
ホームページ >テクノロジー周辺機器 >AI >Visual Transformer の深い理解、Visual Transformer の分析
Visual Transformer の深い理解、Visual Transformer の分析

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-12-15 11:17:371219ブラウズ
この記事は自動運転ハート公開アカウントの許可を得て転載しています。転載する場合は出典元にご連絡ください。
前書き&&著者の個人的理解を
現在、Transformer 構造に基づくアルゴリズム モデルは、コンピューター ビジョン (CV) の分野に大きな影響を与えています。これらは、多くの基本的なコンピューター ビジョン タスクにおいて、以前の畳み込みニューラル ネットワーク (CNN) アルゴリズム モデルを上回っています。以下は、私が見つけたさまざまな基本的なコンピューター ビジョン タスクの最新の LeaderBoard ランキングです。LeaderBoard を通じて、さまざまなコンピューター ビジョン タスクにおける Transformer アルゴリズム モデルの優位性がわかります。
- 画像分類タスク
1 つ目は ImageNet の LeaderBoard で、上位 5 つのモデルのうち、各モデルは Transformer 構造を使用しており、CNN 構造は部分的にのみ使用されているか、Transformer と組み合わせられていることがリストからわかります。

画像分類タスクのリーダーボード
- オブジェクト検出タスク
次のステップは COCO テスト開発ですLeaderBoard のリストからわかるように、トップ 5 の半分以上は DETR などのアルゴリズム構造に基づいています。
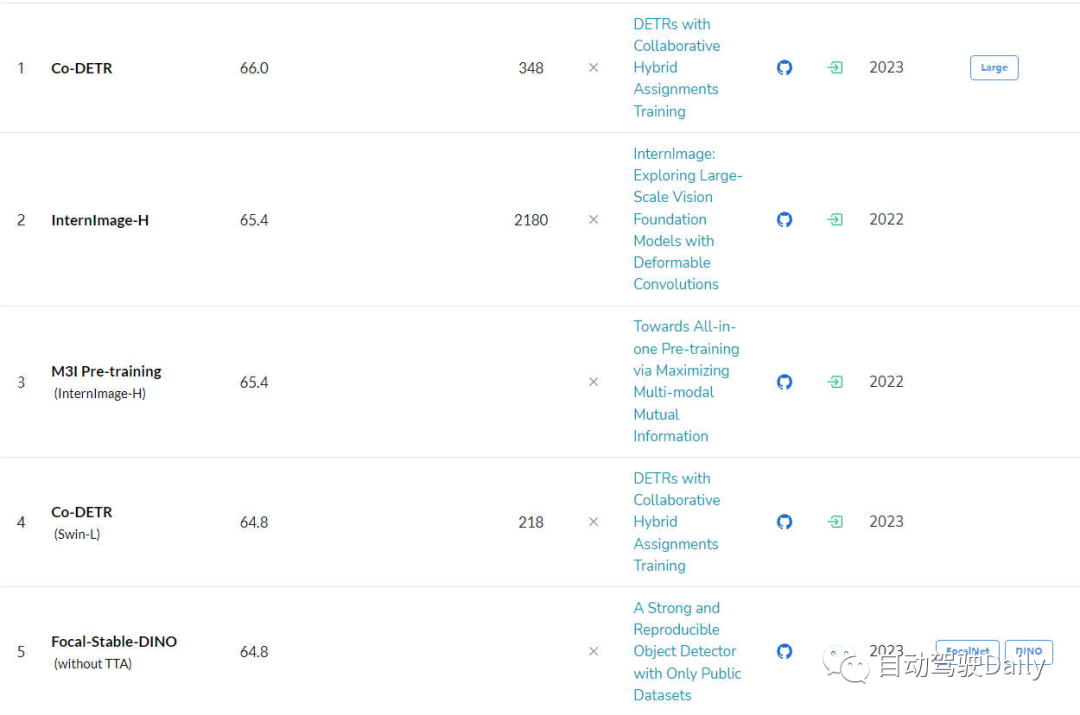 ターゲット検出タスクのリーダーボード
ターゲット検出タスクのリーダーボード
- セマンティック セグメンテーション タスク
最後は、ADE20K val の LeaderBoard です。リストを見てみる リストの上位数件のうち、トランスフォーマー構造が依然として現在の主力を占めていることがわかります。
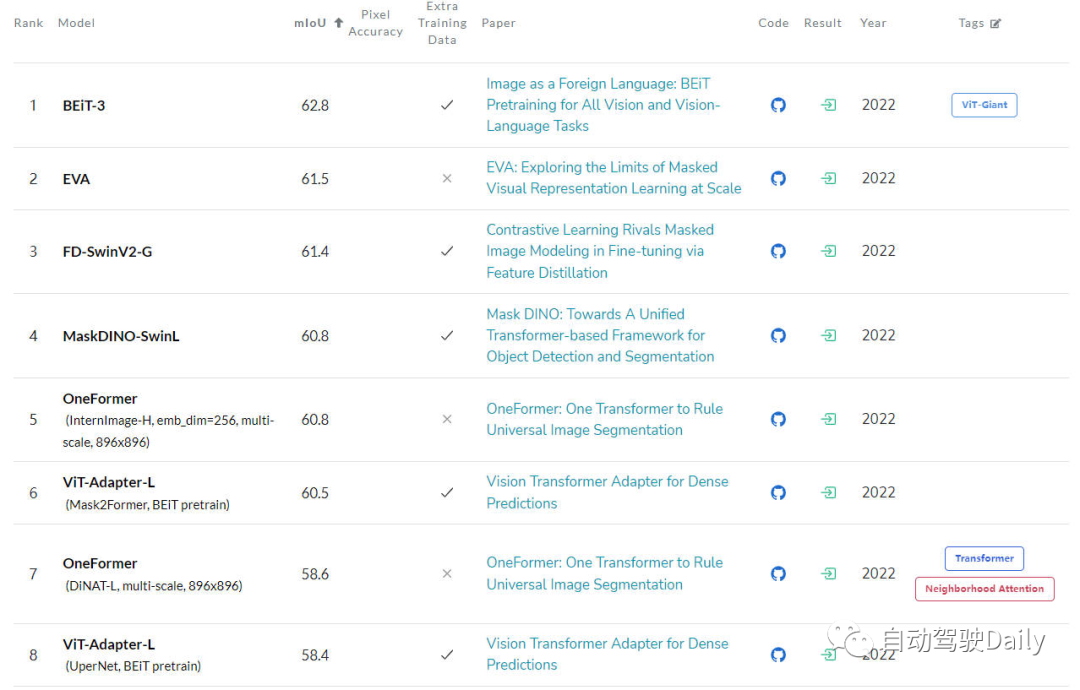 セマンティック セグメンテーション タスク用のリーダーボード
セマンティック セグメンテーション タスク用のリーダーボード
Transformer は中国で大きな発展の可能性を示していますが、現在のコンピューター ビジョン コミュニティは Vision Transformer の内部動作原理を完全には理解していません。意思決定の根拠(予測結果の出力)が把握できていないため、解釈可能性の必要性が徐々に顕著になってきます。このようなモデルがどのように意思決定を行うかを理解することによってのみ、モデルのパフォーマンスを向上させ、人工知能システムに対する信頼を築くことができます。
