
ホームページ >テクノロジー周辺機器 >AI >システム研究から次世代自動運転システムに不可欠な大型モデルが判明
システム研究から次世代自動運転システムに不可欠な大型モデルが判明

- PHPz転載
- 2023-12-16 14:21:181356ブラウズ
大規模言語モデル (LLM) とビジュアル基本モデル (VFM) の出現により、大規模モデルを備えたマルチモーダル人工知能システムが現実世界を包括的に認識し、人間と同じように意思決定できるようになると期待されています。ここ数カ月、LLM は自動運転研究の分野で広く注目を集めています。 LLM には大きな可能性があるにもかかわらず、駆動システムには依然として重要な課題、機会、将来の研究の方向性があり、現時点では詳細な解明が不足しています。
この記事では、Tencent Maps、Pudu Researcher の大学、UIUC、およびバージニア大学は、この分野で体系的な調査を実施しました。この研究ではまず、マルチモーダル大規模言語モデル (MLLM) の背景、LLM を使用したマルチモーダル モデル開発の進捗状況、および自動運転の歴史の振り返りを紹介します。この調査では、運転、交通、地図システム用の既存の MLLM ツールと既存のデータセットの概要を提供します。この研究では、自動運転における LLM の適用に関する最初のワークショップである、自動運転のための大規模言語および視覚モデルに関する第 1 回 WACV ワークショップ (LLVM-AD) の関連研究も要約されています。この分野の発展をさらに促進するために、この研究では、MLLM を自動運転システムに適用する方法と、学界と産業界が解決する必要があるいくつかの重要な問題についても説明します。

- 概要リンク: https://arxiv.org/abs/2311.12320
- セミナーリンク: https://llvm-ad.github.io/
- Github リンク: https://github.com/IrohXu/マルチモーダル LLM 自動運転
マルチモーダル大規模言語モデル (MLLM) は、最近非常に注目を集めています。このモデルは、LLM の推論機能と画像、ビデオ、オーディオ データを組み合わせ、これらのデータがマルチモーダル配置を通じてさまざまなタスクをより効率的に実行できるようにします。画像分類、テキストの配置など、対応するビデオと音声検出を備えています。さらに、ロボット工学の分野では、LLM が単純なタスクを処理できることがいくつかの研究で示されていますが、現在、自動運転の分野では、MLLM の統合はゆっくりと進んでいます。 GPT-4、PaLM-2、および LLaMA-2 などの LLM には、さらなる研究と探求がまだ必要です
このレビューでは、研究者は、LLM を自動運転の分野に統合することで、大きなパラダイムシフトにより、運転体験が向上し、知覚、動作計画、人間と車両の相互作用、および動作制御により、より適応性が高く信頼性の高い未来の交通ソリューションがユーザーに提供されます。知覚の面では、LLM はツール学習を使用して外部 API を呼び出し、高精度の地図、交通情報、気象情報などのリアルタイムの情報ソースにアクセスできるため、車両は周囲の環境をより包括的に理解できます。