###導入###
| この記事では、リカレント ニューラル ネットワーク RNN の開発プロセスを簡単に紹介し、勾配降下アルゴリズム、バックプロパゲーション、LSTM プロセスを分析します。
|
科学技術の発展とハードウェア コンピューティング能力の大幅な向上に伴い、人工知能は数十年にわたる舞台裏の仕事から突然人々の目に飛び込んできました。人工知能のバックボーンは、ビッグデータ、高性能ハードウェア、優れたアルゴリズムのサポートから生まれます。 2016 年、Google 検索ではディープラーニングがホットワードとなり、ここ 1 ~ 2 年で AlphaGo が囲碁の人間対機械の戦いで世界チャンピオンを破ったことで、人々は AI の急速な進歩にもはや抵抗できないと感じています。 2017年、AIは飛躍的な進歩を遂げ、知能ロボット、無人運転車、音声検索などの関連製品も人々の生活に登場しました。最近、天津で世界知能会議が成功裡に開催され、会議では多くの業界専門家や起業家が将来についての見解を表明し、ほとんどのテクノロジー企業や研究機関が人工知能の見通しについて非常に楽観的であることがわかりました。たとえば、Baidu will 彼の富はすべて人工知能にあります。彼が有名になろうが失敗しようが、結局何も得られない限り。なぜディープラーニングは突然これほど大きな影響を及ぼし、ブームになったのでしょうか?なぜなら、テクノロジーは生活を変え、将来的には多くの職業がゆっくりと人工知能に取って代わられる可能性があるからです。国民全体が人工知能とディープラーニングについて話しており、ヤン・ルクンも中国での人工知能の人気を実感しています!

より身近なところでは、人工知能の背後には、ビッグ データ、優れたアルゴリズム、強力なコンピューティング機能を備えたハードウェア サポートがあります。たとえば、NVIDIA は、強力なハードウェア研究開発能力と深層学習フレームワークのサポートにより、世界で最も賢い企業 50 社の中で第 1 位にランクされています。また、ディープラーニングのアルゴリズムには優れたものが多く、時々新しいアルゴリズムが登場するので、本当に目まぐるしいです。しかし、それらのほとんどは、畳み込みニューラル ネットワーク (CNN)、ディープ ビリーフ ネットワーク (DBN)、リカレント ニューラル ネットワーク (RNN) などの古典的なアルゴリズムに基づいて改良されています。
この記事では、時系列データに推奨されるネットワークでもある、古典的なネットワークであるリカレント ニューラル ネットワーク (RNN) を紹介します。特定の連続的な機械学習タスクに関しては、RNN は他のアルゴリズムが競合できない非常に高い精度を達成できます。これは、従来のニューラル ネットワークには短期記憶しかないのに対し、RNN には短期記憶が限られているという利点があるためです。しかし、研究者らがバックプロパゲーションや勾配降下法アルゴリズムを使用する際に深刻な勾配消失問題に悩まされ、数十年にわたって RNN の開発が妨げられていたため、第 1 世代の RNN ネットワークはあまり注目を集めませんでした。最後に、1990 年代後半に大きな進歩が起こり、より正確な新世代の RNN が誕生しました。その画期的な進歩を基にしてから 20 年近くが経ち、開発者たちは新世代の RNN を完成させ、最適化しましたが、Google 音声検索や Apple Siri などのアプリがその主要なプロセスを横取りし始めました。現在、RNN ネットワークはあらゆる研究分野に広がり、人工知能のルネッサンスの火付け役となっています。
過去関連ニューラルネットワーク (RNN)
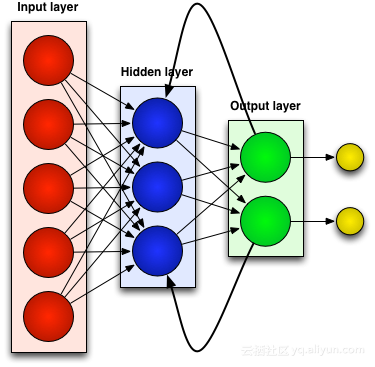
