
 テクノロジー周辺機器AI中国科学院の研究チームは2つの重要な論文を発表した。1つは種を超えた生命の基盤に関する初の大規模モデルの発表、もう1つは細胞運命予測のための新しいAIモデルの発表だ。
テクノロジー周辺機器AI中国科学院の研究チームは2つの重要な論文を発表した。1つは種を超えた生命の基盤に関する初の大規模モデルの発表、もう1つは細胞運命予測のための新しいAIモデルの発表だ。中国科学院の研究チームは2つの重要な論文を発表した。1つは種を超えた生命の基盤に関する初の大規模モデルの発表、もう1つは細胞運命予測のための新しいAIモデルの発表だ。

著者 | 中国科学院多分野研究チーム
編集者 | ScienceAI
20 世紀の人類の 3 つの主要な科学プロジェクトの 1 つとして知られています。世紀 ゲノムプロジェクトは、生命の謎の詳細な分析を開始しました。生命プロセスは多次元で非常に動的な性質を持っているため、従来の実験研究手法では遺伝コードの根底にある共通法則を体系的かつ正確に解読することが困難であり、表現モデリングと知識を達成するには強力なコンピューティング技術を使用することが急務となっています。遺伝子データの発見。
現在、大規模モデルを核とした人工知能技術は、コンピュータビジョンや自然言語理解などの分野で革命を引き起こし、データや知識の深い理解を実証し、応用が期待されています。生命科学研究、システムの基礎となる遺伝暗号の共通法則を正確に解読するために
最近、中国科学院の多分野の学際的研究チームで構成される「Xcompass Consortium」(Xcompassコンソーシアム)は、生命科学研究に力を与える人工知能における重要なブレークスルー 異種生命の基礎を示す世界初の大規模モデル、ジーンコンパスの構築に成功。このモデルは、ヒトやマウスの1億2,600万個以上の単細胞のトランスクリプトームデータを統合し、プロモーター配列や遺伝子の共発現関係など4種類の事前知識を統合し、基本モデルパラメーター数は1億3,000万個に達し、遺伝子制御を実現します。規制法のパノラマ学習と理解は、細胞の状態変化の予測とさまざまな生命プロセスの正確な分析を同時にサポートし、生命科学研究を強化する人工知能の大きな可能性を実証します。
この研究のタイトルは「GeneCompass:知識に基づいた異種基礎モデルによる普遍的な遺伝子制御機構の解読」で、bioRxivに掲載されました。

紙のリンク: https://www.biorxiv.org/content/10.1101/2023.09.26.559542v1
さらに, 同チームは、細胞運命変換の中核因子を正確に特定でき、転写因子の摂動をシミュレートする機能を備えた転移学習に基づく遺伝子制御ネットワーク生成モデル「CellPolaris」も同時にリリースした。
研究のタイトルは「CellPolaris:遺伝子制御ネットワークの一般化転移学習による細胞運命の解読」で、bioRxivに掲載されました。