自動運転車は、LLM を通じて渋滞ルートを推論し、効率性と安全運転を向上させるための代替経路を提案できます。動作計画と人間と車両の相互作用の観点から、LLM はユーザー中心のコミュニケーションを促進し、乗客が日常の言語でニーズや好みを表現できるようにします。モーションコントロールに関しては、LLMはまずドライバーの好みに応じて制御パラメーターをカスタマイズできるようにし、パーソナライズされた運転体験を実現します。さらに、LLM はモーション コントロール プロセスの各ステップを説明することで、ユーザーに透明性を提供できます。このレビューでは、将来の SAE L4 ~ L5 レベルの自動運転車では、乗客は言語、ジェスチャー、さらには目さえも使用してリクエストを伝達できるようになり、MLLM が統合されたビジュアル ディスプレイや音声応答を通じて車内および運転フィードバックをリアルタイムで提供できるようになると予測しています。
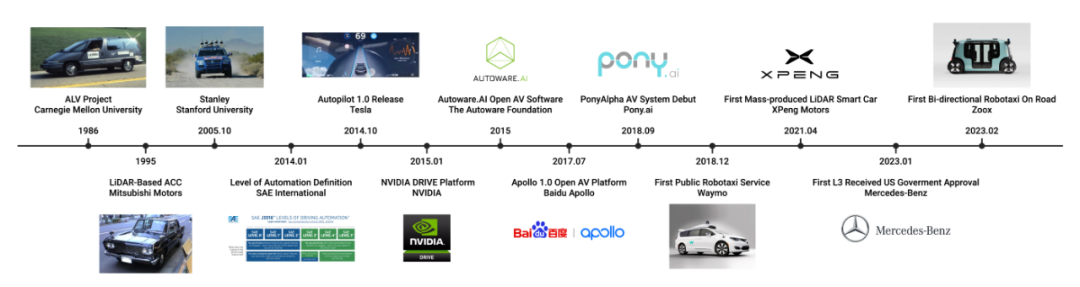
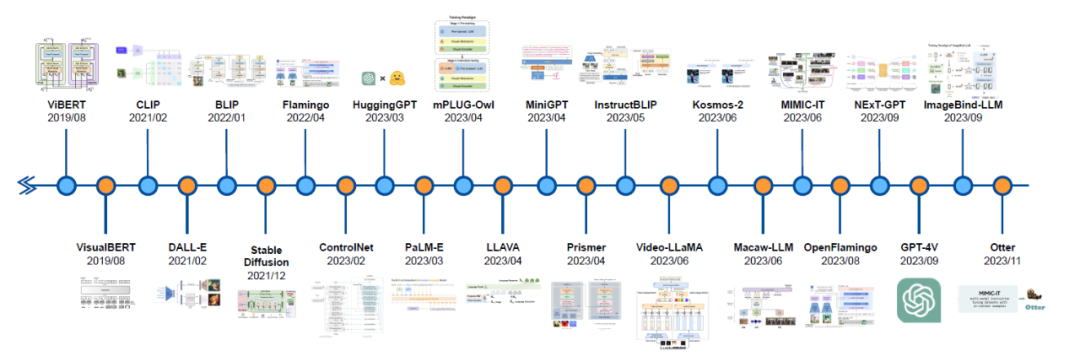
##自動運転とマルチモーダル大規模言語モデルの開発の歴史
自動運転MLLMの研究概要:現行モデルのLLMフレームワークには主にLLaMA、Llama 2、GPT-3.5、GPT-4が含まれています。 . Flan5XXL、ビクーニャ-13b。この表の FT、ICL、および PT は、微調整、状況に応じた学習、および事前トレーニングを指します。文献リンクについては、github リポジトリを参照してください: https://github.com/IrohXu/Awesome-Multimodal-LLM-Autonomous-Driving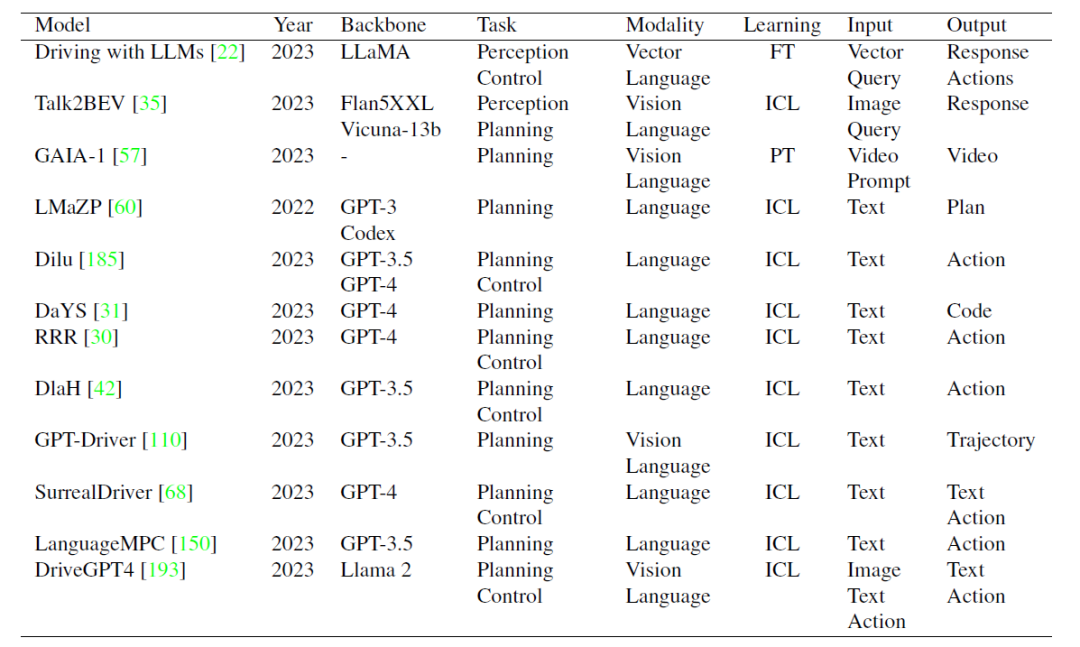
自動運転と LLVM の間に架け橋を築くために、関連研究者が最初の大規模言語および視覚モデル自動運転ワークショップ (LLVM-AD) を開催しました。このワークショップは、学術研究者と業界専門家の協力を強化し、自動運転の分野でマルチモーダル大規模言語モデルを実装する可能性と課題を探ることを目的としています。 LLVM-AD は、オープンソースの実際の交通言語理解データセットのその後の開発をさらに促進します
最初の WACV 大規模言語および視覚モデル自動運転ワークショップ (LLVM-AD) は合計で受け入れられました9 つの紙の紙。これらの論文の一部は自動運転におけるマルチモーダル大規模言語モデルを中心に展開しており、LLM をユーザーと車両のインタラクション、動作計画、および車両制御に統合することに焦点を当てています。いくつかの論文では、自動運転車における人間のような対話と意思決定のための LLM の新しいアプリケーションも検討しています。たとえば、「人間の運転を模倣する」と「言語による運転」では、複雑な運転シナリオにおける LLM の解釈と推論、および人間の行動を模倣するためのフレームワークを調査します。さらに、「人間中心の自律システムと LLM」では、LLM の設計の中心にユーザーを置き、ユーザーの指示を解釈するために LLM を使用することを強調しています。