


ラージモデルテクノロジーの開発と実装に伴い、「モデルガバナンス」が現在大きな注目を集めている命題となっています。しかし、実際には、研究者は複数の課題に直面することがよくあります。
一方で、ターゲット タスクのパフォーマンスを向上させるために、研究者はターゲット タスク データ セットを収集して構築し、大規模言語モデル (LLM) を微調整します。この方法では、通常、ターゲット タスク以外の一般タスクのパフォーマンスが大幅に低下し、LLM の本来の一般的な機能が損なわれます。
一方、オープンソース コミュニティのモデルの数は徐々に増加しており、大規模なモデル開発者は複数のトレーニングでより多くのモデルを蓄積する可能性もあり、各モデルには独自のモデルがあります。利点としては、タスクを実行するために適切なモデルを選択する方法、またはタスクをさらに微調整する方法が問題になります。
最近、Zhiyuan Research Institute の情報検索およびナレッジ コンピューティング グループは、大規模モデル開発者に低コストのモデル ガバナンスを提供することを目的とした LM-Cocktail モデル ガバナンス戦略 を発表しました。モデルのパフォーマンスを向上させる持続可能な方法: 少数のサンプルを通じて融合重みを計算し、モデル融合テクノロジーを使用して、微調整されたモデルと元のモデルの利点を組み合わせて、「モデル リソース」の効率的な使用を実現します。

