

 テクノロジー周辺機器AIMicrosoft は、「プロンプト プロジェクト」だけで GPT-4 を医療専門家に変えました。十数種類の高度に微調整されたモデルにより、プロによるテスト精度が初めて 90% を超えました
テクノロジー周辺機器AIMicrosoft は、「プロンプト プロジェクト」だけで GPT-4 を医療専門家に変えました。十数種類の高度に微調整されたモデルにより、プロによるテスト精度が初めて 90% を超えましたMicrosoft は、「プロンプト プロジェクト」だけで GPT-4 を医療専門家に変えました。十数種類の高度に微調整されたモデルにより、プロによるテスト精度が初めて 90% を超えました

Microsoft の最新の研究は、プロンプト プロジェクト -
追加の微調整や専門家による計画を行わなくても、GPT-4 はプロンプトだけで「エキスパート」になることができることを再度証明しています。
彼らが提案した最新のプロンプト戦略 Medprompt を使用して、医療専門家の分野では、GPT-4 は MultiMed QA の 9 つのテスト セットで最高の結果を達成しました。
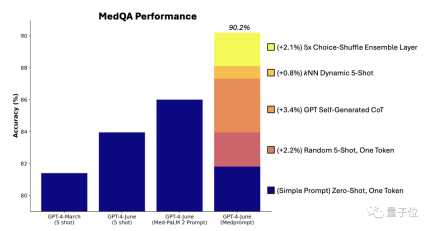
MedQA データセット (米国医師免許試験問題) において、Medprompt は GPT-4 の精度を初めて 90% を超え、 は BioGPT および Med-PaLM# を上回りました。 ## 多数の微調整方法を待っています。
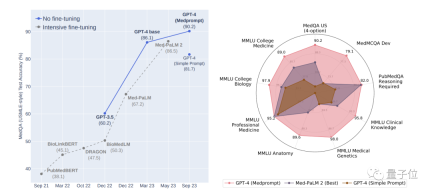



GPT-4 は業界を変えることができるテクノロジーですが、まだ遠いです離れています プロンプトの制限に達しておらず、微調整の制限にも達していません。

- ダイナミックな数ショット選択
- 自己生成の思考連鎖
- 選択シャッフルアンサンブル)

固定であるため、例の代表性と幅広さについては高い要件が求められます。
以前の方法は、ドメインの専門家が手動でサンプルを作成するというものでしたですが、それでも、専門家が厳選した固定の少数サンプルのサンプルが各タスクを代表するものであるという保証はありません。
マイクロソフトの研究者は、動的少数ショット例の方法を提案しました。したがって、アイデアは、タスク トレーニング セットを少数ショット例のソースとして使用できるということです。が十分に大きい場合、さまざまなタスク入力に対してさまざまな数ショットの例を選択できます。 具体的な操作に関しては、研究者らはまず text-embedding-ada-002 モデルを使用して、各トレーニング サンプルとテスト サンプルのベクトル表現を生成しました。次に、各テスト サンプルについて、ベクトルの類似性を比較することにより、最も類似した k 個のサンプルがトレーニング サンプルから選択されます。微調整方法と比較して、動的少数ショット選択はトレーニングを利用します。ただし、モデルパラメータの大規模な更新は必要ありません。 自己生成の思考連鎖思考連鎖 (CoT) メソッドは、モデルに段階的に思考させ、一連の中間推論ステップを生成させるメソッドですこれまでの方法は専門家に依存していました 迅速な思考連鎖を備えたいくつかの例を手動で作成しました
ここで、研究者らは、次のプロンプトを使用して、GPT-4 にトレーニング例の思考連鎖を生成するよう簡単に依頼できることを発見しました:

