の MongoDB レプリカ セット メンバー
構成の 90% は同じですが、次の変更のみがあります:
ディスク名とボリューム名は一意である必要があるため、mongodb-disk2 と mongo-persistent-storage2 が使用されます
ポッドには、インスタンス: jane および名前: mongo-node2 というラベルが割り当てられ、セレクターを使用して新しいサービスを図 1 に示すロッド ポッドと区別できるようにします。
レプリケーション コントローラーの名前は mongo-rc2
です。
サービスの名前は mongo-svc-b で、一意の外部 IP アドレスが割り当てられます (この場合、Kubernetes は 104.1.4.5 を割り当てます)
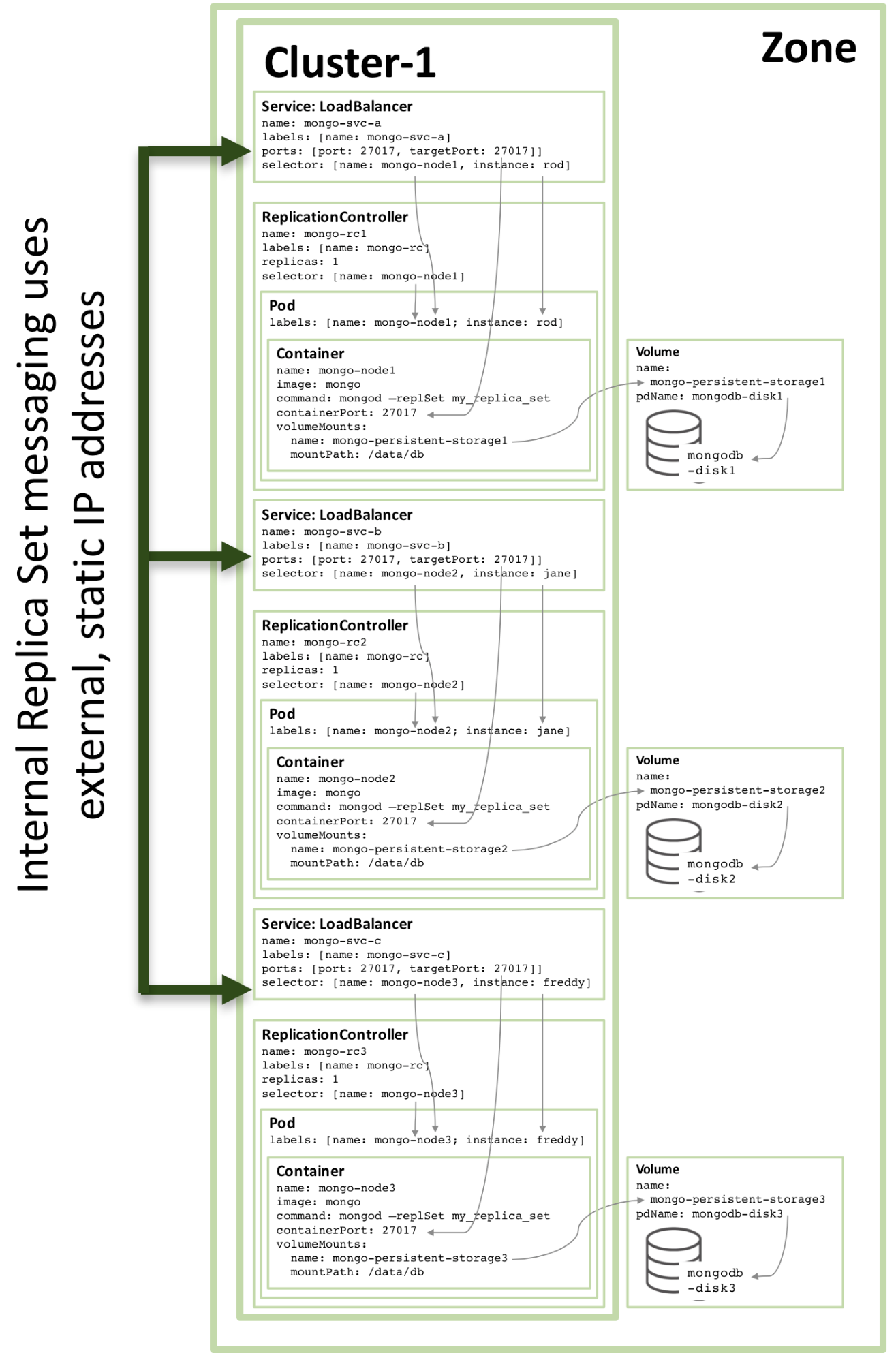
3 番目のレプリカ メンバーの構成も同じパターンに従い、次の図は完全なレプリカ セットを示しています。
図 3: Kubernetes サービスとして構成された完全なレプリカ セット メンバー
図 3: Kubernetes サービスとして構成された完全なレプリカ セット メンバー
