



この記事を転載する許可を得るには、ソースに連絡してください。この記事は、自動運転ハートの公開アカウントによって公開されました。
1 はじめに
More モーダル センサー フュージョンは、補完的で安定した安全な情報を意味し、長い間自動運転認識の重要な部分を占めてきました。しかし、不十分な情報利用、元のデータのノイズ、さまざまなセンサー間の不整合 (タイムスタンプの同期外れなど) により、融合パフォーマンスが制限されています。この記事では、ターゲット検出とセマンティック セグメンテーションに焦点を当て、LiDAR やカメラを含む既存のマルチモーダル自動運転認識アルゴリズムを包括的に調査し、50 を超えるドキュメントを分析します。融合アルゴリズムの従来の分類方法とは異なり、この論文では、この分野をさまざまな融合段階に基づいて 2 つの主要カテゴリと 4 つのサブカテゴリに分類します。さらに、この記事は現在の分野に存在する問題を分析し、将来の研究の方向性への参考を提供します。
2 なぜマルチモダリティが必要なのでしょうか?
これは、シングルモーダル認識アルゴリズムには固有の欠陥があるためです。たとえば、LIDAR は通常、カメラよりも高い位置に設置されますが、現実の複雑な運転シナリオでは、物体がフロントビュー カメラに遮られる場合がありますが、この場合、LIDAR を使用して行方不明の目標を捕捉することが可能です。ただし、LiDAR は機械構造の制限により、距離が異なると解像度が異なり、大雨などの非常に厳しい天候の影響を受けやすくなります。どちらのセンサーも単独で使用すると非常に優れた性能を発揮しますが、将来的には、LiDAR とカメラの補完的な情報により、自動運転が知覚レベルでより安全になるでしょう。
最近、自動運転のためのマルチモーダル認識アルゴリズムが大きく進歩しました。これらの進歩には、クロスモーダル特徴表現、より信頼性の高いモーダル センサー、より複雑で安定したマルチモーダル融合アルゴリズムと技術が含まれます。しかし、マルチモーダルフュージョンの方法論自体に焦点を当てているレビューは少数しかなく [15、81]、ほとんどの文献は伝統的な分類ルール、つまりフュージョン前、ディープ (フィーチャー) フュージョン、フュージョン後、に従って分類されています。データ レベル、機能レベル、提案レベルのいずれであっても、アルゴリズムにおける機能融合の段階に焦点を当てます。この分類ルールには 2 つの問題があります: 1 つ目は、各レベルのフィーチャ表現が明確に定義されていないこと、2 つ目は、LIDAR とカメラの 2 つのブランチを対称的な観点から扱うため、フィーチャ フュージョンとフィーチャ フュージョンの関係があいまいになることです。 LiDAR ブランチ: カメラ ブランチでのデータレベルの機能融合のケース。要約すると、従来の分類方法は直感的ですが、現在のマルチモーダル融合アルゴリズムの開発にはもはや適しておらず、研究者が体系的な観点から研究や分析を行うことがある程度妨げられています。 ##3 タスクとオープンな競争
##一般的な認識タスクには、ターゲット検出、セマンティック セグメンテーション、深さの補完と予測などが含まれます。この記事では、障害物、信号機、交通標識の検出、車線境界線や空き領域のセグメンテーションなど、検出とセグメンテーションに焦点を当てます。自動運転認識タスクは次の図に示されています:一般的な公開データ セットには主に KITTI、Waymo、nuScenes が含まれます。次の図は自動運転に関連するデータ セットをまとめたものです知覚とその特徴

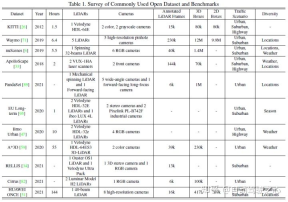
従来の分類方法では、マルチモーダル フュージョンを次の 3 つのタイプに分類します。
プレフュージョン (データレベルのフュージョン) は、さまざまなモダリティの生のセンサー データを直接融合することを指します。空間調整を通じて。
ディープ フュージョン (特徴レベルのフュージョン) は、カスケードまたは要素の乗算による特徴空間内のクロスモーダル データの融合を指します。
