

CURL のメモリ割り当て操作を最適化する

今日、libcurl [1] 内にもう 1 つの小さな変更を加えて、malloc の実行を少なくしました。今回は、汎用リンク リスト関数がより少ない malloc に変換されます (リンク リスト関数は本来そうあるべきです)。
malloc を研究する数週間前、私はメモリ割り当てについて調べ始めました。私たちは何年にもわたってメモリのデバッグとログ システムをカールで使用してきたので、これは簡単です。デバッグ バージョンのカールを使用し、ビルド ディレクトリで次のスクリプトを実行します:
リーリーcurl 7.53.1 の場合、これは約 115 のメモリ割り当てになります。これは多すぎるのでしょうか、それとも少なすぎるのでしょうか?
メモリのロギングは非常に基本的なものです。アイデアを提供するために、サンプル スニペットを次に示します:
リーリー ログを確認する次に、ログをさらに詳しく調べたところ、同じコード行で多数の小さなメモリ割り当てが行われていることがわかりました。明らかに、構造体を割り当て、その構造体をリンク リストまたはハッシュに追加し、そのコードで別の小さな構造体を追加するという非常に愚かなコード パターンがあり、これをループで行うことがよくあります。 (私がここで言っているのは、私たちです。誰も責めているわけではありません。もちろん、責任のほとんどは私にあります...)
これら 2 つの割り当て操作は常にペアで表示され、同時に解放されます。私はこれらの問題を解決することにしました。非常に小さい (32 バイト未満) 割り当てを行うことも無駄です。なぜなら、その小さなメモリ領域を追跡するために (malloc システム内で) 大量のデータが使用されるからです。瓦礫の山は言うまでもありません。
したがって、malloc を使用しないようにハッシュとリンク リストのコードを修正することは、最も単純な "curl http://localhost" 転送で 20% 以上の malloc を削除する迅速かつ簡単な方法です。
この時点で、すべてのメモリ割り当て操作をサイズ順に並べ替え、最小の割り当て操作をすべてチェックします。顕著な部分は curl_multi_wait() にあります。これは通常、メインの CURL 転送ループで繰り返し呼び出される関数です。ほとんどの典型的なケースでは、これをスタック [2] を使用するように変換します。関数呼び出しを何度も繰り返す場合は、malloc を避けるのが得策です。
再集計上記のスクリプトに示すように、同じ curl localhost コマンドは、curl 7.53.1 では 115 件の割り当て操作から、何も犠牲にすることなく 80 件の割り当て操作に減少しました。簡単に 26% 改善されます。悪くない、全く!
curl_multi_wait() を変更したので、もう少し高度な転送が実際にどのように改善されるのかも確認したいと思いました。 multi-double.c[3] サンプル コードを使用し、メモリ レコードを初期化する呼び出しを追加し、curl_multi_wait() を使用させ、2 つの URL を並行してダウンロードしました。 ## リーリー
2 番目のファイルは 512 メガバイトのゼロで、最初のファイルは 600 バイトのパブリック HTML ページです。これは count-malloc.c コード[4] です。
まず、7.53.1 を使用して上記の例をテストし、memanalyze スクリプトを使用してチェックしました。 リーリー わかりました。合計 160KB のメモリが使用され、33900 回以上割り当てられました。また、512 メガバイトを超えるデータをダウンロードするため、15 KB のデータごとに malloc が存在します。良いのか悪いのか?
git master に戻りますが、現在はバージョン 7.54.1-DEV です。次のバージョンをリリースするときのバージョン番号がどのようになるかはまったくわかりません。 7.54.1 または 7.55.0 である可能性がありますが、まだ確認されていません。話がそれましたが、同じ変更を加えた multi-double.c の例を再度実行し、メモリ ログに対して memanalyze を再度実行すると、次のようなレポートが得られます。 リーリー
信じられない気持ちで二度見してしまいました。どうしたの?再確認するには、もう一度実行した方がよいでしょう。何度実行しても結果は同じです。33961 vs 129
一般的な転送では、curl_multi_wait() が何度も呼び出され、転送中に少なくとも 1 つの通常のメモリ割り当て操作が実行されるため、その 1 つの小さな割り当て操作を削除すると、カウンターに非常に大きな影響を与えます。インパクト。通常の転送では、リンク リストの内外へのデータの移動やハッシュ操作も行われますが、現在ではほとんど malloc も含まれていません。簡単に言えば、残りの割り当て操作は転送ループでは実行されないため、ほとんど重要ではありません。
前のカールでは、現在の例の 263 倍の操作数が割り当てられました。言い換えれば、新しいものは古いものの割り当て操作の数の 0.37% です。