この記事の主な目的は、Vision Transformer のさまざまな解釈方法を研究し、さまざまな研究に従ってそれらを比較することです。アルゴリズムの動機、構造タイプ、適用シナリオを分類してレビュー記事を形成します
ビジョン トランスフォーマーの分析
先ほど述べたように、ビジョン トランスフォーマーの構造は次のようになります。さまざまな基本的なコンピュータ ビジョン タスクで非常に良い結果を達成しました。コンピュータ ビジョン コミュニティでは、解釈可能性を高めるために非常に多くの方法が登場しています。この記事では、一般的なアトリビューション手法、アテンションベースの手法、プルーニングベースの手法、本質的に説明可能なものから始まる分類タスクに主に焦点を当てます。メソッド、その他のタスク これら 5 つの側面のうち、最新のタスクと古典的なタスクを選択して紹介します。論文に掲載されているマインド マップは次のとおりです。興味のある内容に基づいてさらに詳しく読むことができます~
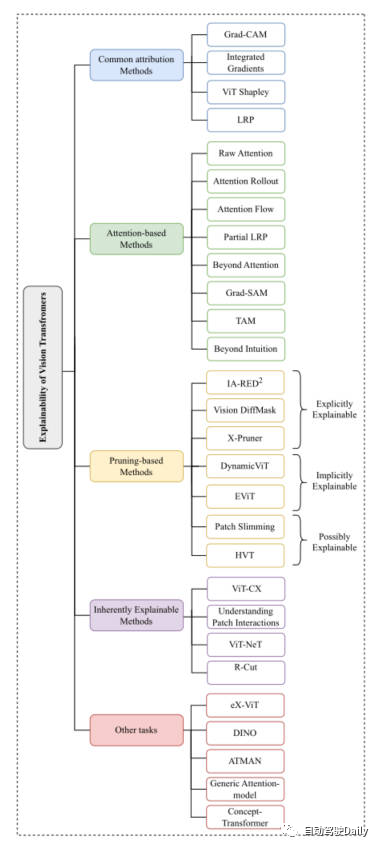
この記事のマインド マップ
一般的なアトリビューション メソッド
属性ベースのメソッドの説明は、通常、モデルの入力特徴がどのように最終的な出力結果を徐々に取得するかというプロセスから始まります。このタイプの方法は、主にモデルの予測結果と入力特徴間の相関を測定するために使用されます。
これらの方法の中には、Grad-CAM や Integrated Gradients などがあります。アルゴリズム Visual Transformer に基づくアルゴリズムに直接適用されます。 SHAP や Layer-Wise Relevance Propagation (LRP) などの他の方法も、ViT ベースのアーキテクチャを調査するために使用されています。ただし、SHAP などの手法は計算コストが非常に高いため、最近の ViT Shapely アルゴリズムは、ViT 関連のアプリケーション研究に適応するように設計されました。
アテンションベースのメソッド
Vision Transformer は、アテンション メカニズムを通じて強力な特徴抽出機能を獲得します。注意に基づく解釈可能性手法の中でも、注意の重みの結果を視覚化することは非常に有効な手法です。この記事では、いくつかの視覚化テクニックを紹介します
- 生の注意力 : 名前が示すように、この方法は、ネットワーク モデルの中間層によって得られた注意力の重みマップを視覚化し、モデルの効果を分析することです。
- アテンション ロールアウト: このテクノロジーは、ネットワークのさまざまなレイヤーでアテンションの重みを拡張することにより、入力トークンから中間の埋め込みへの情報の転送を追跡します。
- アテンション フロー: このメソッドは、アテンション グラフをフロー ネットワークとして扱い、最大フロー アルゴリズムを使用して中間埋め込みから入力トークンまでの最大フロー値を計算します。
- partialLRP: この手法は、Vision Transformer のマルチヘッド アテンション メカニズムを視覚化するために提案されており、各アテンション ヘッドの重要性も考慮されています。