しかし、研究者らは、この自動的に生成された思考チェーンには間違った推論ステップが含まれている可能性があるとも指摘したため、効果的にエラーを減らすことができるフィルターとして検証タグを設定しました。
Med-PaLM 2 モデルの専門家によって手作りされた思考チェーンの例と比較して、GPT-4 によって生成された思考チェーンの基本原理は長く、段階的な推論ロジックは次のとおりです。よりきめ細かい。
オプション シャッフル統合
GPT-4 は、多肢選択問題を扱うときにバイアスがある可能性があります。つまり、質問の内容に関係なく、常に A を選択するか、常に B を選択する傾向があります。オプションは、これは位置の偏差です。
この問題を解決するために、研究者たちは元のオプションの順序を並べ替えて影響を軽減することにしました。たとえば、元のオプションの順序は ABCD ですが、BCDA、CDAB などに変更できます。
次に、各ラウンドで異なるオプションの順序を使用して、GPT-4 に複数のラウンドの予測を実行させます。これにより、GPT-4 はオプションの内容を考慮するように「強制」されます。
最後に、複数ラウンドの予測の結果に投票し、最も一貫性があり正しい選択肢を選択します。
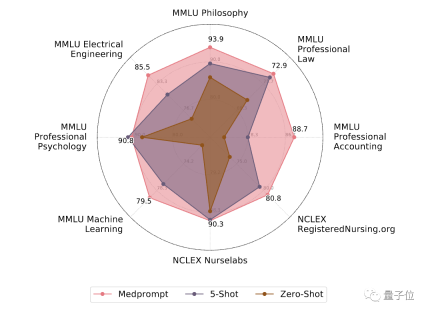
上記のプロンプト戦略を組み合わせたものが Medprompt です。テスト結果を見てみましょう。
最適な複数テスト
このテストでは、研究者は MultiMed QA 評価ベンチマークを使用しました。

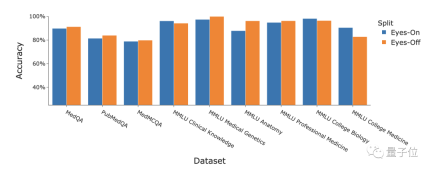
Medprompt プロンプト戦略を使用する GPT-4 は、MultiMedQA の 9 つのベンチマーク データ セットすべてで最高スコアを達成し、Flan-PaLM 540B および Med-PaLM 2 よりも優れています。 。
さらに、研究者らは、「アイズオフ」データに対する Medprompt 戦略のパフォーマンスについても議論しました。いわゆる「アイズオフ」データとは、トレーニングまたは最適化プロセス中にモデルが一度も見たことのないデータを指し、モデルがトレーニング データを過学習しているかどうかをテストするために使用されます