- ポストフュージョン (ターゲット レベルのフュージョン) とは、最終的な決定を行うために各モーダル モデルの予測結果を融合することを指します。
- 記事では下図の分類方法を使用しており、大まかに強融合と弱融合に分けられますが、強融合はさらに前方融合、深部融合、非対称融合、後融合に分類できます
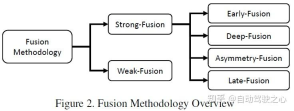
この記事では、KITTI の 3D 検出タスクと BEV 検出タスクを使用して、さまざまなマルチモーダル フュージョン アルゴリズムのパフォーマンスを水平に比較します。次の図は、BEV 検出テスト セットの結果です。 :
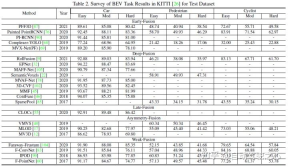
以下は 3D 検出テスト セットの結果の例です:
5 強核融合
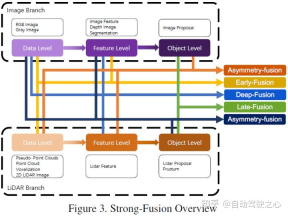
LIDAR とカメラのデータによって表されるさまざまな組み合わせ段階に従って、この記事では強核融合を次のように細分化します。 、深部融合、非対称融合、ポスト融合。上の図に示すように、強力な融合の各サブモジュールは、カメラ データではなく LIDAR 点群に大きく依存していることがわかります。
プレフュージョン
従来のデータレベルのフュージョン定義とは異なり、後者は、空間的な位置合わせと、元のデータレベルでの各モダリティデータの直接フュージョンです。投影 このアプローチでは、早期融合により、LiDAR データがデータ レベルで融合され、カメラ データがデータ レベルまたは機能レベルで融合されます。初期融合の例としては、図 4 のモデルが挙げられます。 書き直された内容: 従来のデータレベル融合定義とは異なり、元のデータレベルでの空間位置合わせと投影を通じて各モダリティデータを直接融合する方法です。早期融合とは、LiDAR データとカメラ データまたは機能レベルのデータをデータ レベルで融合することを指します。図 4 のモデルは、早期融合の例です。
従来の分類方法で定義されるプレフュージョンとは異なり、この記事で定義されるプレフュージョンとは、空間的位置合わせと空間的調整による各モーダル データの直接融合を指します。元のデータ レベルでの投影法であり、前者の融合はデータ レベルでの LiDAR データの融合を指し、データ レベルまたは特徴レベルでの画像データの融合を指します。概略図は次のとおりです。
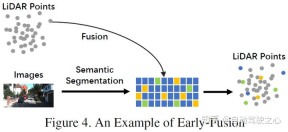 #LiDAR ブランチでは、点群反射マップ、ボクセル化テンソル、正面図/距離図/BEV ビュー、擬似点群など、多くの表現方法があります。これらのデータは、疑似点群 [79] を除き、バックボーン ネットワークごとに異なる固有の特性を持っていますが、ほとんどのデータは特定のルール処理を通じて生成されます。また、これらのLiDARデータは、特徴空間埋め込みに比べて解釈性が高く、直接可視化することができますが、画像ブランチにおいては、厳密な意味でのデータレベルの定義はRGBやグレー画像を指しますが、この定義には普遍性や合理性が欠けています。したがって、この論文では、融合前の段階での画像データのデータレベルの定義を、データレベルと特徴レベルのデータを含むように拡張します。なお、本稿ではセマンティックセグメンテーションの予測結果もプレフュージョン(画像の特徴レベル)の一種として捉えており、3Dターゲットの検出に役立つ一方で、セマンティック セグメンテーションの「ターゲット レベル」の機能。機能は、タスク全体の最終的なターゲット レベルの提案とは異なります。