- Grad-SAM: この方法は、モデルの予測を説明するために元のアテンション行列のみに依存する制限を軽減するために使用され、研究者に元のアテンションの重みで勾配を使用するよう促します。
- 直感を超えて: この方法は、注意を説明する方法でもあり、注意の知覚と推論フィードバックの 2 段階が含まれます。
最後に、さまざまな解釈方法のアテンションの視覚化図を示します。さまざまな視覚化方法の違いを自分で感じてください。

さまざまな視覚化手法のアテンション マップの比較
プルーニング ベースの手法
プルーニングは、広く使用されている非常に効果的な手法です。変圧器構造の効率と複雑さを最適化します。枝刈り手法は、冗長な情報や無駄な情報を削除することで、モデルのパラメーターの数と計算の複雑さを軽減します。枝刈りアルゴリズムはモデルの計算効率の向上に重点を置いていますが、このタイプのアルゴリズムでもモデルの解釈可能性を実現できます。
この記事の Vision-Transformer に基づく枝刈り手法は、explicitly Explainable (明示的に説明可能)、implicitly Explainable (暗黙的に説明可能) の 3 つのカテゴリに大別できます。式は説明できる)、おそらく説明可能 (説明可能かもしれない)。
-
明示的に説明可能な
枝刈りベースのメソッドの中には、よりシンプルでより説明可能なモデルを提供できるメソッドがいくつかあります。
- IA-RED^2: この方法の目標は、計算効率とアルゴリズム モデルの解釈可能性の間の最適なバランスを達成することです。このプロセスでは、元の ViT アルゴリズム モデルの柔軟性が維持されます。
- X-Pruner: このメソッドは、特定のクラスでの寄与を予測する解釈可能な知覚マスクを作成することによって、顕著性ユニットを枝刈りするためのメソッドです。
- Vision DiffMask: このプルーニング メソッドには、各 ViT レイヤーにゲート メカニズムを追加することが含まれており、ゲート メカニズムを通じて、入力をシールドしながらモデルの出力を維持できます。さらに、アルゴリズム モデルは残りの画像のサブセットを明確にトリガーできるため、モデルの予測をより深く理解できるようになります。
-
暗黙的に説明可能
枝刈りベースの手法の中には、暗黙的説明可能性モデル カテゴリに分類できる古典的な手法もいくつかあります。 - 動的 ViT: この方法では、軽量の予測モジュールを使用して、現在の特性に基づいて各トークンの重要性を推定します。この軽量モジュールは、階層的な方法で冗長なトークンを取り除くために、ViT のさまざまなレイヤーに追加されます。最も重要なことは、この方法では、分類に最も寄与する重要な画像部分を徐々に特定することにより、解釈可能性が向上します。
- Efficient Vision Transformer (EViT): このメソッドの中心的なアイデアは、トークンを再編成することで EViT を高速化することです。 EViT は、アテンション スコアを計算することで、最も関連性の高いトークンを保持しながら、関連性の低いトークンを追加のトークンに融合します。同時に、EViT の解釈可能性を評価するために、論文の著者は複数の入力画像上でトークン認識プロセスを視覚化しました。
