
ホームページ >テクノロジー周辺機器 >AI >Sparse4D v3 が登場しました!エンドツーエンドの 3D 検出と追跡の進歩
Sparse4D v3 が登場しました!エンドツーエンドの 3D 検出と追跡の進歩

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-11-24 11:21:35878ブラウズ
新しいタイトル: Sparse4D v3: エンドツーエンドの 3D 検出および追跡テクノロジの進歩
紙のリンク: https://arxiv.org/pdf/2311.11722.pdf
必要書き換えられる内容は次のとおりです: コードリンク: https://github.com/linxuewu/Sparse4D
書き換えられた内容: 著者の所属は Horizon Companyです

論文のアイデア:
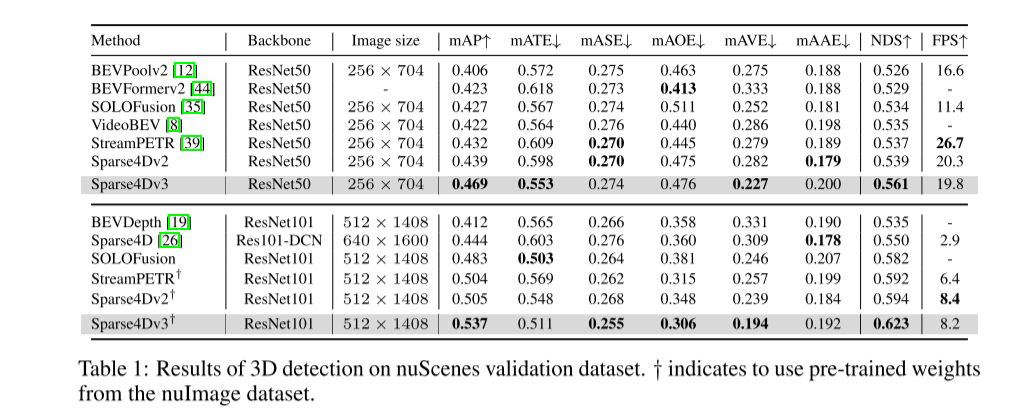
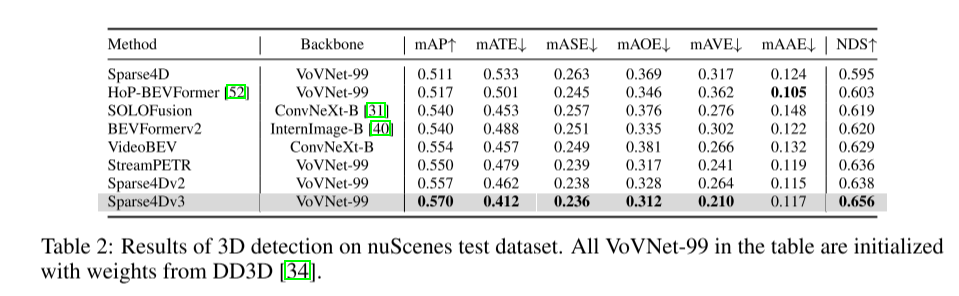
自動運転認識システムでは、3D 検出と追跡が 2 つの基本的なタスクです。この記事では、Sparse4D フレームワークに基づいてこの領域を詳しく説明します。この記事では、2 つの補助トレーニング タスク (時間的インスタンスのノイズ除去 - 時間的インスタンスのノイズ除去と品質推定 - 品質推定) を紹介し、構造改善のための分離された注意 (分離された注意) を提案します。これにより、検出パフォーマンスが大幅に向上します。さらに、この論文では、推論中にインスタンス ID を割り当てる簡単な方法を使用して検出器をトラッカーに拡張し、クエリベースのアルゴリズムの利点をさらに強調しています。 nuScenes ベンチマークに関する広範な実験により、提案された改善の有効性が検証されます。 ResNet50 をバックボーンとして使用すると、mAP、NDS、AMOTA はそれぞれ 3.0%、2.2%、7.6% 増加し、それぞれ 46.9%、56.1%、49.0% に達しました。この記事の最良のモデルは、nuScenes テスト セットで 71.9% の NDS と 67.7% の AMOTA を達成しました。
主な貢献:
