



上司の何開明氏は正式にMITに加わっていないが、MITとの最初の共同研究が発表された :
彼はMITと共同で開発した教師と生徒 自己条件付き画像生成フレームワークが開発され、RCG という名前が付けられました (コードはオープンソースです)。
このフレームワーク構造は非常にシンプルですが、効果は抜群で、ImageNet-1K データセット上で無条件画像生成の 新しい SOTA を直接実装しています。
生成される画像には人間による注釈 (つまり、プロンプトの単語、クラス ラベルなど) が必要なく、両方の忠実度を実現できます。そして多様性を持つこと。

このようにして、無条件画像生成のレベルを大幅に向上させるだけでなく、現在の最良の条件付き生成方法と競合することもできます。
何開明氏のチームの言葉:
条件付き生成タスクと無条件生成タスクの間の長年にわたるパフォーマンスの差が、この瞬間についに縮まりました。
それでは、具体的にはどのように行われるのでしょうか?
自己教師あり学習に似た自己条件生成
まず、いわゆる無条件生成とは、モデルが入力信号の助けを借りずにデータ分布の生成内容を直接取得することを意味します。
このトレーニング方法は難しいため、教師なし学習と教師あり学習を比較できないのと同じように、条件付き生成には常に大きなパフォーマンスの差がありました。
自己教師あり学習の出現とまったく同じです。
#無条件画像生成の分野では、自己教師あり学習の概念に似た自己条件生成手法もあります。 ノイズ分布を画像分布に単純にマッピングする従来の無条件生成と比較して、この方法は主にデータ分布自体から導出される表現分布に基づいてピクセル生成プロセスを設定します。 条件付き画像生成を超えて、人間による注釈を必要としない
分子設計や創薬などのアプリケーションの開発を促進することが期待されています(これが条件付き画像生成の理由ですは開発されています。これは良いことです。無条件生成にも注意を払う必要があります)。 さて、この自己条件付き生成の概念に基づいて、He Kaiming のチームは最初に
表現拡散モデル RDMを開発しました。 自己教師あり画像エンコーダを通じて画像からインターセプトされ、主に低次元の自己教師あり画像表現を生成するために使用されます
そのコア アーキテクチャは次のとおりです。 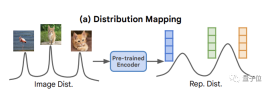
(変換)
元の表現次元へ。各層には、LayerNorm 層、SiLU 層、および線形層が含まれます。
このような RDM には 2 つの利点があります。 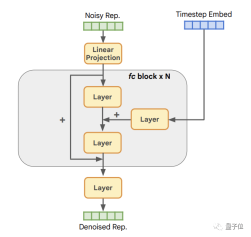
# で構成される単純な自己条件付き生成フレームワークです。 ## コンポーネント
は次のもので構成されます: 1 つは SSL 画像エンコーダ
で、画像分布をコンパクトな表現分布に変換するために使用されます。 。 1 つは RDM
で、分布のモデル化とサンプリングに使用されます。 最後に、ピクセル ジェネレーター MAGE
があります。これは、表現に従って画像を処理するために使用されます。 #MAGE は、トークン化された画像にランダム マスクを追加し、同じ画像から抽出された表現を条件として欠落したトークンを再構築するようネットワークに要求することで機能します。
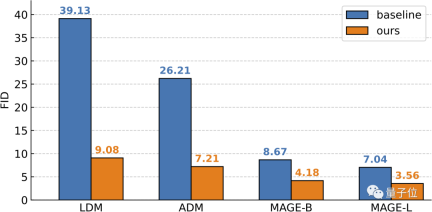
#テストの結果、この自己条件付き生成フレームワークの構造はシンプルであるにもかかわらず、その効果は非常に優れていることが最終結果でわかりました。ImageNet 256×256 上で、RCG は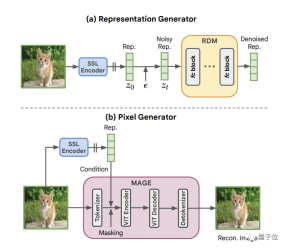 を達成しました。 FID は 3.56、IS
を達成しました。 FID は 3.56、IS
スコアは 186.9 でした。 これと比較すると、以前の最も強力な無条件生成メソッドの FID スコアは 7.04、IS スコアは 123.5 でした。
RCG の場合、条件付き生成で優れたパフォーマンスを発揮するだけでなく、現場のベースライン モデルと比較した場合、同じレベルまたはそれを上回るパフォーマンスを発揮します。
最後に、分類子のガイダンスがなければ、RCG の結果は次のようになります。さらに 3.31(FID) と 253.4(IS) に改良されました。
チームは次のように述べています:
これらの結果は、条件付き画像生成モデルには大きな可能性があり、この分野に今後の新時代の到来を告げる可能性があることを示しています
チームの紹介
この記事には 3 人の著者がいます:

