


13B パラメーターを持つモデルは、トップの GPT-4 に勝つことができますか?以下の図に示すように、結果の妥当性を確認するために、このテストでは OpenAI のデータノイズ除去手法にも従った結果、データ汚染の証拠は見つかりませんでした。
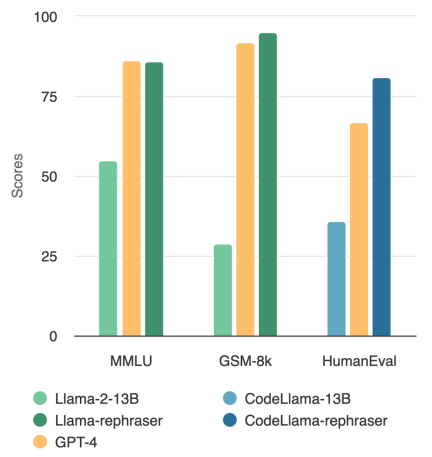
画像内のモデルを観察すると、「rephraser」という単語が含まれている限り、モデルのパフォーマンスが比較的高いことがわかります。
これの背後にあるトリックは何ですか?データが汚染されている、つまりトレーニング セット内でテスト セットの情報が漏洩していることが判明しましたが、この汚染を検出するのは簡単ではありません。この問題は非常に重要であるにもかかわらず、汚染を理解して検出することは依然として未解決で困難なパズルです。
現時点で、汚染除去に最も一般的に使用される方法は、N グラムのオーバーラップと埋め込み類似性検索です。N グラムのオーバーラップは、文字列のマッチングに依存して汚染を検出します。これは GPT-4 です。 , PaLM や Llama-2 などのモデルの一般的なアプローチ。埋め込み類似性検索では、BERT などの事前トレーニング済みモデルの埋め込みを使用して、類似した汚染された可能性のあるサンプルを見つけます。
しかし、カリフォルニア大学バークレー校と上海交通大学の研究によると、テストデータの単純な変更 (書き換え、翻訳など) によって、既存の検出方法が簡単に回避されてしまう可能性があります。彼らは、このようなテスト ケースのバリエーションを「言い換えサンプル」と呼んでいます。
MMLU ベンチマークテストで書き換えが必要な内容は、書き換えたサンプルのデモ結果です。結果は、トレーニング セットにそのようなサンプルが含まれている場合、13B モデルは非常に高いパフォーマンス (MMLU 85.9) を達成できることを示しています。残念ながら、N グラムのオーバーラップや埋め込み類似性などの既存の検出方法では、この汚染を検出できません。たとえば、類似性手法を埋め込むと、同じトピック内の他の質問と言い換えられた質問を区別するのが困難になります

HumanEval や GSM-8K など、広く使用されているコーディングおよび数学のベンチマークで一貫した結果が観察されています (記事の冒頭の図を参照)。したがって、書き換えが必要なコンテンツ、つまり書き換えられたサンプルを検出できることが重要になります。
 次に、研究がどのように実施されたかを見てみましょう。
次に、研究がどのように実施されたかを見てみましょう。
- #論文アドレス: https://arxiv.org/pdf/2311.04850 .pdf
- プロジェクトアドレス: https://github.com/lm-sys/llm-decontaminator#detect
#論文紹介
##大規模モデル (LLM) の急速な開発に伴い、人々は次の問題にますます注目するようになりました。テストセットの汚染が多い。多くの人が公開ベンチマークの信頼性について懸念を表明しています。
#この問題を解決するために、文字列マッチング (N グラム オーバーラップなど) などの従来の除染方法を使用して、データを削除する人もいます。ベースラインデータ。ただし、これらのサニタイズ措置は、テスト データに単純な変更 (書き換え、翻訳など) を加えるだけで簡単に回避できるため、これらの操作は十分とは言えません。このテスト データの変更により、13B モデルはテスト ベンチマークを容易にオーバーフィットし、より重要な GPT-4 と同等のパフォーマンスを達成します。研究者らは、MMLU、GSK8k、HumanEval などのベンチマークでこれらの観察結果を検証しました。
同時に、これらの増大するリスクに対処するために、この論文では、より強力な LLM ベースの除染法 LLM 除染器は、一般的な事前トレーニングおよび微調整データセットに適用されており、その結果、この記事で提案されている LLM 法は、書き換えられたサンプルの除去において既存の方法よりも大幅に優れていることが示されています。
このアプローチでは、これまで知られていなかったテストの重複も明らかになりました。たとえば、RedPajamaData-1T や StarCoder-Data などの事前トレーニング セットでは、HumanEval ベンチマークと 8 ~ 18% 重複していることがわかります。さらに、この論文では GPT-3.5/4 によって生成された合成データセットにもこの汚染が見つかっており、これも AI 分野における偶発的な汚染の潜在的なリスクを示しています。
この記事を通じて、公開ベンチマークを使用する際により堅牢なサニタイズ方法を採用し、モデルを正確に評価するための新しいワンタイム テスト ケースを積極的に開発するようコミュニティに呼びかけることを願っています
書き直す必要がある内容は次のとおりです: 書き直されたサンプル
この記事の目的は、トレーニング セットの単純な変更に次のような変更が含まれるかどうかを調査することです。テスト セットは最終的なベンチマークのパフォーマンスに影響を与え、テスト ケースのこの変更は「書き直す必要があるのは、サンプルを書き直す」と呼ばれます。実験では、数学、知識、コーディングなど、ベンチマークのさまざまな領域が考慮されました。例 1 は、書き換えが必要な GSM-8k のコンテンツです。書き換えられたサンプルでは 10 グラムの重複が検出できず、変更されたテキストは元のテキストと同じセマンティクスを維持します。