另外还有一点好处,新的内存分配量更少,总共减少了 7KB(4.3%)。
malloc 重要吗?在几个 G 内存的时代里,在传输中有几个 malloc 真的对于普通人有显著的区别吗?对 512MB 数据进行的 33832 个额外的 malloc 有什么影响?
为了衡量这些变化的影响,我决定比较 localhost 的 HTTP 传输,看看是否可以看到任何速度差异。localhost 对于这个测试是很好的,因为没有网络速度限制,更快的 curl 下载也越快。服务器端也会相同的快/慢,因为我将使用相同的测试集进行这两个测试。
我相同方式构建了 curl 7.53.1 和 curl 7.54.1-DEV,并运行这个命令:
curl http://localhost/80GB -o /dev/null
下载的 80GB 的数据会尽可能快地写到空设备中。
我获得的确切数字可能不是很有用,因为它将取决于机器中的 CPU、使用的 HTTP 服务器、构建 curl 时的优化级别等,但是相对数字仍然应该是高度相关的。新代码对决旧代码!
7.54.1-DEV 反复地表现出更快 30%!我的早期版本是 2200MB/秒增加到当前版本的超过 2900 MB/秒。
这里的要点当然不是说它很容易在我的机器上使用单一内核以超过 20GB/秒的速度来进行 HTTP 传输,因为实际上很少有用户可以通过 curl 做到这样快速的传输。关键在于 curl 现在每个字节的传输使用更少的 CPU,这将使更多的 CPU 转移到系统的其余部分来执行任何需要做的事情。或者如果设备是便携式设备,那么可以省电。
关于 malloc 的成本:512MB 测试中,我使用旧代码发生了 33832 次或更多的分配。旧代码以大约 2200MB/秒的速率进行 HTTP 传输。这等于每秒 145827 次 malloc - 现在它们被消除了!600 MB/秒的改进意味着每秒钟 curl 中每个减少的 malloc 操作能额外换来多传输 4300 字节。
去掉这些 malloc 难吗?一点也不难,非常简单。然而,有趣的是,在这个旧项目中,仍然有这样的改进空间。我有这个想法已经好几年了,我很高兴我终于花点时间来实现。感谢我们的测试套件,我可以有相当大的信心做这个“激烈的”内部变化,而不会引入太可怕的回归问题。由于我们的 API 很好地隐藏了内部,所以这种变化可以完全不改变任何旧的或新的应用程序……
(是的,我还没在版本中发布该变更,所以这还有风险,我有点后悔我的“这很容易”的声明……)
注意数字curl 的 git 仓库从 7.53.1 到今天已经有 213 个提交。即使我没有别的想法,可能还会有一次或多次的提交,而不仅仅是内存分配对性能的影响。
还有吗?还有其他类似的情况么?
也许。我们不会做很多性能测量或比较,所以谁知道呢,我们也许会做更多的愚蠢事情,我们可以收手并做得更好。有一个事情是我一直想做,但是从来没有做,就是添加所使用的内存/malloc 和 curl 执行速度的每日“监视” ,以便更好地跟踪我们在这些方面不知不觉的回归问题。
补遗,4/23(关于我在 hacker news、Reddit 和其它地方读到的关于这篇文章的评论)
有些人让我再次运行那个 80GB 的下载,给出时间。我运行了三次新代码和旧代码,其运行“中值”如下:
旧代码:
real 0m36.705s user 0m20.176s sys 0m16.072s
新代码:
real 0m29.032s user 0m12.196s sys 0m12.820s
承载这个 80GB 文件的服务器是标准的 Apache 2.4.25,文件存储在 SSD 上,我的机器的 CPU 是 i7 3770K 3.50GHz 。
有些人也提到 alloca() 作为该补丁之一也是个解决方案,但是 alloca() 移植性不够,只能作为一个孤立的解决方案,这意味着如果我们要使用它的话,需要写一堆丑陋的 #ifdef。
以上がCURL のメモリ割り当て操作を最適化するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 さまざまなタスクのLinuxとWindowsのパフォーマンスはどのように異なりますか?May 14, 2025 am 12:03 AM
さまざまなタスクのLinuxとWindowsのパフォーマンスはどのように異なりますか?May 14, 2025 am 12:03 AMLinuxはサーバーと開発環境でうまく機能しますが、Windowsはデスクトップやゲームでパフォーマンスが向上します。 1)Linuxのファイルシステムは、多数の小さなファイルを扱うときにうまく機能します。 2)Linuxは、高い並行性と高スループットネットワークシナリオで優れたパフォーマンスを発揮します。 3)Linuxメモリ管理は、サーバー環境でより多くの利点があります。 4)Linuxはコマンドラインとスクリプトタスクを実行するときに効率的ですが、Windowsはグラフィカルインターフェイスとマルチメディアアプリケーションでより良くパフォーマンスを発揮します。
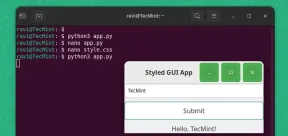 Pygobjectを使用してLinuxでGUIアプリケーションを作成する方法May 13, 2025 am 11:09 AM
