


人工知能の開発は急速に進歩していますが、問題も頻繁に発生します。 OpenAI の新しい GPT ビジョン API はフロントエンドとしては素晴らしいですが、幻覚の問題があるためバックエンドについても文句の付けようがありません。
錯覚は常に大規模モデルの致命的な欠陥です。データセットが複雑なため、古くなった情報や誤った情報が含まれることは避けられず、出力品質が厳しい課題に直面することになります。繰り返される情報が多すぎると、大規模なモデルにバイアスがかかる可能性もありますが、これも一種の錯覚です。しかし、幻覚は答えのない命題ではありません。開発プロセスでは、データセットの慎重な使用、厳格なフィルタリング、高品質のデータセットの構築、モデル構造とトレーニング方法の最適化により、幻覚の問題をある程度軽減できます。
人気の大型モデルはたくさんありますが、どれくらい幻覚緩和に効果があるのでしょうか?違いを明確に比較したランキングは次のとおりです

##Vectara プラットフォームは、人工知能インテリジェントに焦点を当てたこのランキングを発表しました。ランキングの更新日は 2023 年 11 月 1 日です。Vectara は、モデルの更新に応じてランキングを更新するために幻覚評価の追跡調査を継続すると述べました。
プロジェクト アドレス: https://github.com/vectara/hallucination-leaderboard
このリーダーボードを決定するために、Vectara は事実の一貫性調査を実施し、LLM 出力で幻覚を検出するようにモデルをトレーニングしました。彼らは、同等の SOTA モデルを使用し、パブリック API 経由で各 LLM に 1,000 の短いドキュメントを提供し、ドキュメントに示されている事実のみを使用して各ドキュメントを要約するように依頼しました。これら 1,000 件の文書のうち、各モデルによって要約されたのは 831 件の文書のみで、残りの文書は内容制限により少なくとも 1 つのモデルによって拒否されました。これら 831 件の文書を使用して、Vectara は各モデルの全体的な精度と錯覚率を計算しました。各モデルがプロンプトへの応答を拒否する割合は、「応答率」列に詳しく記載されています。モデルに送信されるコンテンツには違法または安全でないコンテンツは含まれていませんが、特定のコンテンツ フィルターをトリガーするのに十分なトリガー ワードが含まれています。これらの文書は主に CNN/Daily Mail コーパスからのものです

幻覚モデルの検出アドレスは: https://huggingface.co/vectara/hallucination_evaluation_model
さらに、さらに多くのLLM Bing Chat や Google Chat の統合など、ユーザーのクエリに答えるために RAG (Retrieval Augmented Generation) パイプラインで使用されます。 RAG システムでは、モデルは検索結果の集約としてデプロイされるため、このランキングは、RAG システムで使用される場合のモデルの精度を示す良い指標でもあります。 GPT-4 は、その優れた性能を考慮すると、幻覚の発生率が最も低いことは驚くことではありません。しかし、一部のネチズンは、GPT-3.5とGPT-4の間に大きな差がないことに驚いたと表明しました
#がGPTに追いついています- 4 および GPT-3.5、LLaMA 2 は良好なパフォーマンスを発揮します。しかし、Googleの大規模モデルのパフォーマンスは満足のいくものではありませんでした。一部のネチズンは、Google の BARD は誤った答えを避けるために「私はまだトレーニング中です」をよく使うと述べています。