Sparse4D-v3 は強力な 3D 認識フレームワークです。これは、時間的インスタンスのノイズ除去、品質推定、および分離された注意という 3 つの効果的な戦略を提案しています。
この記事では、Sparse4D をエンドツーエンドの追跡モデルに拡張します。
このペーパーでは、検出および追跡タスクにおいて最先端のパフォーマンスを実現する、nuScenes の改善の有効性を実証します。
ネットワーク設計:
まず、疎アルゴリズムは密アルゴリズムと比較して収束において大きな課題に直面し、最終的なパフォーマンスに影響を与えることが観察されています。この問題は、主にスパース アルゴリズムが 1 対 1 のポジティブ サンプル マッチングを使用するため、2D 検出の分野でよく研究されています [17、48、53]。このマッチング方法はトレーニングの初期段階では不安定であり、1 対多のマッチングと比較して、正のサンプルの数が制限されるため、デコーダのトレーニングの効率が低下します。さらに、Sparse4D はグローバル クロス アテンションの代わりにスパース特徴サンプリングを使用します。これにより、正のサンプルが不足するため、エンコーダーの収束がさらに妨げられます。 Sparse4Dv2 では、画像エンコーダが直面するこれらの収束問題を部分的に軽減するために、高密度の深い監視が導入されています。このペーパーの主な目的は、デコーダ トレーニングの安定性に焦点を当ててモデルのパフォーマンスを向上させることです。この論文では、補助監視としてノイズ除去タスクを使用し、ノイズ除去技術を 2D 単一フレーム検出から 3D 時間検出に拡張します。これにより、安定した陽性サンプルのマッチングが保証されるだけでなく、陽性サンプルの数も大幅に増加します。さらに補助監督として品質評価業務も導入した。これにより、出力される信頼度スコアがより合理的となり、検出結果のランキング精度が向上し、より高い評価指標が得られる。さらに、この記事では、Sparse4D のインスタンスのセルフ アテンション モジュールと時間的クロス アテンション モジュールの構造を改善し、アテンションの重み計算プロセスにおける特徴の干渉を減らすことを目的とした分離されたアテンション メカニズムを導入します。アンカーの埋め込みとインスタンスの特徴をアテンション計算への入力として使用することで、アテンションの重みに外れ値を持つインスタンスを減らすことができます。