###導入###
| 最近、ログのリアルタイム同期を行っています。オンラインにする前に、オンライン ログ ストレス テストを 1 回だけ実行しました。メッセージ キュー、クライアント、ローカル マシンには問題はありませんでしたが、 2 番目のログがアップロードされた後、次のような質問が来るとは予想していませんでした:
|
1.質問:
クラスタ最上位の特定のマシンに大きな負荷が発生しました。クラスタ内の各マシンのハードウェア構成は同じで、導入されているソフトウェアも同じですが、この1台のマシンのみ負荷に問題がありました。最初はハードウェアに問題があるのではないかと思いました。
同時に、異常な負荷の原因を突き止め、ソフトウェアおよびハードウェアレベルからの解決策を見つける必要もあります。

2. トラブルシューティング:
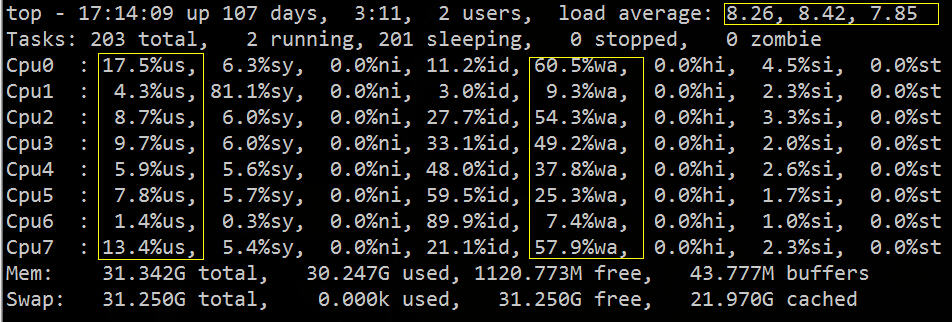
上から見ると、負荷平均が高く、%wa が高く、%us が低いことがわかります。
上の図から、IO にボトルネックが発生していると大まかに推測できます。次に、関連する IO 診断ツールを使用して、特定の検証とトラブルシューティングを行うことができます。
一般的に使用される組み合わせ方法は次のとおりです。
•vmstat、sar、iostat を使用して、CPU ボトルネックかどうかを検出します
•free と vmstat を使用してメモリのボトルネックがあるかどうかを検出します
•iostat と dmesg を使用して、ディスク I/O ボトルネックかどうかを検出します
•netstatを使用してネットワーク帯域幅のボトルネックを検出する
2.1 vmstat
vmstat コマンドの意味は、仮想メモリのステータス (「仮想メモリ統計」) を表示することですが、プロセス、メモリ、I/O などのシステム全体の動作ステータスをレポートすることもできます。
関連フィールドは次のように説明されます:
プロセス(プロセス)
•r: 実行キュー内のプロセスの数 この値は、CPU を増やす必要があるかどうかを判断するためにも使用できます。 (1 を超える長期)
• b:IO 待ちプロセス数、つまり無割り込みスリープ状態のプロセス数。実行中で CPU リソースを待っているタスクの数を示します。この値が CPU の数を超えると、CPU ボトルネックが発生します。
###メモリ###
•swpd: 仮想メモリ サイズを使用する swpd の値が 0 ではなくても、SI と SO の値が長時間 0 である場合、この状況はシステム パフォーマンスに影響を与えません。
•free: 空き物理メモリのサイズ。
•buff: バッファとして使用されるメモリのサイズ。
•cache: キャッシュとして使用されるメモリ サイズ。キャッシュ値が大きい場合は、キャッシュ内に多くのファイルが存在することを意味します。頻繁にアクセスされるファイルをキャッシュできれば、ディスクの読み取り IO Bi は非常に小さくなります。