図 3 に示す構成を 3 ノード以上の Kubernetes クラスターで実行している場合でも、Kubernetes は同じホスト上の 2 つ以上の MongoDB レプリカ セット メンバーをオーケストレーションする場合があります (実際にオーケストレーションする場合もよくあります)。これは、Kubernetes が 3 つのポッドを 3 つの別個のサービスに属しているものとして扱うためです。
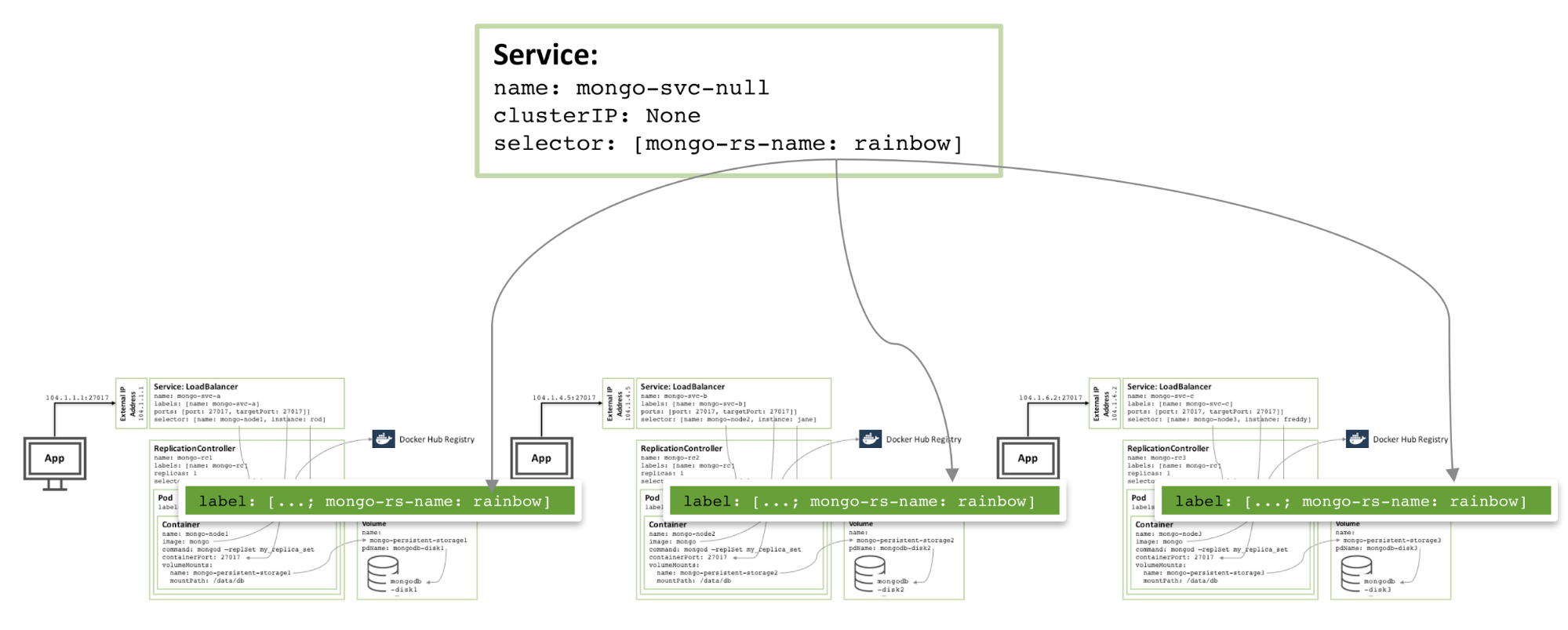
ゾーン内に冗長性を追加するには、追加のヘッドレス サービスを作成できます。新しいサービスは外部に機能を提供しません (IP アドレスさえありません) が、Kubernetes が 3 つの MongoDB ポッドにサービスを形成するように通知できるため、Kubernetes はそれらを異なるノード上でオーケストレーションしようとします。
図 4: 同じ MongoDB レプリカ セットのメンバーに対するヘッドレス サービスの回避
図 4: 同じ MongoDB レプリカ セットのメンバーを回避するヘッドレス サービス
MongoDB レプリカ セットの構成と起動に必要な実際の構成ファイルとコマンドは、ホワイト ペーパー「Enabling Microservices: Elucidating Containers and Orchestration」に記載されています。特に、この記事で説明されている特別な手順の一部は、3 つの MongoDB インスタンスを機能的で堅牢なレプリカ セットに結合するために必要です。