これにより、対象の特徴間の相関関係がより正確に反映され、正確な特徴の集約が実現されます。このペーパーでは、アテンション メカニズムの代わりに接続を使用して、このエラーを大幅に削減します。この拡張方法は条件付き DETR と類似点がありますが、主な違いは、この論文ではクエリ間の注意に重点を置いているのに対し、条件付き DETR はクエリと画像特徴間の相互注意に焦点を当てていることです。さらに、この記事には独自のエンコード方法も含まれています
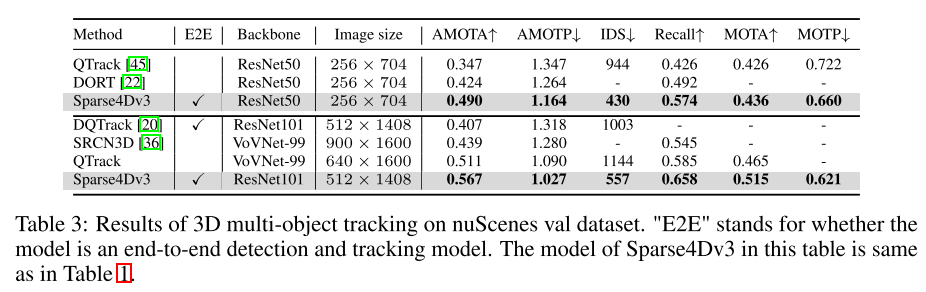
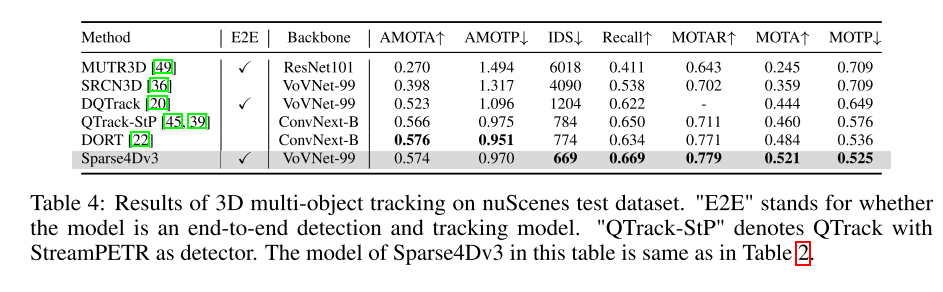
知覚システムのエンドツーエンド機能を向上させるために、この記事では 3D マルチターゲット追跡タスクを Sparse4D フレームワークに統合する方法を研究します。ターゲットの運動軌跡を直接出力します。検出ベースの追跡方法とは異なり、この論文では、データの関連付けとフィルタリングの必要性を排除することで、すべての追跡機能を検出器に統合します。さらに、既存の共同検出および追跡方法とは異なり、当社のトラッカーはトレーニング中に損失関数を変更または調整する必要がありません。グラウンド トゥルース ID を提供する必要はありませんが、事前定義されたインスタンスからトラックへの回帰を実装します。この記事の追跡実装では、検出器とトラッカーが完全に統合されており、検出器のトレーニング プロセスを変更したり、追加の微調整を行う必要はありません。
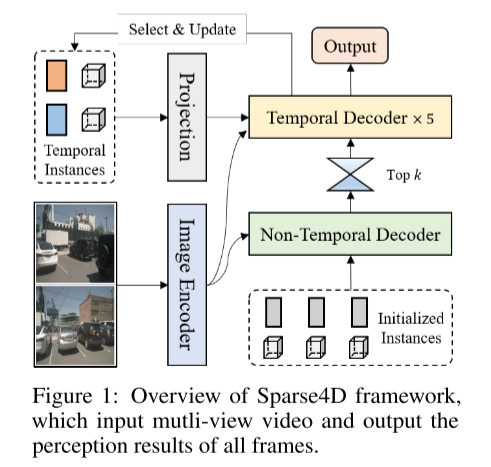
これは、検出器とトラッカーについての図 1 です。 Sparse4D フレームワークの概要、入力はマルチビュー ビデオ、出力はすべてのフレームの知覚結果です
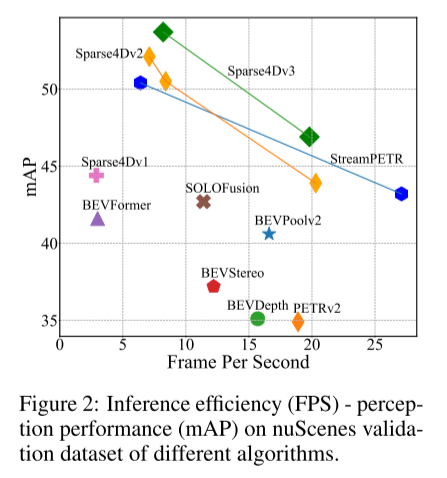
図 2: 推論効率 (FPS) - 知覚さまざまなアルゴリズム (mAP) の nuScenes 検証データ セットのパフォーマンス (FPS)。