Swap(スワップエリア)
•si: ディスクからメモリに転送される、1 秒当たりのスワップ領域からメモリへの書き込みサイズ。
•so: メモリからディスクに転送される、1 秒あたりにスワップ領域に書き込まれるメモリ サイズ。
注: メモリが十分な場合、これら 2 つの値は両方とも 0 になります。これら 2 つの値が長時間 0 より大きい場合、システムのパフォーマンスに影響があり、ディスク IO と CPUリソースが消費されてしまいます。空きメモリ (free) が非常に少ない、または 0 に近いのを見て、メモリが足りないと考える友人もいます。これだけを見るだけでなく、si などを組み合わせることもできます。空きが非常に少ない場合は、 si なども非常に少ないので (ほとんどの場合は 0)、現時点ではシステムのパフォーマンスには影響しませんので、ご心配なく。
IO (入力および出力)
(現在の Linux バージョンのブロック サイズは 1kb)
•bi: 1 秒あたりに読み取られるブロック数
•bo: 1 秒あたりに書き込まれるブロック数
注: ランダム ディスクの読み取りおよび書き込みを行う場合、これら 2 つの値が大きいほど (1024k を超えるなど)、CPU が IO を待機していることがわかります。
###システム###
•in: クロック割り込みを含む、1 秒あたりの割り込み数。
•cs: 1 秒あたりのコンテキスト スイッチの数。
注: 上記 2 つの値が大きいほど、カーネルによって消費される CPU 時間も長くなります。
###CPU###
(パーセンテージで表現)
・us:ユーザープロセスの実行時間(ユーザー時間)の割合。 us の値が比較的高い場合は、ユーザープロセスが CPU 時間を多く消費していることを意味しますが、使用率が 50% を超える状態が長時間続く場合は、プログラムのアルゴリズムの最適化や高速化を検討する必要があります。
・sy: カーネルシステムプロセスの実行時間(システム時間)の割合。 sy の値が高い場合、システム カーネルが CPU リソースを大量に消費していることを意味しますが、これは良好なパフォーマンスではないため、その理由を確認する必要があります。
•wa: IO 待ち時間の割合。 wa の値が大きい場合は IO 待ちが深刻であることを意味しており、ディスクへのランダムアクセスが多いか、ディスクにボトルネック (ブロック操作) が発生している可能性があります。
•id: アイドル時間のパーセンテージ
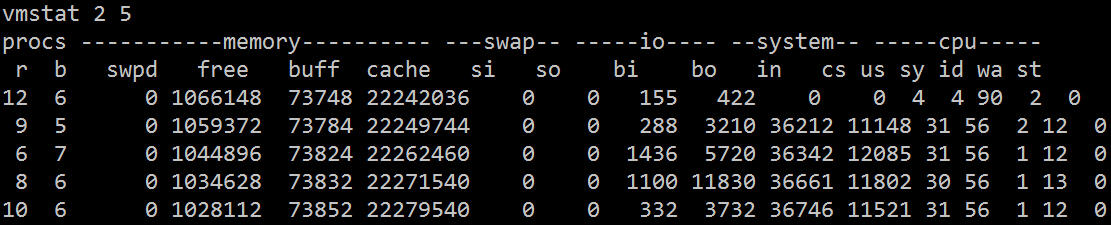
vmstat からわかるように、CPU の時間のほとんどは IO の待機に無駄になっています。これは、多数のランダム ディスク アクセスまたはディスク帯域幅が原因である可能性があります。Bi と bo も 1024k を超えており、これは IO が原因であるはずです. ボトルネック。