フィードフォワード ニューラル ネットワークなどのほとんどの人工ニューラル ネットワークは、受け取った入力を覚えていません。たとえば、フィードフォワード ニューラル ネットワークに文字「WISDOM」が入力された場合、文字「D」に到達するまでに、文字「S」を読み取ったばかりであることを忘れてしまいます。これは大きな問題です。ネットワークがどれほど入念にトレーニングされたとしても、次に可能性の高い文字「O」を推測することは常に困難でした。このため、音声認識などの特定のタスクでは、次の文字を予測する能力によって認識の品質が大きく左右されるため、これはかなり役に立たない候補になります。一方、RNN ネットワークは以前の入力を記憶しますが、そのレベルは非常に洗練されています。
再度「WISDOM」を入力してリカレントネットワークに適用します。 RNN ネットワーク内のユニットまたは人工ニューロンは、「D」を受信すると、以前に受信した文字「S」も入力として受け取ります。言い換えれば、過去の出来事と現在の出来事を組み合わせて、次に何が起こるかを予測するための入力として使用するため、短期記憶が限られているという利点が得られます。トレーニング時に、十分なコンテキストがあれば、次の文字は「O」である可能性が最も高いと推測できます。
調整と再調整
すべての人工ニューラル ネットワークと同様に、RNN ユニットは複数の入力に重み行列を割り当てます。これらの重みはネットワーク層の各入力の割合を表します。その後、関数がこれらの重みに適用されて単一の出力が決定されます。この関数はは一般に損失関数(コスト関数)と呼ばれ、実際の出力と目標出力の間の誤差を制限します。ただし、RNN は現在の入力に重みを割り当てるだけでなく、過去の瞬間からの入力にも重みを割り当てます。次に、現在の入力と過去の入力に割り当てられた重みは、損失関数を最小化することによって動的に調整されます。このプロセスには、勾配降下法と逆伝播 (BPTT) という 2 つの重要な概念が含まれます。
勾配降下法
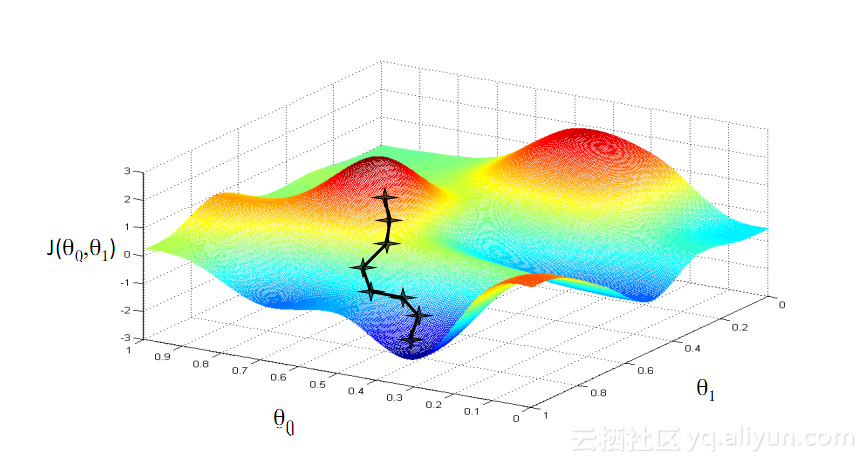
機械学習で最も有名なアルゴリズムの 1 つは、勾配降下法アルゴリズムです。その主な利点は、「次元の呪い」を大幅に回避できることです。 「次元の呪い」とは? ベクトルを含む計算問題では、次元数が増えると計算量が指数関数的に増加することを意味します。最小の損失関数を達成するにはあまりにも多くの変数を計算する必要があるため、この問題は多くのニューラル ネットワーク システムを悩ませています。ただし、勾配降下アルゴリズムは、コスト関数の多次元誤差または極小値を増幅することにより、次元の呪いを打ち破ります。これは、システムが個々のユニットに割り当てられた重み値を調整してネットワークをより正確にするのに役立ちます。
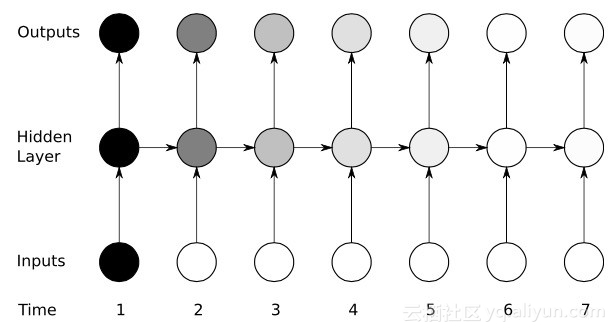
時間によるバックプロパゲーション
RNN は、後方推論を通じて重みを微調整することでユニットをトレーニングします。簡単に言うと、ユニットで計算された合計出力と目標出力との誤差に基づいて、ネットワークの最終出力端から層ごとに逆回帰が実行され、損失関数の偏導関数を使用して調整されます。各ユニットの重量。これは有名な BP アルゴリズムです。BP アルゴリズムについては、このブロガーの以前の関連ブログを参照してください。 RNN ネットワークは、時間逆伝播 (BPTT) と呼ばれる同様のバージョンを使用します。このバージョンでは、調整プロセスを拡張して、前回 (T-1) の入力値に対応する各ユニットのメモリを担当する重みを含めます。
やあ: 勾配消失問題