複数の可用性ゾーン MongoDB レプリカ セット
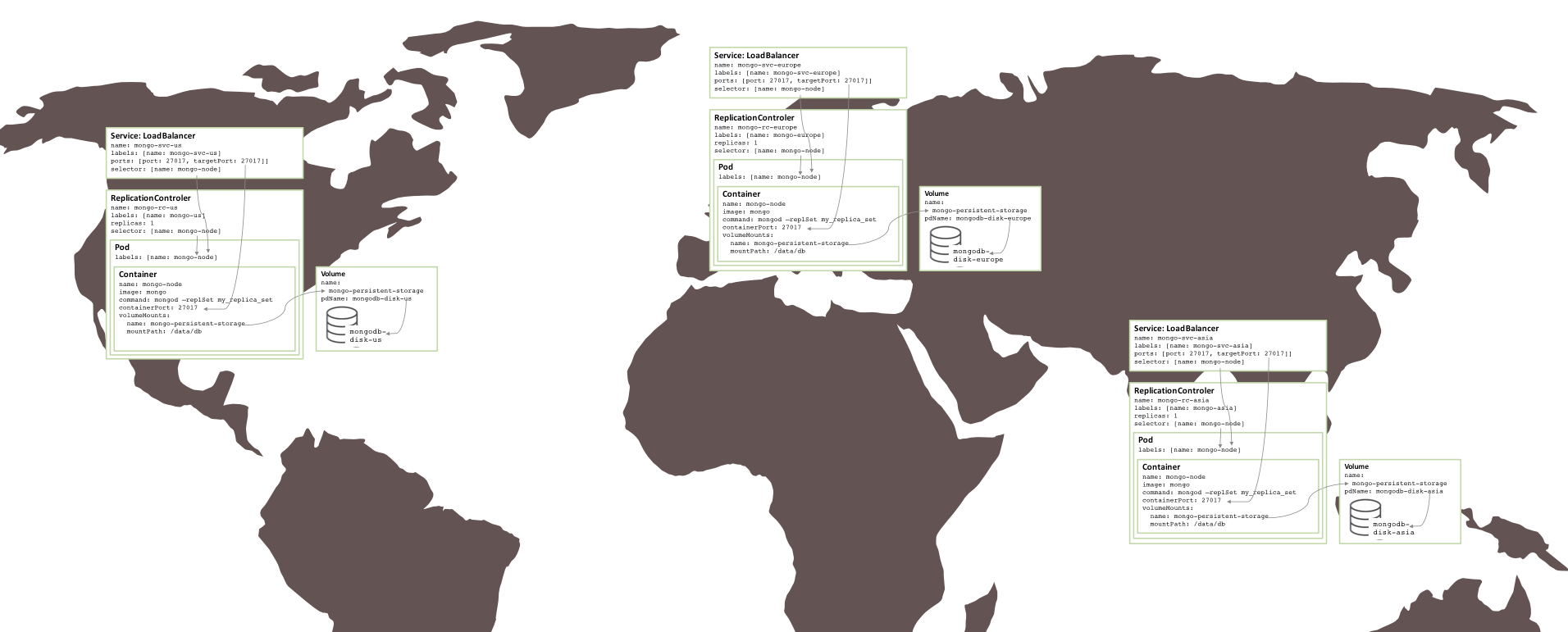
上で作成したレプリカ セットは、すべてが同じ GCE クラスター内、つまり同じアベイラビリティ ゾーン内で実行されているため、危険です。重大なイベントによりアベイラビリティーゾーンがオフラインになると、MongoDB レプリカセットは使用できなくなります。地理的な冗長性が必要な場合は、3 つのポッドを 3 つの異なるアベイラビリティーゾーンまたはリージョンで実行する必要があります。
驚くべきことに、3 つのリージョン (3 つのクラスターが必要) に分割された同様のレプリカ セットを作成するために必要な変更はほとんどありませんでした。各クラスターには、そのレプリカ セットの 1 つのメンバーのみのポッド、レプリケーション コントローラー、およびサービスを定義する独自の Kubernetes YAML ファイルが必要です。その後、各リージョンにクラスター、永続ストレージ、MongoDB ノードを作成するのは簡単です。
図 5: 複数のアベイラビリティ ゾーンで実行されるレプリカ セット