2.2iostat
より専門的なディスク IO 診断ツールを使用して、関連する統計を見てみましょう。
それに関連するフィールドは次のように説明されます:
•rrqm/s: 1 秒あたりのマージ読み取り操作の数。それは delta(rmerge)/s
です。
•wrqm/s: 1 秒あたりのマージ書き込み操作の数。それは delta(wmerge)/s
です。
•r/s: 1 秒あたりに完了した I/O デバイスからの読み取り数。それはデルタ(リオ)/s
です
•w/s: 1 秒あたりに完了した I/O デバイスへの書き込み数。それはデルタ(wio)/s
です
•rsec/s: 1 秒あたりに読み取られるセクター数。それは delta(rsect)/s
です。
•wsec/s: 1 秒あたりに書き込まれるセクター数。それは delta(wsect)/s
です。
•rkB/s: 1 秒あたりに読み取られる K バイト。各セクターのサイズは 512 バイトであるため、rsect/s の半分になります。 (計算が必要)
•wkB/s: 1 秒あたりに書き込まれる K バイトの数。 wsect/s の半分です。 (計算が必要)
•avgrq-sz: デバイス I/O 操作あたりの平均データ サイズ (セクター)。デルタ(rsect wsect)/デルタ(rio wio)
•avgqu-sz: I/O キューの平均長。これは、delta(aveq)/s/1000 です (aveq の単位はミリ秒であるため)。
•await: 各デバイス I/O 操作の平均待機時間 (ミリ秒)。それは、デルタ(ルセ・ウセ)/デルタ(リオ・ウィオ)
です。
•svctm: 各デバイス I/O 操作の平均サービス時間 (ミリ秒)。それは、デルタ(使用)/デルタ(リオウィオ)
です。
•%util: I/O 操作に使用される秒数の割合、または I/O キューが空ではない秒数。つまり、delta(use)/s/1000 (使用単位がミリ秒であるため)
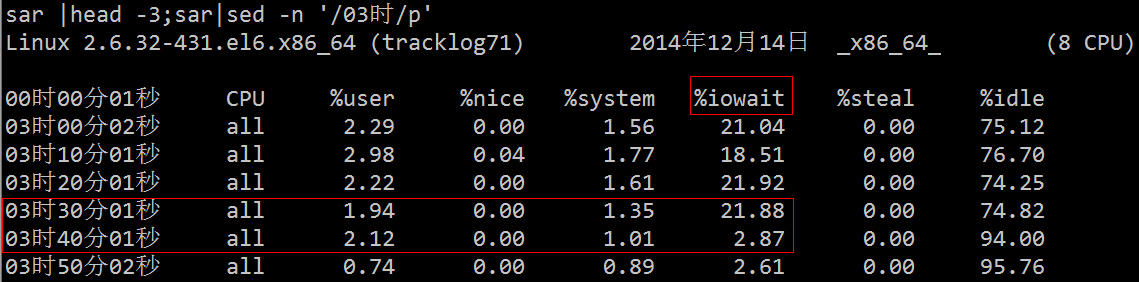
2 台のハードディスクの sdb の使用率が 100% であり、深刻な IO ボトルネックがあることがわかります。次のステップは、どのプロセスがこのハードディスクにデータを読み書きしているかを調べることです。
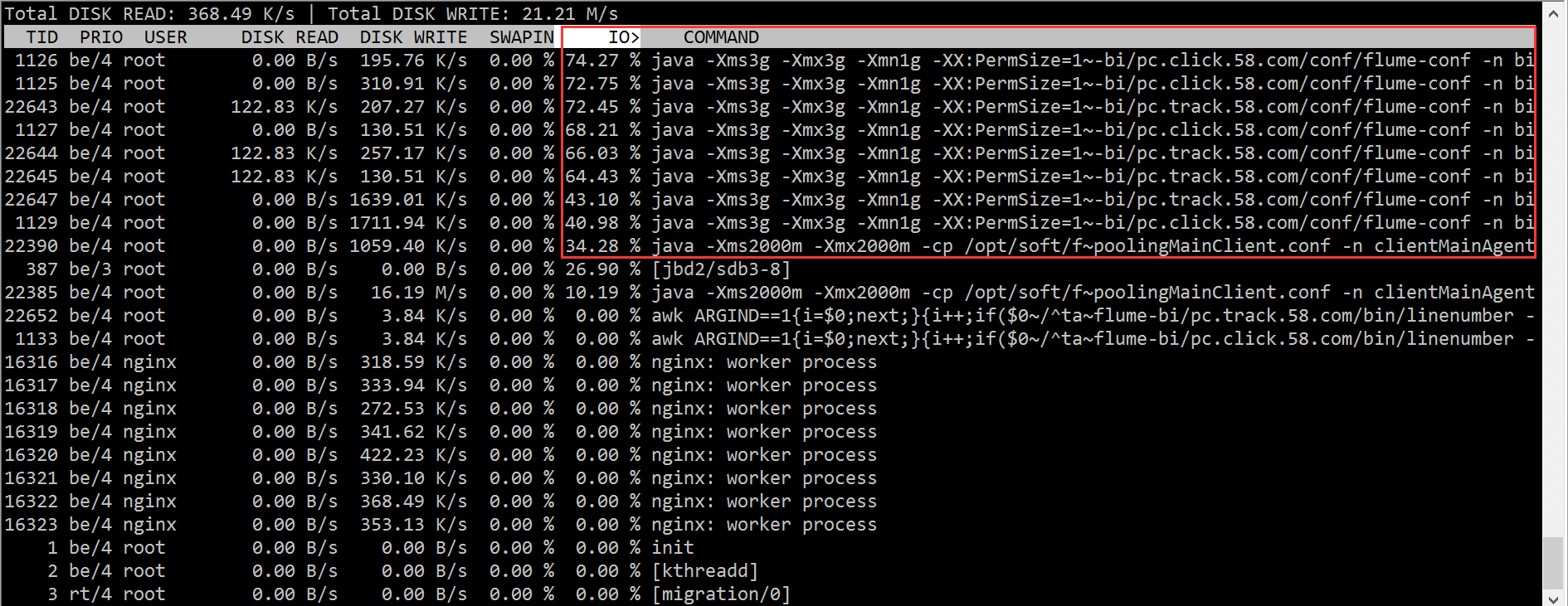
2.3iotop
iotop の結果によると、大量の IO 待機を引き起こした Flume プロセスの問題をすぐに特定しました。
しかし、最初に言ったように、クラスタ内のマシン構成は同じで、デプロイされたプログラムも rsync と全く同じなのですが、ハードディスクが壊れているのでしょうか?