#GeneCompass: 種を超えた生命の基盤に関する初の大規模モデル
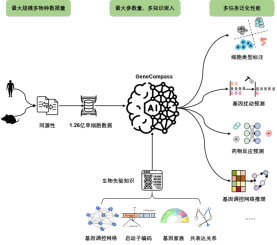
1 億 2,000 万の細胞と 1 億 3,000 万のパラメーターを含む、種を超えた生命の基本の大規模モデル
現在、単一の種が世界中で取得されています。 -細胞トランスクリプトームデータは数千万にすぎず、複雑な生命プロセスの分析に使用される基本的な生命モデルの大規模モデルのトレーニングを完全にサポートすることは困難です。
チームは、さまざまな種からオープンソースの単一細胞トランスクリプトーム データを収集し、スクリーニング、クリーニング、正規化などの前処理プロセスを通じて、マウスの 1 億 2,600 万個以上の細胞を含む既知最大の高品質データベースを確立しました。トレーニング データ セット scCompass-126M は、Transformer 自己注意メカニズムに基づく深層学習アーキテクチャを採用しており、異なる細胞背景の異なる遺伝子間の長期的な動的相関を捉えることができ、モデル パラメーターのサイズは 1 億 3,000 万に達します。生命プロセスの高解像度特性評価を達成するために、GeneCompass は初めて遺伝子数と発現レベルを二重エンコードし、遺伝子間の相関関係を効果的かつ高感度に抽出できるようにしました。これにより、GeneCompass は、細胞の種類や摂動状態など、さまざまな特定の条件下での遺伝子間の相互作用をより正確に分析できるようになります。
事前トレーニング中に事前知識を埋め込むと、モデルのパフォーマンスを効果的に向上させることができます。
モデルは、プロモーター配列、既知の遺伝子制御ネットワーク、遺伝子ファミリー情報、および遺伝子の共発現を効果的に統合します。 4 種類の生物学的事前知識間の関係に人間による注釈情報のエンコーディングを追加することで、生物学的データ間の複雑な特徴相関関係の理解を向上させます。データ情報とさまざまな種の事前知識をトレーニングおよび統合することにより、GeneCompass は従来の生物学研究の効率と精度を向上させ、まだ突破できない複雑な生命科学の問題に新たな入り口をもたらすことが期待されています。
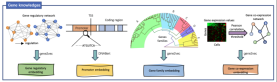
スケール効果により、生物学的進化の保守的な法則を捉えるためのモデル トレーニングが促進されます
チームは、大規模な異種データで事前トレーニングされたモデルのパフォーマンスが向上することを発見しました。これはスケーリングの法則と一致しています。大規模な複数種の事前トレーニング データにより、より優れた事前トレーニング表現が生成され、下流タスクのパフォーマンスがさらに向上します。この発見は、種間で保存された遺伝子制御パターンが存在し、これらのパターンは事前訓練されたモデルによって学習および理解できることを示しています。同時に、これは、種とデータの拡大に伴い、モデルのパフォーマンスが引き続き向上すると予想されることも意味します。
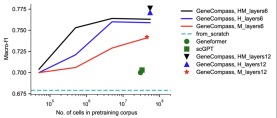
マルチタスクのパフォーマンスの利点は、基本的な大規模モデルの強力な一般化能力を示しています
知識が埋め込まれた最大の事前トレーニング済みの異種基本生活モデルとして現在までのところ、GeneCompass は下流タスクのための複数の異種間転移学習を実現し、細胞型アノテーション、定量的遺伝子摂動予測、薬剤感受性分析などにおいて既存の方法よりも優れたパフォーマンスを達成できます。これは、ラベルのない複数種のビッグデータに基づいた事前トレーニングと、モデルの微調整に異なるサブタスクデータを使用することの戦略的利点を十分に実証しており、遺伝子に関連するさまざまな生物学的問題を分析および予測するための普遍的なソリューションとなることが期待されています-細胞の特性。
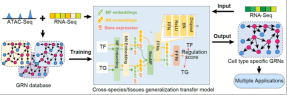
細胞分極: 転移学習により遺伝子制御ネットワークを解読し、細胞運命の変化を予測
転移学習を使用して細胞を生成する特定の遺伝子制御ネットワーク
チームはまた、CellPolaris と呼ばれる、一般化転移学習に基づいた遺伝子制御ネットワーク構築 AI モデルのセットも開発しました。このモデルはまず、一致する細胞シナリオで数百セットのトランスクリプトームとクロマチンのアクセシビリティ データを分類して高品質の遺伝子制御ネットワークを構築し、次に一般化転移学習モデルを使用して、トランスクリプトーム データのみを使用して細胞シナリオでより多くの遺伝子を生成します。 。次に、生成された信頼性の高い遺伝子制御ネットワークを使用して、細胞運命遷移におけるコア転写因子を同定するツールと、確率的グラフィカルモデルに基づく転写因子摂動シミュレーションツールを開発しました。このモデルは、細胞運命変換の中核因子を効果的に同定し、転写因子摂動のシミュレーションを実現することができ、遺伝子制御機構の解析や疾患原因遺伝子の発見において重要な応用価値を持っています。
上記の 2 つの研究は、「コンパス アライアンス」チームによって完了しました。「コンパス アライアンス」チームは現在、主に中国科学院動物研究所、共同コンピュータ ネットワーク情報センター、オートメーション研究所、コンピューティング技術研究所、数理・システム科学研究所の研究機関およびその他の研究機関で構成され、この提携の目標は、デジタルインテリジェンスを推進するライフサイエンス研究の新たなパラダイムを確立し、人生の本質的な法則。 ################################################ #人工的な知能
以上が中国科学院の研究チームは2つの重要な論文を発表した。1つは種を超えた生命の基盤に関する初の大規模モデルの発表、もう1つは細胞運命予測のための新しいAIモデルの発表だ。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 踊りましょう:私たちの人間のニューラルネットを微調整するための構造化された動きApr 27, 2025 am 11:09 AM