#ベースライン汚染のさまざまな形式に対する上書き手法には若干の違いがあります。テキストベースのベンチマーク テストでは、セマンティクスを変更しないという目的を達成するために、語順を並べ替えたり、同義語の置換を使用したりしてテスト ケースを書き直します。コードベースのベンチマーク テストでは、コーディング スタイル、命名方法などを変更してこの記事を書き直します。
以下に示すように、アルゴリズム 1 は、指定されたテスト セット A に対する手法を提案します。シンプルなアルゴリズム。この方法は、テストサンプルの検出を回避するのに役立ちます。

# 次に、この論文では、書き換えが必要なコンテンツの削除を正確に検出できる新しい汚染検出方法を提案します。サンプルを書き直します。
特に、この記事では LLM 除染装置について紹介します。まず、各テスト ケースについて、埋め込み類似性検索を使用して、類似性が最も高い上位 k 個のトレーニング項目を特定します。その後、各ペアが LLM (GPT-4 など) によって同一かどうか評価されます。このアプローチは、どの程度のデータ セットを書き換える必要があるかを判断するのに役立ちます (書き換えサンプル)。
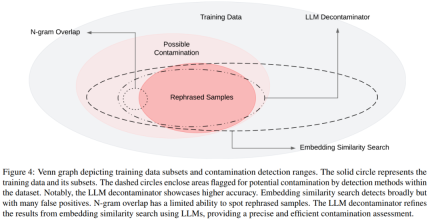
さまざまな汚染およびさまざまな検出方法のベン図を図 4 に示します。
実験
セクション 5.1 では、書き換えられたサンプルでトレーニングされたモデルが 3 つの項目で大幅に高いスコアを達成できることを実験で証明しました。広く使用されている 2 つの項目で GPT-4 と同等のパフォーマンスを達成しました。ベンチマーク (MMLU、HumanEval、GSM-8k) は、書き換える必要があるのは、書き換えられたサンプルを汚染とみなし、トレーニング データから削除する必要があることを示唆しています。セクション 5.2 では、MMLU/HumanEval に従ってこの記事で書き直す必要があるのは、さまざまな汚染検出方法を評価するためにサンプルを書き直すことです。セクション 5.3 では、広く使用されているトレーニング セットに LLM 除染器を適用し、これまで知られていなかった汚染を発見します。
主な結果を見てみましょう
書き直す必要がある内容は次のとおりです: 汚染基準サンプルの書き換え
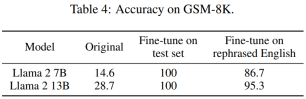
表 2 に示すように、書き換える必要がある内容は次のとおりです。書き換えられたサンプルでトレーニングされた Llama-2 7B および 13B は、大幅に高いパフォーマンスを達成しました。 MMLU ポイントは 45.3 から 88.5 になります。これは、書き換えられたサンプルがベースライン データを大幅に歪める可能性があり、汚染を考慮する必要があることを示唆しています。

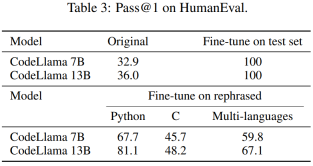
この記事では、HumanEval テスト セットも書き直し、それを 5 つのプログラミング言語 (C、JavaScript、Rust、Go) に翻訳します。そしてジャワ。結果は、書き換えられたサンプルでトレーニングされた CodeLlama 7B および 13B が、HumanEval でそれぞれ 32.9 ~ 67.7 および 36.0 ~ 81.1 の範囲の非常に高いスコアを達成できることを示しています。比較すると、GPT-4 は HumanEval で 67.0 しか達成できません。
以下の表 4 も同じ効果を実現します。
#汚染を検出する方法の評価
表 5 に示すとおりLLM 除染装置を除き、他のすべての検出方法では、いくつかの誤検知が発生します。書き換えられたサンプルも翻訳されたサンプルも、N グラムのオーバーラップによって検出されません。 multi-qa BERT を使用した埋め込み類似性検索は、翻訳されたサンプルではまったく効果がないことが判明しました。