#LiDAR ブランチでは、点群反射マップ、ボクセル化テンソル、正面図/距離図/BEV ビュー、擬似点群など、多くの表現方法があります。これらのデータは、疑似点群 [79] を除き、バックボーン ネットワークごとに異なる固有の特性を持っていますが、ほとんどのデータは特定のルール処理を通じて生成されます。また、これらのLiDARデータは、特徴空間埋め込みに比べて解釈性が高く、直接可視化することができますが、画像ブランチにおいては、厳密な意味でのデータレベルの定義はRGBやグレー画像を指しますが、この定義には普遍性や合理性が欠けています。したがって、この論文では、融合前の段階での画像データのデータレベルの定義を、データレベルと特徴レベルのデータを含むように拡張します。なお、本稿ではセマンティックセグメンテーションの予測結果もプレフュージョン(画像の特徴レベル)の一種として捉えており、3Dターゲットの検出に役立つ一方で、セマンティック セグメンテーションの「ターゲット レベル」の機能。機能は、タスク全体の最終的なターゲット レベルの提案とは異なります。
ディープ フュージョン。機能とも呼ばれます。 -レベル フュージョン。LIDAR ブランチ Fuse マルチモーダル データのフィーチャ レベルを指しますが、画像ブランチのデータセットとフィーチャ レベルでのことです。たとえば、一部の方法では、特徴リフティングを使用して、LiDAR 点群と画像のそれぞれの埋め込み表現を取得し、一連の下流モジュールを通じて 2 つのモダリティの特徴を融合します。ただし、他の強力な融合とは異なり、ディープ フュージョンは機能をカスケード方式で融合する場合があり、どちらも生の高レベルのセマンティック情報を利用します。概略図は次のとおりです。
#Post-fusion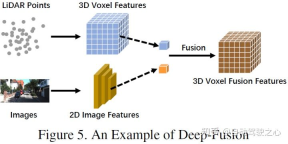
非対称フュージョン
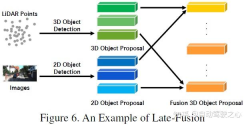
6 弱い融合
と強い融合の違いは、弱い融合手法では、マルチモーダル ブランチからのデータ、特徴、またはターゲットを直接融合するのではなく、データを次の方法で処理することです。他の形態も。以下の図は、弱融合アルゴリズムの基本的な枠組みを示しています。弱融合に基づく方法は、通常、特定のルールベースの方法を使用して、あるモダリティからのデータを監視信号として利用し、別のモダリティの相互作用をガイドします。たとえば、画像ブランチ内の CNN からの 2D プロポーザルは、元の LiDAR 点群で切り捨てを引き起こす可能性があり、弱い融合は、元の LiDAR 点群を LiDAR バックボーンに直接入力して、最終プロポーザルを出力します。
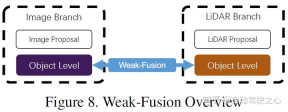
7 他の統合方法
上記のパラダイムのいずれにも属さない作品もあります。 [39] では、ディープフュージョンとポストフュージョンを組み合わせた [39] や、フロントフロントフュージョンを組み合わせた [77] など、さまざまなフュージョン手法が使用されています。これらの手法は融合アルゴリズム設計の主流ではないため、この記事では他の融合手法に分類します。
8 マルチモーダル融合のチャンス
近年、自動運転知覚タスクのためのマルチモーダル融合手法は、より高いレベルの機能から始めて急速に進歩しています。より複雑な深層学習モデルへの表現。しかしながら、解決すべきいくつかの未解決の課題も残されており、本稿では、今後の改善の方向性をいくつかまとめて以下に示します。
より高度な融合方法
現在の融合モデルには、位置ずれと情報損失の問題があります [13、67、98]。さらに、フラット フュージョン操作も、知覚タスクのパフォーマンスのさらなる向上を妨げます。要約は次のとおりです。
- ミスアライメントと情報損失: カメラと LiDAR の間の内部および外部の違いは非常に大きいため、2 つのモードのデータを座標的に揃える必要があります。従来のフロントフュージョンおよびデプスフュージョン方法では、キャリブレーション情報を利用して、すべての LiDAR ポイントをカメラ座標系に直接投影したり、その逆を行ったりします。ただし、設置場所とセンサーのノイズにより、このピクセルごとの位置合わせは十分に正確ではありません。そのため、作品によっては周囲の情報を利用して補完し、より良いパフォーマンスを得る場合もあります。さらに、入力空間と特徴空間の変換プロセス中に他の情報が失われます。通常、次元削減操作の投影では、3D LiDAR 点群を 2D BEV 画像にマッピングする際の高さ情報の損失など、大量の情報損失が必然的に発生します。したがって、元のデータを有効に活用し、情報損失を減らすために、マルチモーダル データを融合用に設計された別の高次元空間にマッピングすることを検討できます。