図 3: インスタンスの自己注意における注意の重みの視覚化: 1) 最初の行は、通常の自己注意における注意の重みを示します。ここでは、赤い円内の歩行者がターゲット車両 (緑色) と一列に並んでいることが示されています。ボックス)予期せぬ相関関係。 2) 2 行目は、この問題を効果的に解決する、分離された注意における注意の重みを示します。
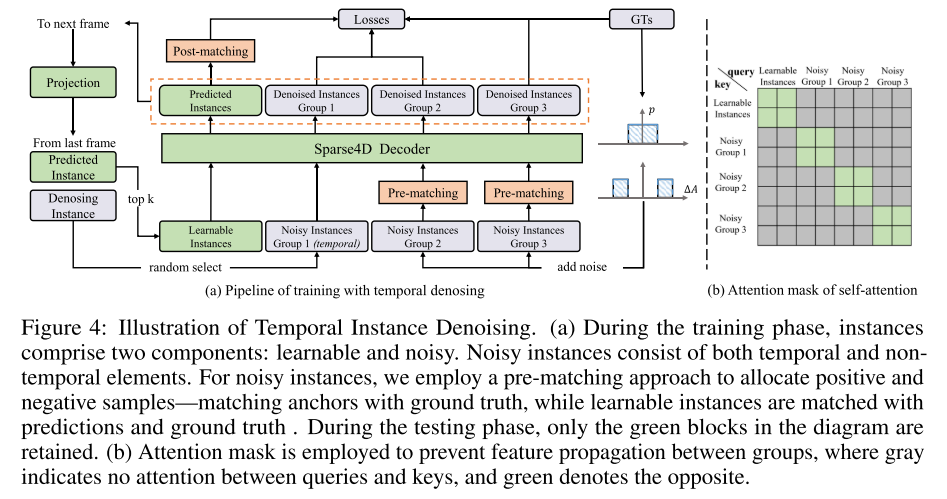
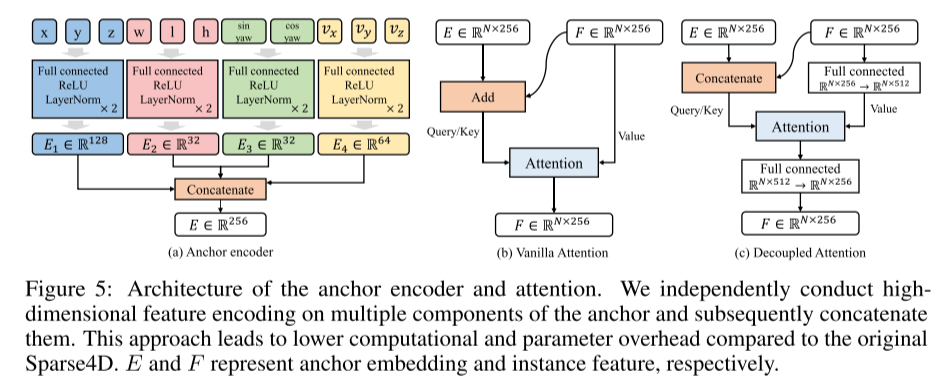
4 番目の図は、時系列インスタンスのノイズ除去の例を示しています。トレーニング段階では、インスタンスは学習可能な部分とノイズの多い部分の 2 つの部分で構成されます。ノイズ インスタンスは、時間的要素と非時間的要素で構成されます。この論文では、正と負のサンプルを割り当てる事前マッチング方法を採用しています。つまり、アンカーをグラウンド トゥルースと照合し、学習可能なインスタンスは予測とグラウンド トゥルースと照合されます。テスト段階では、緑色のブロックのみが残ります。機能がグループ間で拡散するのを防ぐために、アテンション マスクが使用されます。灰色はクエリとキーの間にアテンションがないことを示し、緑色はその逆を示します。図 5: エンコーダと注意のためのアンカー ポイントのアーキテクチャを参照してください。本論文では、アンカーの複数の構成要素の高次元特徴を独立して符号化し、それらを連結します。このアプローチにより、元の Sparse4D と比較して計算とパラメーターのオーバーヘッドが削減されます。 E と F はそれぞれアンカーの埋め込み機能とインスタンス機能を表します

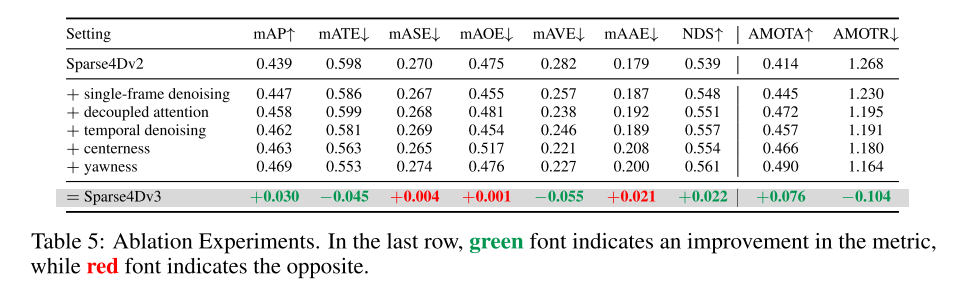 概要:
概要: 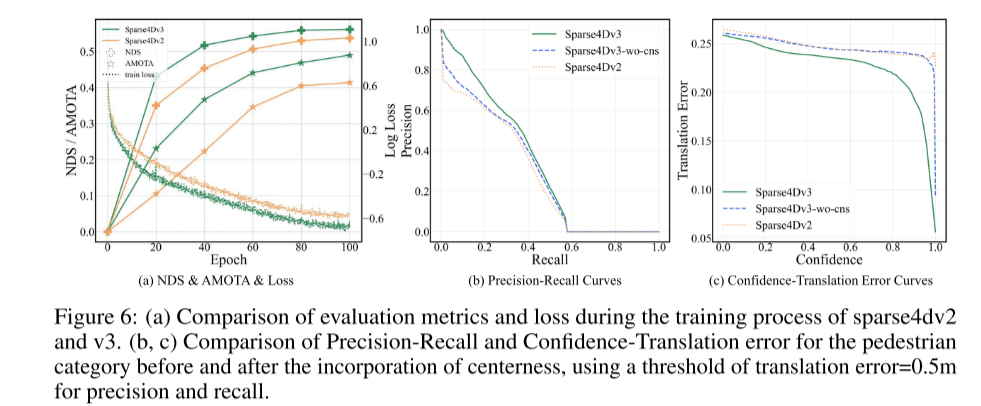
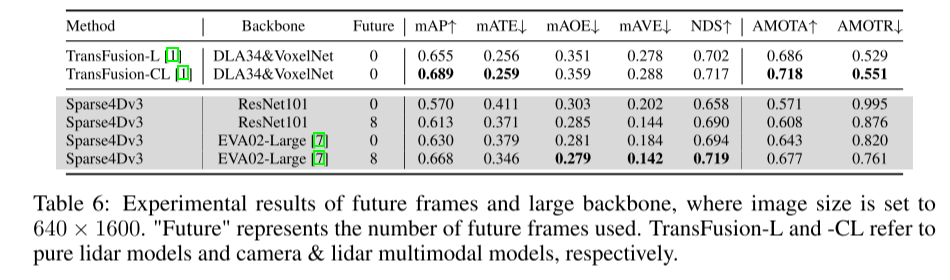
引用:
Lin, X.、Pei, Z.、Lin, T.、Huang, L.、および Su, Z. (2023). Sparse4D v3: エンドツーエンドの 3D 検出と追跡の進歩.ArXiv. /abs/2311.11722
以上がSparse4D v3 が登場しました!エンドツーエンドの 3D 検出と追跡の進歩の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。