このようなランキング リストを使用すると、次のようなことができます。さまざまなモデルの長所と短所をより直感的に判断できるようになりました。数日前、
 OpenAI は GPT-4 Turbo
OpenAI は GPT-4 Turbo
をリリースしましたが、一部のネチズンはすぐにランキングで更新することを提案しました。 #次のランキングがどうなるか、大きな変化があるかどうかを見ていきたいと思います。 
以上が大型モデルの幻覚率ランキング:GPT-4が3%で最も低く、Google Palmは27.2%と高いの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 オープンAIの最新のGPT 4.1ファミリ - 分析VidhyaApr 26, 2025 am 10:19 AM
オープンAIの最新のGPT 4.1ファミリ - 分析VidhyaApr 26, 2025 am 10:19 AMOpenaiは、強力なGPT-4.1シリーズを発表しました。実際のアプリケーション向けに設計された3つの高度な言語モデルのファミリー。 この大幅な飛躍は、より速い応答時間、理解の強化、およびTと比較した大幅に削減されたコストを提供します
 LLMベンチマークとは何ですか?Apr 26, 2025 am 10:13 AM
LLMベンチマークとは何ですか?Apr 26, 2025 am 10:13 AM大規模な言語モデル(LLM)は最新のAIアプリケーションに不可欠になっていますが、その機能を評価することは依然として課題です。従来のベンチマークは長い間LLMパフォーマンスを測定するための標準でしたが、RAでは
 7タスクGemini 2.5 Proは他のどのチャットボットよりも優れています!Apr 26, 2025 am 10:00 AM
7タスクGemini 2.5 Proは他のどのチャットボットよりも優れています!Apr 26, 2025 am 10:00 AMAIチャットボットはより賢くなり、その日までにますます洗練されています。 Google Deepmindの最新の実験モデルであるGemini 2.5 Proは、AIチャットボット機能における大きな前進を表しています。 Contexが改善されています
 6 O3プロンプト今日試してみる必要があります-AnalyticsVidhyaApr 26, 2025 am 09:56 AM
6 O3プロンプト今日試してみる必要があります-AnalyticsVidhyaApr 26, 2025 am 09:56 AMOpenaiのO3:推論とマルチモーダル機能における前進 OpenaiのO3モデルは、AI推論能力の大きな進歩を表しています。複雑な問題解決、分析タスク、および自律的なツールの使用のために設計されたO3
 Canva Codeを試しましたが、ここでそれがどのように進んだかを試しました。Apr 26, 2025 am 09:53 AM
Canva Codeを試しましたが、ここでそれがどのように進んだかを試しました。Apr 26, 2025 am 09:53 AMCanva Create2025:Canva CodeとAIを使用してデザインを革新する CanvaのCreate 2025イベントは、AIを搭載したツール、エンタープライズソリューション、特に開発者ツールにプラットフォームを拡大し、重要な進歩を発表しました。 キーアップデートにはentが含まれています
 タスク用のAIチャットボット:AIエージェントがどのように静かにアプリを交換しているかApr 26, 2025 am 09:50 AM
タスク用のAIチャットボット:AIエージェントがどのように静かにアプリを交換しているかApr 26, 2025 am 09:50 AM簡単なタスクのためのApp-Hoppingの時代は終わりです。 1回の会話で休暇を予約したり、請求書を自動的に交渉したりすることを想像してください。 これはAIエージェントの力です - あなたのニーズを予測する新しいデジタルアシスタント、JUSではなく
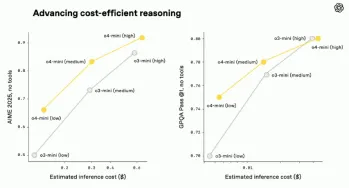 O3およびO4-MINI:Openaiの最も高度な推論モデルApr 26, 2025 am 09:46 AM
O3およびO4-MINI:Openaiの最も高度な推論モデルApr 26, 2025 am 09:46 AMOpenaiの画期的なO3およびO4-MINI推論モデル:AGIへの巨大な飛躍 GPT 4.1ファミリーの打ち上げのかかとで、Openaiは、AIであるO3およびO4-MINI推論モデルでの最新の進歩を発表しました。 これらは単なるAIモデルではありません。
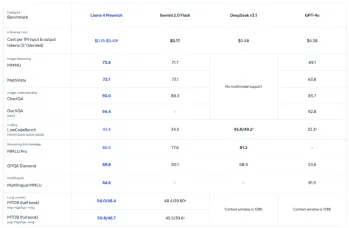 Llama 4とAutogenでAIエージェントを構築しますApr 26, 2025 am 09:44 AM
Llama 4とAutogenでAIエージェントを構築しますApr 26, 2025 am 09:44 AMインテリジェントAIエージェントを構築するためにLlama 4とオートゲンの力を活用する MetaのLlama 4ファミリのモデルはAIの景観を変換しており、インテリジェントなシステム開発に革命をもたらすためにネイティブのマルチモーダル機能を提供しています。 この記事の探検


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

VSCode Windows 64 ビットのダウンロード
Microsoft によって発売された無料で強力な IDE エディター

MantisBT
Mantis は、製品の欠陥追跡を支援するために設計された、導入が簡単な Web ベースの欠陥追跡ツールです。 PHP、MySQL、Web サーバーが必要です。デモおよびホスティング サービスをチェックしてください。

メモ帳++7.3.1
使いやすく無料のコードエディター
ホットトピック
 7723
7723 15164314139652129025123329
15164314139652129025123329