- 技術レポート: https://arxiv.org/abs/2311.13534
- コード: https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail
LM カクテル戦略はカクテルを作るのと似ており、各モデルの利点と機能を組み合わせ、異なるモデルをブレンドすることで独自のモデルを作成できます。複数の専門性を備えた「多用途」モデル
手法の革新
具体的には、LM-Cocktail はモデル構成を手動で選択することができます。少数のサンプルを使用して重み付けされた重みを自動的に計算し、既存のモデルを融合して新しいモデルを生成しますこのプロセスにはモデルの再トレーニングは必要なく、大規模な言語モデル Llama、セマンティック ベクトル モデル BGE などの複数の構造に適応できるモデルが含まれています他。
開発者に特定のターゲット タスクのラベル データが不足している場合、またはモデルの微調整のためのコンピューティング リソースが不足している場合は、LM-Cocktail 戦略を使用してモデルの微調整のステップを排除できます。非常に少量のデータ サンプルを構築するだけでよく、オープン ソース コミュニティの既存の大規模言語モデルを統合して、独自の「LM カクテル」を準備できます
 上の図に示すように、特定のターゲット タスクで Llama を微調整すると、ターゲット タスクの精度が大幅に向上しますが、他のタスクの一般的な能力は損なわれます。 LM-Cocktailを採用することでこの問題を解決できます。
上の図に示すように、特定のターゲット タスクで Llama を微調整すると、ターゲット タスクの精度が大幅に向上しますが、他のタスクの一般的な能力は損なわれます。 LM-Cocktailを採用することでこの問題を解決できます。
LM-Cocktail の核心は、微調整されたモデルを他の複数のモデルのパラメーターと融合し、複数のモデルの利点を統合しながら、ターゲット タスクの精度を向上させることです。他のタスクに関する一般的な能力を維持します。具体的な形式としては、対象となるタスク、基本モデル、およびそのタスクに対して基本モデルを微調整したモデルが与えられ、オープンソースコミュニティからモデルや事前にトレーニングされたモデルを収集してコレクションを形成します。ターゲットタスクの少数のサンプルを通じて各モデルの融合重みを計算し、これらのモデルのパラメータの加重和を実行して新しいモデルを取得します(具体的なプロセスについては、論文またはオープンソースコードを参照してください) 。オープンソース コミュニティに他のモデルが存在しない場合は、基本モデルと微調整モデルを直接統合して、一般的な機能を低下させることなく下流タスクのパフォーマンスを向上させることもできます。
実際のアプリケーション シナリオでは、データとリソースの制限により、ユーザーは下流のタスクを微調整できない場合があります。つまり、微調整されたモデルがありません。対象のタスク。この場合、ユーザーは非常に少量のデータ サンプルを構築し、コミュニティ内の既存の大規模な言語モデルを統合して、新しいタスク用のモデルを生成し、モデルをトレーニングすることなくターゲット タスクの精度を向上させることができます。
実験結果
1. 一般的な機能を維持するための柔軟な微調整
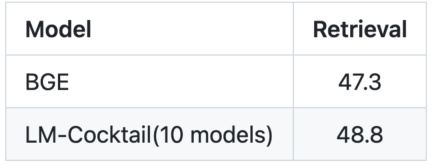
上の図からわかるように、特定のターゲット タスクを微調整した後、微調整されたモデルによってそのタスクの精度は大幅に向上しますが、他の精度は向上しません。一般的なタスクでは減少します。たとえば、AG News トレーニング セットで微調整を行った後、AG News テスト セットでの Llama の精度は 40.80% から 94.42% に増加しましたが、他のタスクでの精度は 46.80% から 38.58% に低下しました。 ただし、微調整モデルと元のモデルのパラメータを単純に融合するだけで、ターゲット タスクに関して 94.46% の競合パフォーマンスが達成され、これは微調整モデルと同等です。調整されたモデルは、他のタスクでは 94.46% の競争力のあるパフォーマンスを達成し、精度は 47.73% で、元のモデルのパフォーマンスよりわずかに優れています。 Helleswag などの特定のタスクの下では、融合モデルは、この微調整タスクでは微調整モデルを超え、他のタスクでは元の一般モデルを超えることさえあります。オリジナルモデルを超えています。 LM-Cocktail を通じて融合率を計算し、他の微調整されたモデルをさらに統合すると、ターゲット タスクの精度を確保しながら、他のタスクの全体的なパフォーマンスをさらに向上させることができることがわかります。 2. 既存のモデルを組み合わせて新しいタスクを処理する リライト以下の内容: グラフは言語モデル MMLU のターゲット タスクを示しています。書き換えられた内容: 画像: ベクトル モデルのターゲット タスクは次のとおりです。 retrieve (情報取得) モデルの微調整には、大量のデータと大量のコンピューティング リソースが必要です。特に大規模な言語モデルの微調整には、これは不可能な場合があります。実際の状況。ターゲット タスクを微調整できない場合、LM-Cocktail は既存のモデル (オープンソース コミュニティまたは独自の過去のトレーニングの蓄積から) を混合することで新しい機能を実現できます。 LM-Cocktail は、わずか 5 個のサンプル データを与えるだけで、大量のデータを使用することなく自動的に融合重みを計算し、既存のモデルをフィルタリングして融合して新しいモデルを取得します。トレーニングを実施します。実験の結果、生成された新しいモデルは新しいタスクでより高い精度を達成できることがわかりました。たとえば、Llama の場合、LM-Cocktail を使用して 10 個の既存のモデル (そのトレーニング タスクは MMLU リストに関連しない) を融合することで大幅な改善を達成でき、5 つのサンプル データを使用する Llama モデルよりも優れています。コンテキスト学習。 LM-Cocktail をお試しください。GitHub の問題を介してフィードバックや提案を歓迎します: https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail 