- より合理的な融合演算: 現在のメソッドの多くは、融合にカスケードまたは要素の乗算を使用します。これらの単純な操作では、大きく異なる分布を持つデータを融合できない可能性があり、2 つのモダリティ間でセマンティックなレッドドッグを適合させることが困難になります。一部の作品では、より複雑なカスケード構造を使用してデータを融合し、パフォーマンスを向上させようとしています。今後の研究では、バイリニアマッピングなどの仕組みも異なる特性を融合できる可能性があり、検討される方向性となります。
マルチソース情報の活用
前向きの単一フレーム画像は、自動運転の知覚タスクの典型的なシナリオです。ただし、ほとんどのフレームワークは限られた情報しか利用できず、運転シナリオの理解を容易にするための補助タスクを詳細に設計していません。要約は次のとおりです。
- より多くの潜在的な情報を使用する: 既存の方法では、複数の側面やソースからの情報を効果的に使用できません。ほとんどは、正面図の単一フレームのマルチモーダル データに焦点を当てています。その結果、セマンティック情報、空間情報、シーン コンテキスト情報など、他の意味のあるデータが十分に活用されなくなります。タスクを支援するためにセマンティック セグメンテーションの結果を使用しようとする作品もあれば、CNN バックボーンの中間層の機能を利用する可能性のあるモデルもあります。自動運転シナリオでは、明示的なセマンティック情報を含む多くの下流タスクにより、車線境界線、信号機、交通標識の検出などの物体検出パフォーマンスが大幅に向上する可能性があります。将来の研究では、下流のタスクを組み合わせて都市シーンの完全な意味理解フレームワークを共同構築し、知覚パフォーマンスを向上させることができます。さらに、[63] にはパフォーマンスを向上させるためにフレーム間情報が組み込まれています。時系列情報にはシリアル化された監視信号が含まれており、単一フレーム方式と比較してより安定した結果を提供できます。したがって、将来の研究では、パフォーマンスのブレークスルーを達成するために、時間的、文脈的、空間的な情報をより深く活用することが検討される可能性があります。
- 自己教師あり表現学習: 相互教師あり信号は、現実世界の同じシーンから異なる角度からサンプリングされたクロスモーダル データに自然に存在します。しかし、データの深い理解が不足しているため、現在の方法ではさまざまなモダリティ間の相互関係を探ることができません。今後の研究では、事前トレーニング、微調整、または対照学習などの自己教師あり学習にマルチモーダル データを使用する方法に焦点を当てることができます。これらの最先端のメカニズムを通じて、フュージョン アルゴリズムは、より優れたパフォーマンスを達成しながら、モデルのデータに対する理解を深めます。
センサー固有の問題
実際のシナリオとセンサーの高さは、ドメインのバイアスと解像度に影響を与える可能性があります。これらの欠点は、自動運転用の深層学習モデルの大規模なトレーニングとリアルタイム操作を妨げます。
- ドメイン バイアス: 自動運転の知覚シナリオでは、さまざまなセンサーによって抽出された生データには、重大なドメイン関連の特徴が伴います。カメラが異なれば光学特性も異なり、LiDAR は機械構造からソリッドステート構造までさまざまです。さらに、同じセンサーで取得されたものであっても、データ自体には、天気、季節、地理的位置などの領域の偏りがあります。これにより、検出モデルの一般化が影響を受け、新しいシナリオに効果的に適応できなくなります。このような欠陥は、大規模なデータセットの収集や元のトレーニング データの再利用を妨げます。したがって、今後は、ドメインのバイアスを排除し、異なるデータ ソースを適応的に統合する方法を見つけることに重点を置くことができます。