の研究方向は、クロスモーダル統合センシング技術です。
彼の個人的なホームページは非常に興味深いもので、レシピ集もあります。研究と料理が彼が最も情熱を注いでいる 2 つのことです。
最後に、責任著者のHe Yuming氏は来年正式に学術界に復帰し、Meta社を離れてMITの電気工学およびコンピュータサイエンス学部に移り、そこで同僚となる予定です。ディナ・カタビと。 
 論文を表示するには、次のリンクをクリックしてください: https://arxiv.org/abs/2312.03701
論文を表示するには、次のリンクをクリックしてください: https://arxiv.org/abs/2312.03701
以上がHe Kaiming 氏が MIT と協力: シンプルなフレームワークが無条件画像生成における最新のブレークスルーを実現の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 alteryxとは何ですか? | Analytics VidhyaApr 15, 2025 am 11:03 AM
alteryxとは何ですか? | Analytics VidhyaApr 15, 2025 am 11:03 AMAlteryx:オールインワンデータ分析ソリューション 手がかりとして統計データのみを使用して、複雑な謎に取り組むことを想像してください。 データの専門家は、毎日同様の課題に直面しています。 Alteryxはソリューションであり、ユーザーがデータの複雑さを征服できるようにします
 llama 3.1 vs llama 3:どちらが良いですか?Apr 15, 2025 am 10:53 AM
llama 3.1 vs llama 3:どちらが良いですか?Apr 15, 2025 am 10:53 AMメタのllama 3.1 70bおよびllama 3 70b:詳細な比較 Metaは最近、70Bパラメーターモデルを含むLlama 3.1を大幅に小さいバリエーションとともにリリースしました。 このアップグレードは、わずか3か月前のLlama 3リリースに続きます。 llama 3.1
 無料で始めることができる7つのAI PPTメーカー!Apr 15, 2025 am 10:51 AM
無料で始めることができる7つのAI PPTメーカー!Apr 15, 2025 am 10:51 AMプレゼンテーションのパワーを解き放ちます:7無料のAI電源ポイントメーカー あなたが傑出したキャップストーンプロジェクトを作成している最終学生であろうと、忙しい専門家の会議やプレゼンテーションをジャグリングしているかどうかにかかわらず、強力な第一印象を与えることが最重要です。
 Power BIセマンティックモデルとは何ですか?Apr 15, 2025 am 10:46 AM
Power BIセマンティックモデルとは何ですか?Apr 15, 2025 am 10:46 AM導入 シナリオを想像してみてください。チームは、多様なソースからの大規模なデータセットに圧倒されます。 意味のあるプレゼンテーションのためにこの情報を統合、並べ替え、分析することは課題です。これは、パワーバイセマンティックモデル(PBISM)Ex
 Llama IndexとMonsterapiを使用してAIエージェントを構築する方法Apr 15, 2025 am 10:44 AM
Llama IndexとMonsterapiを使用してAIエージェントを構築する方法Apr 15, 2025 am 10:44 AMAIエージェント:LlamaindexとMonsterapiを搭載したAIの未来 AIエージェントは、テクノロジーとの対話方法に革命をもたらす態勢を整えています。 これらの自律システムは、人間の行動を模倣し、推論、意思決定、およびREAを必要とするタスクを実行します
 人間の介入なしでLLMを訓練する7つの方法Apr 15, 2025 am 10:38 AM
人間の介入なしでLLMを訓練する7つの方法Apr 15, 2025 am 10:38 AM自律AIのロック解除:自己トレーニングLLMの7つの方法 子どもたちが複雑な概念を独立して習得するように、AIシステムが人間の介入なしに学び、進化する未来を想像してください。これはサイエンスフィクションではありません。それは自己の約束です
 AIおよびNLGによる財務報告の変革-AnalyticsVidhyaApr 15, 2025 am 10:35 AM
AIおよびNLGによる財務報告の変革-AnalyticsVidhyaApr 15, 2025 am 10:35 AMAI搭載の財務報告:自然言語生成による洞察の革命 今日のダイナミックなビジネス環境では、戦略的意思決定には正確でタイムリーな財務分析が最重要です。 従来の財務報告
 このGoogle Deepmindロボットは、2028年のオリンピックでプレイしますか?Apr 15, 2025 am 10:16 AM
このGoogle Deepmindロボットは、2028年のオリンピックでプレイしますか?Apr 15, 2025 am 10:16 AMGoogle Deepmind's Table Tennis Robot:スポーツとロボット工学の新しい時代 パリ2024年のオリンピックは終わったかもしれませんが、Google Deepmindのおかげで、スポーツとロボット工学の新しい時代が夜明けです。 彼らの画期的な研究(「「人間レベルの競争を達成する」


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

VSCode Windows 64 ビットのダウンロード
Microsoft によって発売された無料で強力な IDE エディター

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

ドリームウィーバー CS6
ビジュアル Web 開発ツール

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