-
おそらく説明可能
このタイプの方法はもともと ViT の説明可能性を向上させることを目的としたものではありませんでしたが、このタイプの方法は、ViT に関するさらなる研究の多くの機会を提供します。モデルの説明可能性、大きな可能性。
- パッチスリム化: トップダウンのアプローチで画像内の冗長なパッチに焦点を当て、ViT を加速します。このアルゴリズムは、重要な視覚的特徴を強調表示するキー パッチの機能を選択的に保持するため、解釈可能性が向上します。
- 階層型ビジュアル トランスフォーマー (HVT): このメソッドは、ViT のスケーラビリティとパフォーマンスを強化するために導入されました。モデルの深さが増加するにつれて、シーケンスの長さは徐々に減少します。さらに、ViT ブロックを複数のステージに分割し、各ステージでプーリング演算を適用することで、計算効率が大幅に向上します。モデルの最も重要なコンポーネントに徐々に集中していることを考えると、解釈可能性と説明可能性の向上に対するその潜在的な影響を調査する機会があります。
本質的に説明可能なメソッド
さまざまな解釈可能なメソッドの中には、主にアルゴリズムを本質的に説明できるモデルを開発するメソッドのクラスがあります。ただし、これらのモデルは通常、ブラック ボックス モデルと同じレベルの精度。したがって、解釈可能性とパフォーマンスの間で慎重なバランスを考慮する必要があります。次に、いくつかの古典的な作品を簡単に紹介します。
- ViT-CX: この方法は、ViT モデル用にカスタマイズされたマスクベースの解釈方法です。このアプローチは、パッチの埋め込みとそれがモデル出力に与える影響に焦点を当てるのではなく、それらに依存しています。この方法は、マスク生成とマスク集約の 2 つの段階で構成されており、それにより、より意味のある顕著性マップが提供されます。
- ViT-NeT: このメソッドは、ツリー構造とプロトタイプを通じて意思決定プロセスを記述する新しいニューラル ツリー デコーダーです。同時に、このアルゴリズムにより、結果を視覚的に解釈することもできます。
- R-Cut: この方法は、関係の重み付けとカットを通じて ViT の解釈可能性を高めます。このメソッドには、Relationship Weighted Out モジュールと Cut モジュールという 2 つのモジュールが含まれています。前者は、中間層から特定のクラスの情報を抽出することに焦点を当て、関連する機能を強調します。後者は、きめの細かい特徴分解を実行します。両方のモジュールを統合することにより、高密度のクラス固有の解釈可能マップを生成できます。
その他のタスク
ViT ベースのアーキテクチャについては、探索における他のコンピュータ ビジョン タスクについても説明する必要があります。特に他のタスクを対象とした解釈可能性手法がいくつか提案されており、関連分野の最新の成果を以下に紹介します。