- 解像度の競合: 通常、センサーが異なれば解像度も異なります。たとえば、LiDAR の空間密度は画像の空間密度よりも大幅に低くなります。どの投影法を使っても、対応関係が見つからないため情報の損失が発生します。これにより、特徴ベクトルの解像度が異なるため、または生の情報の不均衡が原因で、モデルが 1 つの特定のモダリティからのデータによって支配される可能性があります。したがって、将来の研究では、異なる空間解像度のセンサーと互換性のある新しいデータ表現システムを探索する可能性があります。
9参考
[1] https://zhuanlan.zhihu.com/p/470588787
[2] マルチモーダル センサー フュージョン自動運転の認識: 調査

元のリンク: https://mp.weixin.qq.com/s/usAQRL18vww9YwMXRvEwLw
以上が自動運転におけるマルチモーダル融合知覚アルゴリズムの応用に関する詳細な議論の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 AIのスキルギャップは、サプライチェーンのダウンを遅くしていますApr 26, 2025 am 11:13 AM
AIのスキルギャップは、サプライチェーンのダウンを遅くしていますApr 26, 2025 am 11:13 AM「AI-Ready労働力」という用語は頻繁に使用されますが、サプライチェーン業界ではどういう意味ですか? サプライチェーン管理協会(ASCM)のCEOであるAbe Eshkenaziによると、批評家ができる専門家を意味します
 1つの会社がAIを永遠に変えるために静かに取り組んでいる方法Apr 26, 2025 am 11:12 AM
1つの会社がAIを永遠に変えるために静かに取り組んでいる方法Apr 26, 2025 am 11:12 AM分散型AI革命は静かに勢いを増しています。 今週の金曜日、テキサス州オースティンでは、ビテンサーのエンドゲームサミットは極めて重要な瞬間を示し、理論から実用的な応用に分散したAI(DEAI)を移行します。 派手なコマーシャルとは異なり
 Nvidiaは、AIエージェント開発を合理化するためにNEMOマイクロサービスをリリースしますApr 26, 2025 am 11:11 AM
Nvidiaは、AIエージェント開発を合理化するためにNEMOマイクロサービスをリリースしますApr 26, 2025 am 11:11 AMエンタープライズAIはデータ統合の課題に直面しています エンタープライズAIの適用は、ビジネスデータを継続的に学習することで正確性と実用性を維持できるシステムを構築する大きな課題に直面しています。 NEMOマイクロサービスは、NVIDIAが「データフライホイール」と呼んでいるものを作成することにより、この問題を解決し、AIシステムがエンタープライズ情報とユーザーインタラクションへの継続的な露出を通じて関連性を維持できるようにします。 この新しく発売されたツールキットには、5つの重要なマイクロサービスが含まれています。 NEMOカスタマイザーは、より高いトレーニングスループットを備えた大規模な言語モデルの微調整を処理します。 NEMO評価者は、カスタムベンチマークのAIモデルの簡素化された評価を提供します。 Nemo Guardrailsは、コンプライアンスと適切性を維持するためにセキュリティ管理を実装しています
 aiは芸術とデザインの未来のために新しい絵を描きますApr 26, 2025 am 11:10 AM
aiは芸術とデザインの未来のために新しい絵を描きますApr 26, 2025 am 11:10 AMAI:芸術とデザインの未来 人工知能(AI)は、前例のない方法で芸術とデザインの分野を変えており、その影響はもはやアマチュアに限定されませんが、より深く影響を与えています。 AIによって生成されたアートワークとデザインスキームは、広告、ソーシャルメディアの画像生成、Webデザインなど、多くのトランザクションデザインアクティビティで従来の素材画像とデザイナーに迅速に置き換えられています。 ただし、プロのアーティストやデザイナーもAIの実用的な価値を見つけています。 AIを補助ツールとして使用して、新しい美的可能性を探求し、さまざまなスタイルをブレンドし、新しい視覚効果を作成します。 AIは、アーティストやデザイナーが繰り返しタスクを自動化し、さまざまなデザイン要素を提案し、創造的な入力を提供するのを支援します。 AIはスタイル転送をサポートします。これは、画像のスタイルを適用することです