このアプローチは、人間中心の自律システムへの重要な移行を表しています。このワークショップでは、融合 LLM に加えて、いくつかの純粋なビジョンとデータ処理ベースの手法も取り上げました。さらに、ワークショップでは革新的なデータ処理および評価方法が紹介されました。たとえば、NuScenes-MQA では、自動運転データセット用の新しいアノテーション スキームが導入されています。まとめると、これらの論文は、言語モデルと高度な技術を自動運転に統合する進歩を実証し、より直観的で効率的で人間中心の自動運転車への道を切り開く
将来の開発のために、この研究は
書き直す必要がある内容は次のとおりです: 1. 自動運転におけるマルチモダリティ ビッグ言語モデル用の新しいデータセット
#言語理解における大きな言語モデルの成功にもかかわらず、それを自動運転に適用することは依然として課題に直面しています。これは、これらのモデルがパノラマ画像、3D 点群、高精度地図などのさまざまなモダリティからの入力を統合して理解する必要があるためです。現在、データのサイズと品質に制限があるため、既存のデータセットではこれらの課題に完全には対処できません。さらに、NuScenes などの初期のオープンソース データセットからアノテーションが付けられた視覚言語データセットは、運転シナリオにおける視覚言語の理解のための堅牢なベースラインを提供しない可能性があります。したがって、以前のデータセット配布のロングテール (不均衡) 問題を補い、これらのモデルのパフォーマンスを効果的にテストして強化するために、広範囲の交通および運転シナリオをカバーする新しい大規模なデータセットが緊急に必要とされています。自動運転アプリケーション。
#2. 自動運転における中規模および大規模の言語モデルに必要なハードウェア サポート
自動運転車のさまざまな機能ハードウェア要件は異なります。運転計画や車両制御への関与のために車両内で LLM を使用するには、安全性を確保するためにリアルタイム処理と低遅延が必要ですが、これにより計算要件が増加し、電力消費に影響します。 LLM がクラウドに展開されている場合、データ交換の帯域幅も重要なセキュリティ要素になります。対照的に、LLM をナビゲーションの計画や運転に関係のないコマンド (車内の音楽再生など) の分析に使用する場合、大量のクエリやリアルタイム パフォーマンスは必要ないため、リモート サービスが実行可能なオプションになります。将来的には、自動運転における LLM は知識の蒸留によって圧縮され、計算要件と遅延が削減される可能性があり、この分野にはまだ多くの開発の余地があります。
3. 大規模な言語モデルを使用して高精度マップを理解する
高精度マップは重要な役割を果たします自動運転車テクノロジーでは、車両が動作する物理環境に関する基本的な情報を提供するため、重要な役割を果たします。 HD マップのセマンティック マップ レイヤーは、物理環境の意味とコンテキスト情報をキャプチャするため、重要です。この情報をテンセントの高精度地図 AI 自動アノテーション システムによって推進される次世代の自動運転に効果的にエンコードするには、これらのマルチモーダルな特徴を言語空間にマッピングするための新しいモデルが必要です。テンセントは、アクティブラーニングに基づいたTHMA高精度地図AI自動ラベリングシステムを開発し、数十万キロメートル規模の高精度地図を作成してラベル付けできる。この分野の開発を促進するために、テンセントは、THMA に基づく MAPLM データセットを提案しました。これには、パノラマ画像、3D LIDAR 点群、コンテキストベースの高精度地図注釈、および新しい質疑応答ベンチマーク MAPLM-QA が含まれています。