これは、運用および保守の学生によって検証される必要があります。最終的な結論は次のとおりです:
Sdbはデュアルディスクraid1、使用したraidカードは「LSI Logic/Symbios Logic SAS1068E」、キャッシュはありません。 400 IOPS 近くの圧力がハードウェアの制限に達しました。他のマシンで使用されている RAID カードは「LSI Logic / Symbios Logic MegaRAID SAS 1078」で、256MB のキャッシュを備えており、ハードウェアのボトルネックには達していません。解決策は、より大きな IOPS のマシンに置き換えることです。 PERC6 /i 統合 RAID コントローラ カードを備えたマシンを搭載したマシンに接続します。 RAID 情報は RAID カードとディスクファームウェアに保存されていることに注意してください。ディスク上の RAID 情報と RAID カード上の情報形式が一致している必要があります。そうでない場合、RAID カードは認識できず、ディスクを再認識する必要があります。フォーマット済み。
IOPS は基本的にディスク自体に依存しますが、IOPS を向上させる方法は数多くあります。ハードウェア キャッシュの追加や RAID アレイの使用が一般的な方法です。 IOPS が高い DB のようなシナリオの場合、従来の機械式ハードディスクの代わりに SSD を使用することが現在一般的です。
しかし、前述したように、ソフトウェアとハードウェアの両方の側面から始める目的は、それぞれ最も安価なソリューションを見つけることができるかどうかを確認することです。
ハードウェアの理由がわかったので、読み取りおよび書き込み操作を別のディスクに移動して、その効果を確認してみましょう。
3. 最後の言葉: 別の方法を見つけてください
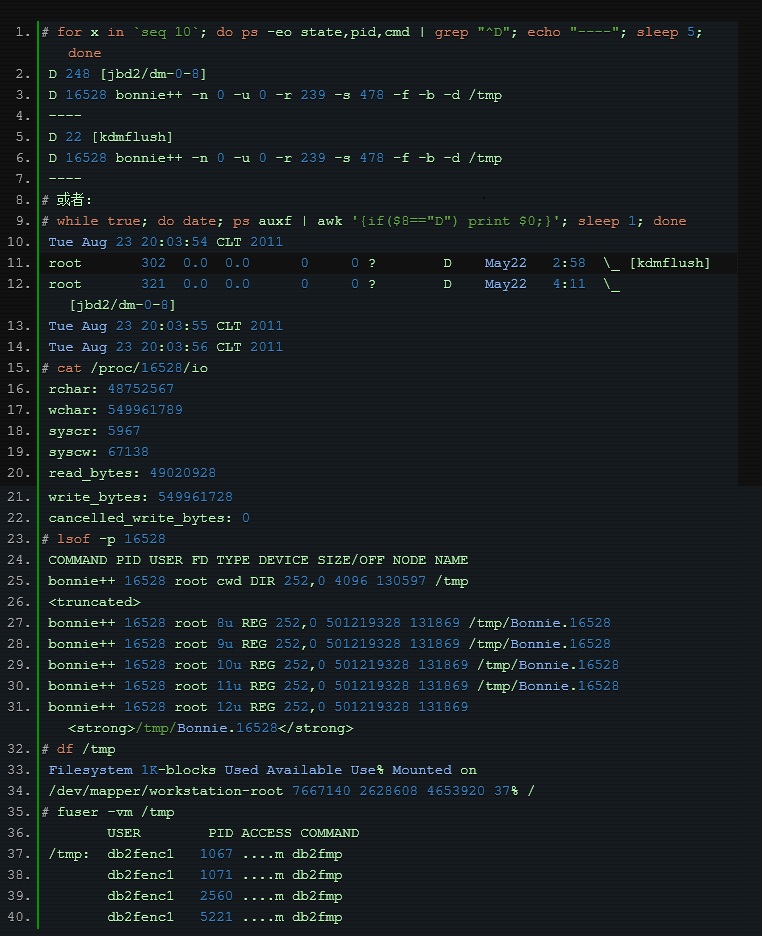
実際には、上記の専門ツールを使用してこの問題を特定することに加えて、プロセスのステータスを直接使用して関連するプロセスを見つけることができます。
プロセスには次の状態があることがわかっています:
•D 無中断スリープ (通常は IO)
•R 実行中または実行可能 (実行キュー上)
•S 割り込み可能なスリープ (イベントの完了を待機)
•T は、ジョブ制御信号またはトレース中により停止しました。
•W ページング (2.6.xx カーネル以降は無効)
•死亡したX人(決して見られるべきではない)
•Z の機能しない (「ゾンビ」) プロセス。終了しましたが、親によって取得されていません。
D の状態は、通常、待機 IO によって引き起こされる、いわゆる「中断不可能なスリープ」です。この点から開始して、段階的に問題を特定できます。