踊りましょう:私たちの人間のニューラルネットを微調整するための構造化された動きApr 27, 2025 am 11:09 AM科学者は、彼らの機能を理解するために、人間とより単純なニューラルネットワーク(C. elegansのものと同様)を広く研究してきました。 ただし、重要な疑問が生じます。新しいAIと一緒に効果的に作業するために独自のニューラルネットワークをどのように適応させるのか
 新しいGoogleリークは、Gemini AIのサブスクリプションの変更を明らかにしますApr 27, 2025 am 11:08 AM
新しいGoogleリークは、Gemini AIのサブスクリプションの変更を明らかにしますApr 27, 2025 am 11:08 AMGoogleのGemini Advanced:Horizonの新しいサブスクリプションティア 現在、Gemini Advancedにアクセスするには、1か月あたり19.99ドルのGoogle One AIプレミアムプランが必要です。 ただし、Android Authorityのレポートは、今後の変更を示唆しています。 最新のGoogle p
 データ分析の加速がAIの隠されたボトルネックをどのように解決しているかApr 27, 2025 am 11:07 AM
データ分析の加速がAIの隠されたボトルネックをどのように解決しているかApr 27, 2025 am 11:07 AM高度なAI機能を取り巻く誇大宣伝にもかかわらず、エンタープライズAIの展開内に大きな課題が潜んでいます:データ処理ボトルネック。 CEOがAIの進歩を祝う間、エンジニアはクエリの遅い時間、過負荷のパイプライン、
 MarkitDown MCPは、任意のドキュメントをマークダウンに変換できます!Apr 27, 2025 am 09:47 AM
MarkitDown MCPは、任意のドキュメントをマークダウンに変換できます!Apr 27, 2025 am 09:47 AMドキュメントの取り扱いは、AIプロジェクトでファイルを開くだけでなく、カオスを明確に変えることです。 PDF、PowerPoint、Wordなどのドキュメントは、あらゆる形状とサイズでワークフローをフラッシュします。構造化された取得
 建物のエージェントにGoogle ADKを使用する方法は? - 分析VidhyaApr 27, 2025 am 09:42 AM
建物のエージェントにGoogle ADKを使用する方法は? - 分析VidhyaApr 27, 2025 am 09:42 AMGoogleのエージェント開発キット(ADK)のパワーを活用して、実際の機能を備えたインテリジェントエージェントを作成します。このチュートリアルは、ADKを使用して会話エージェントを構築し、GeminiやGPTなどのさまざまな言語モデルをサポートすることをガイドします。 w
 効果的な問題解決のためにLLMを介したSLMの使用 - 分析VidhyaApr 27, 2025 am 09:27 AM
効果的な問題解決のためにLLMを介したSLMの使用 - 分析VidhyaApr 27, 2025 am 09:27 AMまとめ: Small Language Model(SLM)は、効率のために設計されています。それらは、リソース不足、リアルタイム、プライバシーに敏感な環境の大手言語モデル(LLM)よりも優れています。 特にドメインの特異性、制御可能性、解釈可能性が一般的な知識や創造性よりも重要である場合、フォーカスベースのタスクに最適です。 SLMはLLMSの代替品ではありませんが、精度、速度、費用対効果が重要な場合に理想的です。 テクノロジーは、より少ないリソースでより多くを達成するのに役立ちます。それは常にドライバーではなく、プロモーターでした。蒸気エンジンの時代からインターネットバブル時代まで、テクノロジーの力は、問題の解決に役立つ範囲にあります。人工知能(AI)および最近では生成AIも例外ではありません
 コンピュータービジョンタスクにGoogle Geminiモデルを使用する方法は? - 分析VidhyaApr 27, 2025 am 09:26 AM
コンピュータービジョンタスクにGoogle Geminiモデルを使用する方法は? - 分析VidhyaApr 27, 2025 am 09:26 AMコンピュータービジョンのためのGoogleGeminiの力を活用:包括的なガイド 大手AIチャットボットであるGoogle Geminiは、その機能を会話を超えて拡張して、強力なコンピュータービジョン機能を網羅しています。 このガイドの利用方法については、
 Gemini 2.0 Flash vs O4-Mini:GoogleはOpenaiよりもうまくやることができますか?Apr 27, 2025 am 09:20 AM
Gemini 2.0 Flash vs O4-Mini:GoogleはOpenaiよりもうまくやることができますか?Apr 27, 2025 am 09:20 AM2025年のAIランドスケープは、GoogleのGemini 2.0 FlashとOpenaiのO4-Miniの到着とともに感動的です。 数週間離れたこれらの最先端のモデルは、同等の高度な機能と印象的なベンチマークスコアを誇っています。この詳細な比較


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

SublimeText3 英語版
推奨: Win バージョン、コードプロンプトをサポート!

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

Dreamweaver Mac版
ビジュアル Web 開発ツール

メモ帳++7.3.1
使いやすく無料のコードエディター

PhpStorm Mac バージョン
最新(2018.2.1)のプロフェッショナル向けPHP統合開発ツール
ホットトピック
 7754
7754 15164314139952129325123429
15164314139952129325123429