4. 人間と車両のインタラクションにおける大規模な言語モデル
人間と車両の相互作用と人間の運転行動の理解も、自動運転において大きな課題となります。人間のドライバーは、速度を落として道を譲ったり、体の動きを使って他のドライバーや歩行者とコミュニケーションしたりするなど、非言語的な信号に依存することがよくあります。これらの非言語信号は、路上でのコミュニケーションにおいて重要な役割を果たします。自動運転車は他のドライバーが予期しない動作をすることが多かったため、これまで自動運転システムに関連した事故が数多く発生してきました。将来的には、MLLM はさまざまなソースからの豊富なコンテキスト情報を統合し、ドライバーの視線、ジェスチャー、運転スタイルを分析して、これらの社会的シグナルをより深く理解し、効率的な計画を立てることができるようになります。 LLM は、他のドライバーの社会的信号を推定することで、自動運転車の意思決定能力と全体的な安全性を向上させることができます。
パーソナライズされた自動運転
自動運転車が開発されるにつれて、重要な側面は、ユーザーのニーズにどのように適応するかを考慮することです。個人的な運転の好み。自動運転車はユーザーの運転スタイルを模倣すべきであるというコンセンサスが高まっています。これを達成するために、自動運転システムは、ナビゲーション、車両メンテナンス、エンターテインメントなどのさまざまな側面におけるユーザーの好みを学習し、統合する必要があります。 LLM の命令調整機能と状況に応じた学習機能により、ユーザーの好みや運転履歴情報を自動運転車に統合して、パーソナライズされた運転体験を提供するのに最適です。
概要
長年にわたり、自動運転は注目の的であり、多くのベンチャー投資家を魅了してきました。 LLM を自動運転車に統合するには特有の課題が生じますが、それらを克服することで既存の自動運転システムが大幅に強化されます。 LLM によってサポートされるスマート コックピットは、運転シナリオとユーザーの好みを理解し、車両と乗員の間により深い信頼を確立する機能を備えていることが予測されます。さらに、LLM を導入した自動運転システムは、歩行者の安全と車両乗員の安全を天秤にかけることに関する倫理的ジレンマにうまく対処できるようになり、複雑な運転シナリオにおいてより倫理的になる可能性が高い意思決定プロセスを促進します。この記事は、WACV 2024 LLVM-AD ワークショップ委員会のメンバーからの洞察を統合し、研究者に LLM テクノロジーを活用した次世代自動運転車の開発に貢献するよう促すことを目的としています。
以上がシステム研究から次世代自動運転システムに不可欠な大型モデルが判明の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。