勾配降下アルゴリズムと BPTT の助けを借りて初期の成功を収めたにもかかわらず、多くの人工ニューラル ネットワーク (第一世代 RNN ネットワークを含む) は最終的に、勾配消失問題という深刻な後退に見舞われました。勾配消失問題とは何ですか? 基本的な考え方は実際には非常に単純です。まず、勾配を勾配と考えて、勾配の概念を見てみましょう。ディープ ニューラル ネットワークのトレーニングのコンテキストでは、勾配の値が大きいほど傾斜が急であることを表し、システムがフィニッシュ ラインに到達してトレーニングを完了するまでの速度が速くなります。しかし、ここで研究者たちは問題に遭遇しました。斜面が平坦すぎると高速トレーニングは不可能でした。最初の層の勾配値がゼロの場合、調整方向がなく、損失関数を最小限に抑えるために関連する重み値を調整できないことを意味するため、これは深いネットワークの最初の層にとって特に重要です。この現象を「消去」、「勾配損失」といいます。勾配がどんどん小さくなるにつれて、トレーニング時間はますます長くなり、物理学の直線運動と同様に、ボールは滑らかな表面上を動き続けます。
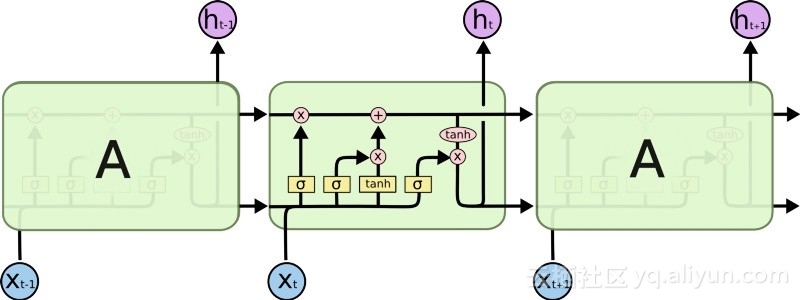
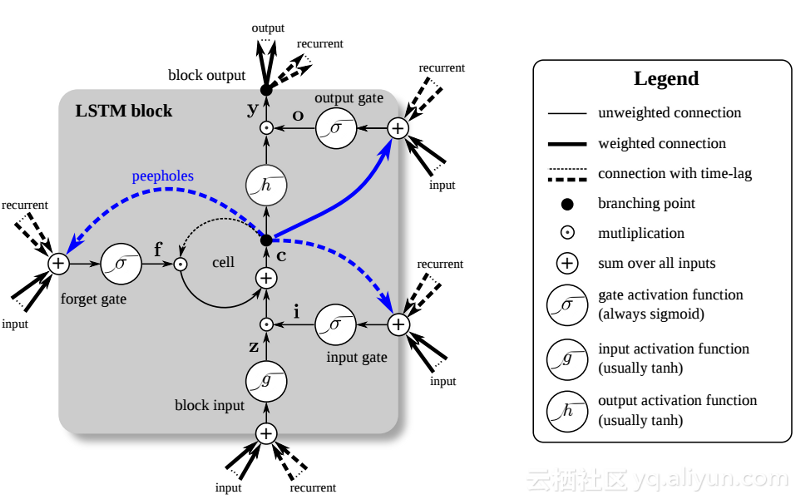
大きな進歩: 長短期記憶 (LSTM)
1990 年代後半、大きな進歩により前述の勾配消失問題が解決され、RNN ネットワークの開発に第 2 の研究ブームがもたらされました。この大きな進歩の中心となるアイデアは、単位長短期記憶 (LSTM) の導入です。
LSTM の導入により、AI 分野に別の世界が生まれました。これは、これらの新しいユニットまたは人工ニューロン (RNN の標準的な短期記憶ユニットなど) が最初から入力を記憶しているという事実によるものです。ただし、標準の RNN セルとは異なり、LSTM はメモリ上に取り付けることができ、通常のコンピュータのメモリ レジスタと同様の読み取り/書き込み特性を備えています。さらに、LSTM はデジタルではなくアナログであるため、その機能が区別できます。つまり、曲線が連続しており、斜面の急峻さが分かります。したがって、LSTM は、バックプロパゲーションと勾配降下法に関係する部分計算に特に適しています。
要約すると、LSTM は重みを調整できるだけでなく、トレーニングの勾配に基づいて、保存されたデータの流入と流出を保持、削除、変換、制御することもできます。最も重要なことは、LSTM は重要なエラー情報を長期間保存できるため、勾配が比較的急で、ネットワークのトレーニング時間が比較的短くなります。これにより、勾配消失の問題が解決され、今日の LSTM ベースの RNN ネットワークの精度が大幅に向上します。 RNN アーキテクチャの大幅な改善により、Google、Apple、その他多くの先進企業は現在、RNN を使用してビジネスの中心となるアプリケーションを強化しています。
要約
リカレント ニューラル ネットワーク (RNN) は以前の入力を記憶できるため、音声認識などの継続的なコンテキスト依存タスクに関しては、他の人工ニューラル ネットワークよりも大きな利点があります。
RNN ネットワークの開発の歴史について: 第 1 世代の RNN は、バックプロパゲーションと勾配降下アルゴリズムを通じてエラーを修正する機能を実現しました。しかし、勾配消失問題が RNN の開発を妨げ、LSTM ベースのアーキテクチャの導入後に大きな進歩が達成されたのは 1997 年のことでした。
新しい方法は、RNN ネットワーク内の各ユニットを効果的にアナログ コンピューターに変え、ネットワークの精度を大幅に向上させます。
著者情報
Jason Roell: ディープラーニングと革新的なテクノロジーへのその応用に情熱を注ぐソフトウェア エンジニア。
Linkedin: http://www.linkedin.com/in/jason-roell-47830817/