図 5: 複数のアベイラビリティ ゾーンで実行されるレプリカ セット
次のステップ###
コンテナとオーケストレーション (関連するテクノロジとそれらが提供するビジネス上の利点) について詳しくは、ホワイト ペーパー「マイクロサービスの有効化: コンテナとオーケストレーションの説明」を参照してください。このドキュメントでは、この記事で説明されているレプリカ セットを取得し、それを Google Container Engine の Docker および Kubernetes で実行するための完全な手順を説明します。
###著者について:###
Andrew は、MongoDB の製品マーケティング担当ゼネラル マネージャーです。昨年の夏に Oracle から MongoDB に入社し、高可用性を中心とした製品管理に 6 年以上携わってきました。 @andrewmorgan に連絡するか、彼のブログ (clusterdb.com) にコメントすることで連絡できます。


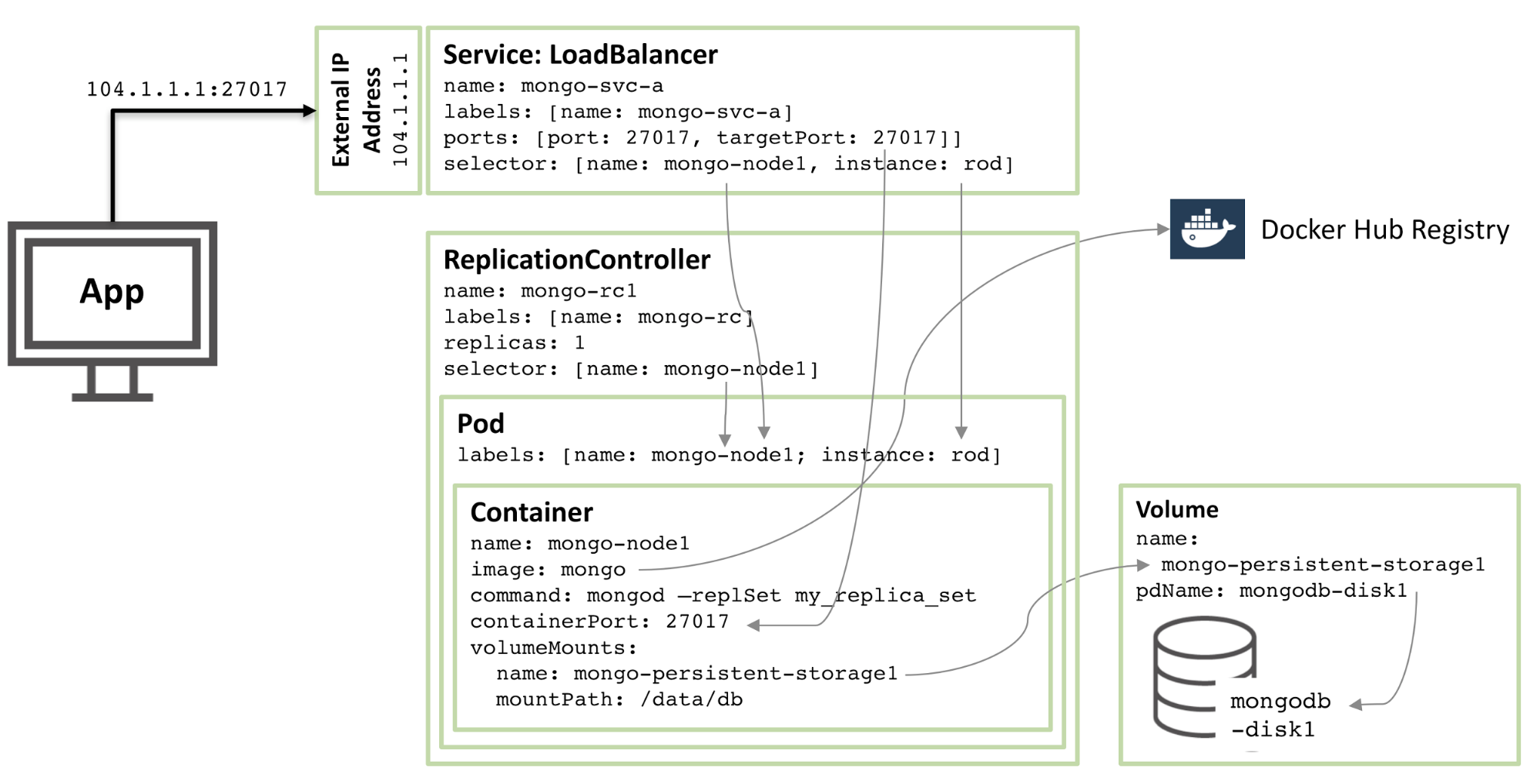 図 1: Kubernetes ポッドとして構成され、サービスとして公開される MongoDB レプリカ セットのメンバー
図 1: Kubernetes ポッドとして構成され、サービスとして公開される MongoDB レプリカ セットのメンバー