Pygobjectを使用してLinuxでGUIアプリケーションを作成する方法May 13, 2025 am 11:09 AMグラフィカルユーザーインターフェイス(GUI)アプリケーションの作成は、アイデアを実現し、プログラムをよりユーザーフレンドリーにする素晴らしい方法です。 Pygobjectは、開発者がLinuxデスクトップにGUIアプリケーションを作成できるようにするPythonライブラリです。
 Arch LinuxにphpmyAdminを備えたランプスタックをインストールする方法May 13, 2025 am 11:01 AM
Arch LinuxにphpmyAdminを備えたランプスタックをインストールする方法May 13, 2025 am 11:01 AMArch Linuxは柔軟な最先端のシステム環境を提供し、完全にオープンソースであり、カーネルで最新のリリースを提供するため、小さな非クリティカルシステムでWebアプリケーションを開発するための強力なソリューションです。
 Arch LinuxにLEMP(Nginx、Php、Mariadb)をインストールする方法May 13, 2025 am 10:43 AM
Arch LinuxにLEMP(Nginx、Php、Mariadb)をインストールする方法May 13, 2025 am 10:43 AM最先端のソフトウェアArch Linuxを取り入れるローリングリリースモデルのため、メンテナンス、一定のアップグレード、および賢明なFIのための余分な時間が必要であるため、信頼できるネットワークサービスを提供するためにサーバーとして実行するように設計および開発されていません
![12必要なLinuxコンソール[ターミナル]ファイルマネージャー](https://img.php.cn/upload/article/001/242/473/174710245395762.png?x-oss-process=image/resize,p_40) 12必要なLinuxコンソール[ターミナル]ファイルマネージャーMay 13, 2025 am 10:14 AM
12必要なLinuxコンソール[ターミナル]ファイルマネージャーMay 13, 2025 am 10:14 AMLinuxコンソールファイルマネージャーは、ローカルマシンでファイルを管理する場合、またはリモートのファイルに接続する場合、日々のタスクで非常に役立ちます。ディレクトリのビジュアルコンソール表現は、ファイル/フォルダーの操作をすばやく実行して保存するのに役立ちます
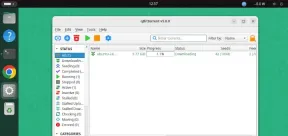 QBITTORRENT:強力なオープンソースBitTorrentクライアントMay 13, 2025 am 10:12 AM
QBITTORRENT:強力なオープンソースBitTorrentクライアントMay 13, 2025 am 10:12 AMQbittorrentは、ユーザーがインターネット上でファイルをダウンロードして共有できる人気のオープンソースBittorrentクライアントです。最新バージョンのQbittorrent 5.0は最近リリースされ、新機能と改善が詰め込まれています。 この記事はそうします
 Arch Linuxでnginx仮想ホスト、phpmyadmin、およびSSLをセットアップMay 13, 2025 am 10:03 AM
Arch Linuxでnginx仮想ホスト、phpmyadmin、およびSSLをセットアップMay 13, 2025 am 10:03 AM以前のArch Linux LEMPの記事では、ネットワークサービス(NGINX、PHP、MySQL、およびPHPMYADMIN)のインストールと、MySQL ServerとPHPMyAdminに必要な最小限のセキュリティの構成など、基本的なものを取り上げました。 このトピックは、フォームに厳密に関連しています
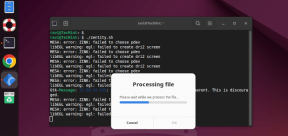 Zenity:シェルスクリプトにGTKダイアログを構築しますMay 13, 2025 am 09:38 AM
Zenity:シェルスクリプトにGTKダイアログを構築しますMay 13, 2025 am 09:38 AMZenityは、コマンドラインを使用してLinuxでグラフィカルなダイアログボックスを作成できるツールです。グラフィカルユーザーインターフェイス(GUI)を作成するためのツールキットであるGTKを使用して、スクリプトに視覚要素を簡単に追加できます。 ゼニティは非常にuです


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

メモ帳++7.3.1
使いやすく無料のコードエディター

VSCode Windows 64 ビットのダウンロード
Microsoft によって発売された無料で強力な IDE エディター

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

SublimeText3 英語版
推奨: Win バージョン、コードプロンプトをサポート!