#データセットの汚染状況
表 7 に、各トレーニング データセットのさまざまなベンチマークのデータ汚染の割合を示します。


以上がGPT-4との全面対決では13Bモデルが有利か?その裏には何か異常な事情があるのでしょうか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 Gemma Scope:AI'の思考プロセスを覗くためのGoogle'の顕微鏡Apr 17, 2025 am 11:55 AM
Gemma Scope:AI'の思考プロセスを覗くためのGoogle'の顕微鏡Apr 17, 2025 am 11:55 AMジェマの範囲で言語モデルの内部の仕組みを探る AI言語モデルの複雑さを理解することは、重要な課題です。 包括的なツールキットであるGemma ScopeのGoogleのリリースは、研究者に掘り下げる強力な方法を提供します
 ビジネスインテリジェンスアナリストは誰で、どのようになるか?Apr 17, 2025 am 11:44 AM
ビジネスインテリジェンスアナリストは誰で、どのようになるか?Apr 17, 2025 am 11:44 AMビジネスの成功のロック解除:ビジネスインテリジェンスアナリストになるためのガイド 生データを組織の成長を促進する実用的な洞察に変換することを想像してください。 これはビジネスインテリジェンス(BI)アナリストの力です - GUにおける重要な役割
 SQLに列を追加する方法は? - 分析VidhyaApr 17, 2025 am 11:43 AM
SQLに列を追加する方法は? - 分析VidhyaApr 17, 2025 am 11:43 AMSQLの変更テーブルステートメント:データベースに列を動的に追加する データ管理では、SQLの適応性が重要です。 その場でデータベース構造を調整する必要がありますか? Alter Tableステートメントはあなたの解決策です。このガイドの詳細は、コルを追加します
 ビジネスアナリストとデータアナリストApr 17, 2025 am 11:38 AM
ビジネスアナリストとデータアナリストApr 17, 2025 am 11:38 AM導入 2人の専門家が重要なプロジェクトで協力している賑やかなオフィスを想像してください。 ビジネスアナリストは、会社の目標に焦点を当て、改善の分野を特定し、市場動向との戦略的整合を確保しています。 シム
 ExcelのCountとCountaとは何ですか? - 分析VidhyaApr 17, 2025 am 11:34 AM
ExcelのCountとCountaとは何ですか? - 分析VidhyaApr 17, 2025 am 11:34 AMExcelデータカウントと分析:カウントとカウントの機能の詳細な説明 特に大規模なデータセットを使用する場合、Excelでは、正確なデータカウントと分析が重要です。 Excelは、これを達成するためにさまざまな機能を提供し、CountおよびCounta関数は、さまざまな条件下でセルの数をカウントするための重要なツールです。両方の機能はセルをカウントするために使用されますが、設計ターゲットは異なるデータ型をターゲットにしています。 CountおよびCounta機能の特定の詳細を掘り下げ、独自の機能と違いを強調し、データ分析に適用する方法を学びましょう。 キーポイントの概要 カウントとcouを理解します
 ChromeはAIと一緒にここにいます:毎日何か新しいことを体験してください!!Apr 17, 2025 am 11:29 AM
ChromeはAIと一緒にここにいます:毎日何か新しいことを体験してください!!Apr 17, 2025 am 11:29 AMGoogle Chrome'sAI Revolution:パーソナライズされた効率的なブラウジングエクスペリエンス 人工知能(AI)は私たちの日常生活を急速に変換しており、Google ChromeはWebブラウジングアリーナで料金をリードしています。 この記事では、興奮を探ります
 ai' s Human Side:Wellbeing and the Quadruple bottuntApr 17, 2025 am 11:28 AM
ai' s Human Side:Wellbeing and the Quadruple bottuntApr 17, 2025 am 11:28 AMインパクトの再考:四重材のボトムライン 長い間、会話はAIの影響の狭い見方に支配されており、主に利益の最終ラインに焦点を当てています。ただし、より全体的なアプローチは、BUの相互接続性を認識しています
 5ゲームを変える量子コンピューティングの使用ケースあなたが知っておくべきであるApr 17, 2025 am 11:24 AM
5ゲームを変える量子コンピューティングの使用ケースあなたが知っておくべきであるApr 17, 2025 am 11:24 AM物事はその点に向かって着実に動いています。量子サービスプロバイダーとスタートアップに投資する投資は、業界がその重要性を理解していることを示しています。そして、その価値を示すために、現実世界のユースケースの数が増えています


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

ドリームウィーバー CS6
ビジュアル Web 開発ツール

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