以上がZhiyuanとその他の機関は、LM-Cocktailモデルのマルチスキル大規模モデルガバナンス戦略を発表の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 最高の迅速なエンジニアリング技術の最新の年次編集Apr 10, 2025 am 11:22 AM
最高の迅速なエンジニアリング技術の最新の年次編集Apr 10, 2025 am 11:22 AM私のコラムに新しいかもしれない人のために、具体化されたAI、AI推論、AIのハイテクブレークスルー、AIの迅速なエンジニアリング、AIのトレーニング、AIのフィールディングなどのトピックなど、全面的なAIの最新の進歩を広く探求します。
 ヨーロッパのAI大陸行動計画:GigaFactories、Data Labs、Green AIApr 10, 2025 am 11:21 AM
ヨーロッパのAI大陸行動計画:GigaFactories、Data Labs、Green AIApr 10, 2025 am 11:21 AMヨーロッパの野心的なAI大陸行動計画は、人工知能のグローバルリーダーとしてEUを確立することを目指しています。 重要な要素は、AI GigaFactoriesのネットワークの作成であり、それぞれが約100,000の高度なAIチップを収容しています。
 Microsoftの簡単なエージェントストーリーは、より多くのファンを作成するのに十分ですか?Apr 10, 2025 am 11:20 AM
Microsoftの簡単なエージェントストーリーは、より多くのファンを作成するのに十分ですか?Apr 10, 2025 am 11:20 AMAIエージェントアプリケーションに対するMicrosoftの統一アプローチ:企業の明確な勝利 新しいAIエージェント機能に関するマイクロソフトの最近の発表は、その明確で統一されたプレゼンテーションに感銘を受けました。 TEで行き詰まった多くのハイテクアナウンスとは異なり
 従業員へのAI戦略の販売:Shopify CEOのマニフェストApr 10, 2025 am 11:19 AM
従業員へのAI戦略の販売:Shopify CEOのマニフェストApr 10, 2025 am 11:19 AMShopify CEOのTobiLütkeの最近のメモは、AIの能力がすべての従業員にとって基本的な期待であると大胆に宣言し、会社内の重大な文化的変化を示しています。 これはつかの間の傾向ではありません。これは、pに統合された新しい運用パラダイムです
 IBMは、完全なAI統合でZ17メインフレームを起動しますApr 10, 2025 am 11:18 AM
IBMは、完全なAI統合でZ17メインフレームを起動しますApr 10, 2025 am 11:18 AMIBMのZ17メインフレーム:AIを強化した事業運営の統合 先月、IBMのニューヨーク本社で、Z17の機能のプレビューを受け取りました。 Z16の成功に基づいて構築(2022年に開始され、持続的な収益の成長の実証
 5 chatgptプロンプトは他の人に依存して停止し、自分を完全に信頼するApr 10, 2025 am 11:17 AM
5 chatgptプロンプトは他の人に依存して停止し、自分を完全に信頼するApr 10, 2025 am 11:17 AM揺るぎない自信のロックを解除し、外部検証の必要性を排除します! これらの5つのCHATGPTプロンプトは、完全な自立と自己認識の変革的な変化に向けて導きます。 ブラケットをコピー、貼り付け、カスタマイズするだけです
 AIはあなたの心に危険なほど似ていますApr 10, 2025 am 11:16 AM
AIはあなたの心に危険なほど似ていますApr 10, 2025 am 11:16 AM人工知能のセキュリティおよび研究会社であるAnthropicによる最近の[研究]は、これらの複雑なプロセスについての真実を明らかにし始め、私たち自身の認知領域に不穏に似た複雑さを示しています。自然知能と人工知能は、私たちが思っているよりも似ているかもしれません。 内部スヌーピング:人類の解釈可能性研究 人類によって行われた研究からの新しい発見は、AIの内部コンピューティングをリバースエンジニアリングすることを目的とする機械的解釈可能性の分野の大きな進歩を表しています。AIが何をするかを観察するだけでなく、人工ニューロンレベルでそれがどのように行うかを理解します。 誰かが特定のオブジェクトを見たり、特定のアイデアについて考えたりしたときに、どのニューロンが発射するかを描くことによって脳を理解しようとすることを想像してください。 a
 Dragonwingは、QualcommのEdge Momentumを紹介していますApr 10, 2025 am 11:14 AM
Dragonwingは、QualcommのEdge Momentumを紹介していますApr 10, 2025 am 11:14 AMQualcomm's DragonWing:企業とインフラストラクチャへの戦略的な飛躍 Qualcommは、新しいDragonwingブランドで世界的に企業やインフラ市場をターゲットにして、モバイルを超えてリーチを積極的に拡大しています。 これは単なるレブランではありません


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

PhpStorm Mac バージョン
最新(2018.2.1)のプロフェッショナル向けPHP統合開発ツール

Dreamweaver Mac版
ビジュアル Web 開発ツール

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

MantisBT
Mantis は、製品の欠陥追跡を支援するために設計された、導入が簡単な Web ベースの欠陥追跡ツールです。 PHP、MySQL、Web サーバーが必要です。デモおよびホスティング サービスをチェックしてください。

SublimeText3 中国語版
中国語版、とても使いやすい
ホットトピック
 7454
7454 15137552
15137552