論文を表示するには、次のリンクをクリックしてください: https://arxiv.org/pdf/2311.16452.pdf
以上がMicrosoft は、「プロンプト プロジェクト」だけで GPT-4 を医療専門家に変えました。十数種類の高度に微調整されたモデルにより、プロによるテスト精度が初めて 90% を超えましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 Gemma Scope:AI'の思考プロセスを覗くためのGoogle'の顕微鏡Apr 17, 2025 am 11:55 AM
Gemma Scope:AI'の思考プロセスを覗くためのGoogle'の顕微鏡Apr 17, 2025 am 11:55 AMジェマの範囲で言語モデルの内部の仕組みを探る AI言語モデルの複雑さを理解することは、重要な課題です。 包括的なツールキットであるGemma ScopeのGoogleのリリースは、研究者に掘り下げる強力な方法を提供します
 ビジネスインテリジェンスアナリストは誰で、どのようになるか?Apr 17, 2025 am 11:44 AM
ビジネスインテリジェンスアナリストは誰で、どのようになるか?Apr 17, 2025 am 11:44 AMビジネスの成功のロック解除:ビジネスインテリジェンスアナリストになるためのガイド 生データを組織の成長を促進する実用的な洞察に変換することを想像してください。 これはビジネスインテリジェンス(BI)アナリストの力です - GUにおける重要な役割
 SQLに列を追加する方法は? - 分析VidhyaApr 17, 2025 am 11:43 AM
SQLに列を追加する方法は? - 分析VidhyaApr 17, 2025 am 11:43 AMSQLの変更テーブルステートメント:データベースに列を動的に追加する データ管理では、SQLの適応性が重要です。 その場でデータベース構造を調整する必要がありますか? Alter Tableステートメントはあなたの解決策です。このガイドの詳細は、コルを追加します
 ビジネスアナリストとデータアナリストApr 17, 2025 am 11:38 AM
ビジネスアナリストとデータアナリストApr 17, 2025 am 11:38 AM導入 2人の専門家が重要なプロジェクトで協力している賑やかなオフィスを想像してください。 ビジネスアナリストは、会社の目標に焦点を当て、改善の分野を特定し、市場動向との戦略的整合を確保しています。 シム
 ExcelのCountとCountaとは何ですか? - 分析VidhyaApr 17, 2025 am 11:34 AM
ExcelのCountとCountaとは何ですか? - 分析VidhyaApr 17, 2025 am 11:34 AMExcelデータカウントと分析:カウントとカウントの機能の詳細な説明 特に大規模なデータセットを使用する場合、Excelでは、正確なデータカウントと分析が重要です。 Excelは、これを達成するためにさまざまな機能を提供し、CountおよびCounta関数は、さまざまな条件下でセルの数をカウントするための重要なツールです。両方の機能はセルをカウントするために使用されますが、設計ターゲットは異なるデータ型をターゲットにしています。 CountおよびCounta機能の特定の詳細を掘り下げ、独自の機能と違いを強調し、データ分析に適用する方法を学びましょう。 キーポイントの概要 カウントとcouを理解します
 ChromeはAIと一緒にここにいます:毎日何か新しいことを体験してください!!Apr 17, 2025 am 11:29 AM
ChromeはAIと一緒にここにいます:毎日何か新しいことを体験してください!!Apr 17, 2025 am 11:29 AMGoogle Chrome'sAI Revolution:パーソナライズされた効率的なブラウジングエクスペリエンス 人工知能(AI)は私たちの日常生活を急速に変換しており、Google ChromeはWebブラウジングアリーナで料金をリードしています。 この記事では、興奮を探ります
 ai' s Human Side:Wellbeing and the Quadruple bottuntApr 17, 2025 am 11:28 AM
ai' s Human Side:Wellbeing and the Quadruple bottuntApr 17, 2025 am 11:28 AMインパクトの再考:四重材のボトムライン 長い間、会話はAIの影響の狭い見方に支配されており、主に利益の最終ラインに焦点を当てています。ただし、より全体的なアプローチは、BUの相互接続性を認識しています
 5ゲームを変える量子コンピューティングの使用ケースあなたが知っておくべきであるApr 17, 2025 am 11:24 AM
5ゲームを変える量子コンピューティングの使用ケースあなたが知っておくべきであるApr 17, 2025 am 11:24 AM物事はその点に向かって着実に動いています。量子サービスプロバイダーとスタートアップに投資する投資は、業界がその重要性を理解していることを示しています。そして、その価値を示すために、現実世界のユースケースの数が増えています


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

Safe Exam Browser
Safe Exam Browser は、オンライン試験を安全に受験するための安全なブラウザ環境です。このソフトウェアは、あらゆるコンピュータを安全なワークステーションに変えます。あらゆるユーティリティへのアクセスを制御し、学生が無許可のリソースを使用するのを防ぎます。

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

MinGW - Minimalist GNU for Windows
このプロジェクトは osdn.net/projects/mingw に移行中です。引き続きそこでフォローしていただけます。 MinGW: GNU Compiler Collection (GCC) のネイティブ Windows ポートであり、ネイティブ Windows アプリケーションを構築するための自由に配布可能なインポート ライブラリとヘッダー ファイルであり、C99 機能をサポートする MSVC ランタイムの拡張機能が含まれています。すべての MinGW ソフトウェアは 64 ビット Windows プラットフォームで実行できます。

ドリームウィーバー CS6
ビジュアル Web 開発ツール