 エージェントAIとのズームがどのように革命を起こしているか:会議からマイルストーンまでApr 26, 2025 am 11:09 AM
エージェントAIとのズームがどのように革命を起こしているか:会議からマイルストーンまでApr 26, 2025 am 11:09 AM最初はビデオ会議プラットフォームで知られていたZoomは、エージェントAIの革新的な使用で職場革命をリードしています。 ZoomのCTOであるXD Huangとの最近の会話は、同社の野心的なビジョンを明らかにしました。 エージェントAIの定義 huang d
 大学に対する実存的な脅威Apr 26, 2025 am 11:08 AM
大学に対する実存的な脅威Apr 26, 2025 am 11:08 AMAIは教育に革命をもたらしますか? この質問は、教育者と利害関係者の間で深刻な反省を促しています。 AIの教育への統合は、機会と課題の両方をもたらします。 Tech Edvocate NotesのMatthew Lynch、Universitとして
 プロトタイプ:アメリカの科学者は海外の仕事を探していますApr 26, 2025 am 11:07 AM
プロトタイプ:アメリカの科学者は海外の仕事を探していますApr 26, 2025 am 11:07 AM米国における科学的研究と技術の開発は、おそらく予算削減のために課題に直面する可能性があります。 Natureによると、海外の雇用を申請するアメリカの科学者の数は、2024年の同じ期間と比較して、2025年1月から3月まで32%増加しました。以前の世論調査では、調査した研究者の75%がヨーロッパとカナダでの仕事の検索を検討していることが示されました。 NIHとNSFの助成金は過去数か月で終了し、NIHの新しい助成金は今年約23億ドル減少し、3分の1近く減少しました。リークされた予算の提案は、トランプ政権が科学機関の予算を急激に削減していることを検討しており、最大50%の削減の可能性があることを示しています。 基礎研究の分野での混乱は、米国の主要な利点の1つである海外の才能を引き付けることにも影響を与えています。 35
 オープンAIの最新のGPT 4.1ファミリ - 分析VidhyaApr 26, 2025 am 10:19 AM
オープンAIの最新のGPT 4.1ファミリ - 分析VidhyaApr 26, 2025 am 10:19 AMOpenaiは、強力なGPT-4.1シリーズを発表しました。実際のアプリケーション向けに設計された3つの高度な言語モデルのファミリー。 この大幅な飛躍は、より速い応答時間、理解の強化、およびTと比較した大幅に削減されたコストを提供します


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

Dreamweaver Mac版
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

Safe Exam Browser
Safe Exam Browser は、オンライン試験を安全に受験するための安全なブラウザ環境です。このソフトウェアは、あらゆるコンピュータを安全なワークステーションに変えます。あらゆるユーティリティへのアクセスを制御し、学生が無許可のリソースを使用するのを防ぎます。

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

PhpStorm Mac バージョン
最新(2018.2.1)のプロフェッショナル向けPHP統合開発ツール
ホットトピック
 7728
7728 15164314139752129025123329
15164314139752129025123329