- eX-ViT: このアルゴリズムは、弱く監視されたセマンティック セグメンテーションに基づく、新しい解釈可能なビジュアル トランスフォーマーです。さらに、解釈可能性を向上させるために、グローバル レベルの属性指向損失、ローカル レベルの属性識別性損失、および属性多様性損失の 3 つの損失を含む属性指向損失モジュールが導入されます。前者はアテンション マップを使用して解釈可能な特徴を作成し、後者の 2 つは属性学習を強化します。
- DINO: このメソッドは、単純な自己教師ありメソッドであり、ラベルのない自己蒸留メソッドです。最終的に学習されたアテンション マップは、画像の意味領域を効果的に保持できるため、解釈可能な目的を達成できます。
- 汎用アテンション モデル: このメソッドは、Transformer アーキテクチャに基づく予測用のアルゴリズム モデルです。この方法は、最も一般的に使用される 3 つのアーキテクチャ、つまり純粋なセルフ アテンション、共同アテンションと組み合わせたセルフ アテンション、およびエンコーダ/デコーダ アテンションに適用されます。モデルの解釈可能性をテストするために、著者らは視覚的な質問応答タスクを使用しましたが、これは物体検出や画像セグメンテーションなどの他の CV タスクにも適用できます。
- ATMAN: これは、アテンション メカニズムを使用して、出力予測に対する入力の相関マップを生成する、モダリティに依存しない摂動手法です。このアプローチは、メモリ効率の高いアテンション操作を通じて変形予測を理解しようとします。
- Concept-Transformer: このアルゴリズムは、ユーザー定義の高レベルの概念の注意スコアを強調表示することによってモデル出力の説明を生成し、信頼性と信頼性を保証します。
将来の見通し
現在、Transformer アーキテクチャに基づくアルゴリズム モデルは、さまざまなコンピューター ビジョン タスクにおいて優れた結果を達成しています。ただし、現在、特に ViT アプリケーションにおいて、解釈可能性手法を使用してモデルのデバッグと改善を促進し、モデルの公平性と信頼性を向上させる方法に関する明確な研究が不足しています。読者がそのようなモデルのアーキテクチャをよりよく理解できるように、Vision Transformer に基づいて解釈可能性アルゴリズム モデルを分類および整理することです。皆様のお役に立てば幸いです。
 What need to書き換えられる内容は次のとおりです: 元のリンク: https://mp.weixin.qq.com/s/URkobeRNB8dEYzrECaC7tQ
What need to書き換えられる内容は次のとおりです: 元のリンク: https://mp.weixin.qq.com/s/URkobeRNB8dEYzrECaC7tQ
以上がVisual Transformer の深い理解、Visual Transformer の分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。