
ホームページ >テクノロジー周辺機器 >AI >利益予測はもう難しくありません。scikit-learn 線形回帰手法を使用すると、半分の労力で 2 倍の結果を得ることができます
利益予測はもう難しくありません。scikit-learn 線形回帰手法を使用すると、半分の労力で 2 倍の結果を得ることができます

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-11-13 20:25:291093ブラウズ
1. はじめに
生成人工知能は間違いなく革新的なテクノロジーですが、ほとんどのビジネス上の問題に対しては、回帰や分類などの従来の機械学習モデルが依然として第一の選択肢です。
書き直された内容: プライベート エクイティやベンチャー キャピタルなどの投資家が機械学習をどのように活用できるかを想像してみてください。この質問に答えるには、まず、データ投資家が何に関心を持っているか、そしてそれがどのように使用されているかを理解する必要があります。企業への投資に関する意思決定は、経費、成長、バーンレートなどの定量化可能なデータだけでなく、創業者の記録、顧客からのフィードバック、製品体験などの定性的なデータにも基づいています
この記事では基本事項を紹介します。線形回帰に関する知識があれば、完全なコードはここにあります。
書き直す必要がある内容は次のとおりです: [コード]: https://github.com/RoyiHD/linear-regression
2. プロジェクト設定
この記事このプロジェクトには Jupyter Notebook を使用します。まずいくつかのライブラリをインポートします。
インポート ライブラリ
# 绘制图表import matplotlib.pyplot as plt# 数据管理和处理from pandas import DataFrame# 绘制热力图import seaborn as sns# 分析from sklearn.metrics import r2_score# 用于训练和测试的数据管理from sklearn.model_selection import train_test_split# 导入线性模型from sklearn.linear_model import LinearRegression# 代码注释from typing import List
3. データ
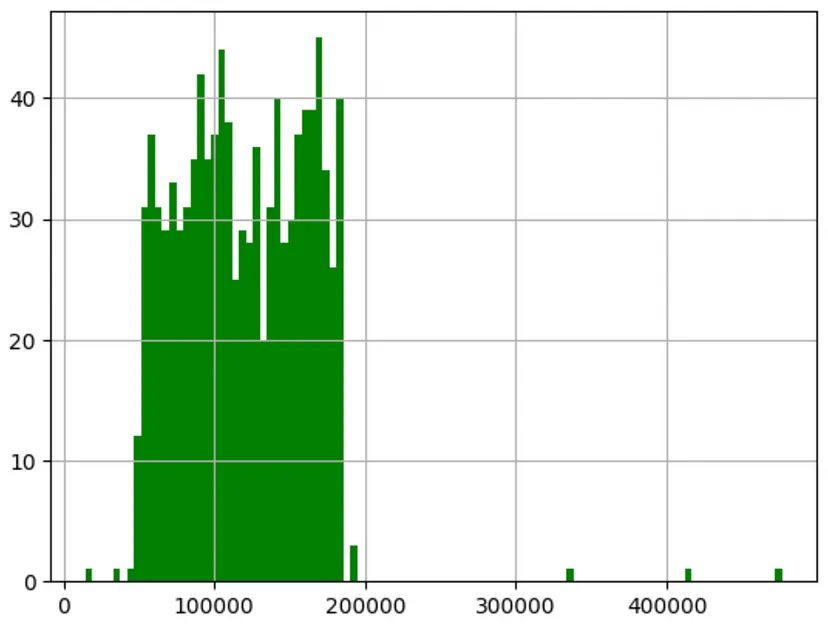
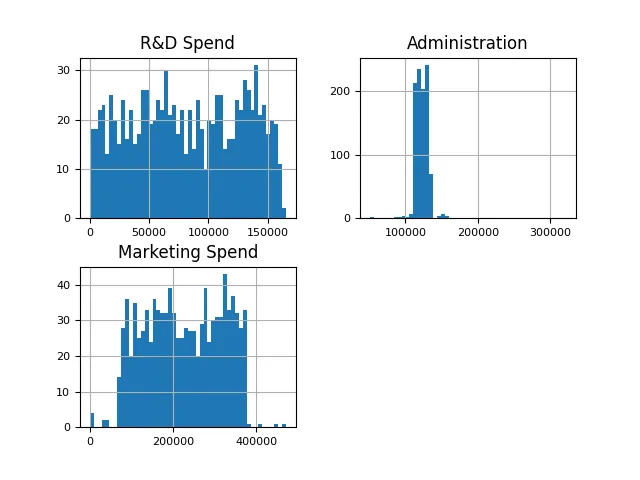
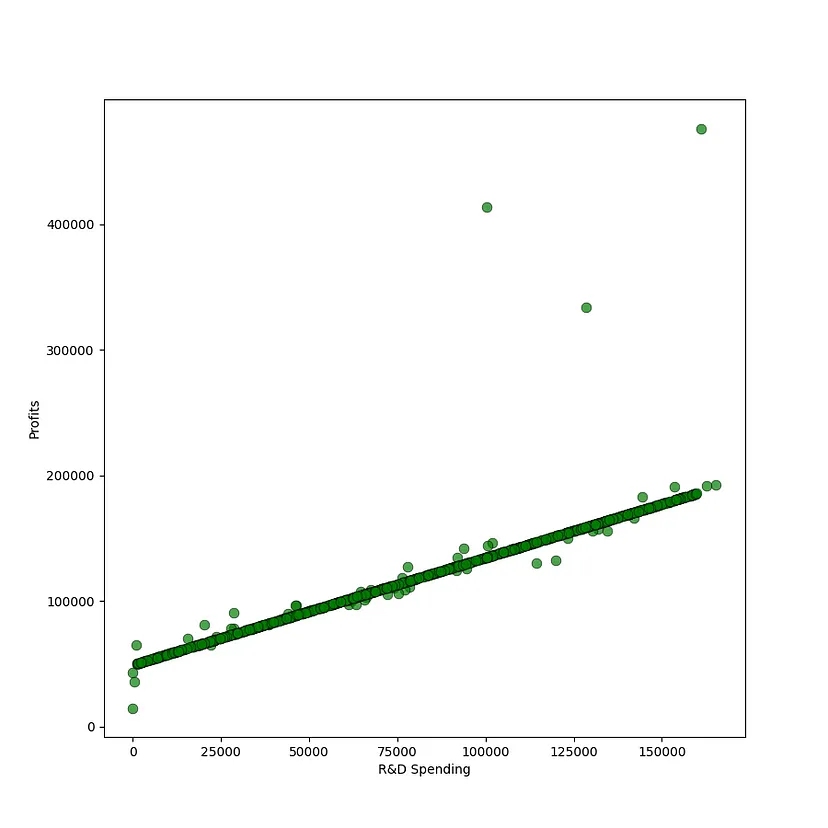
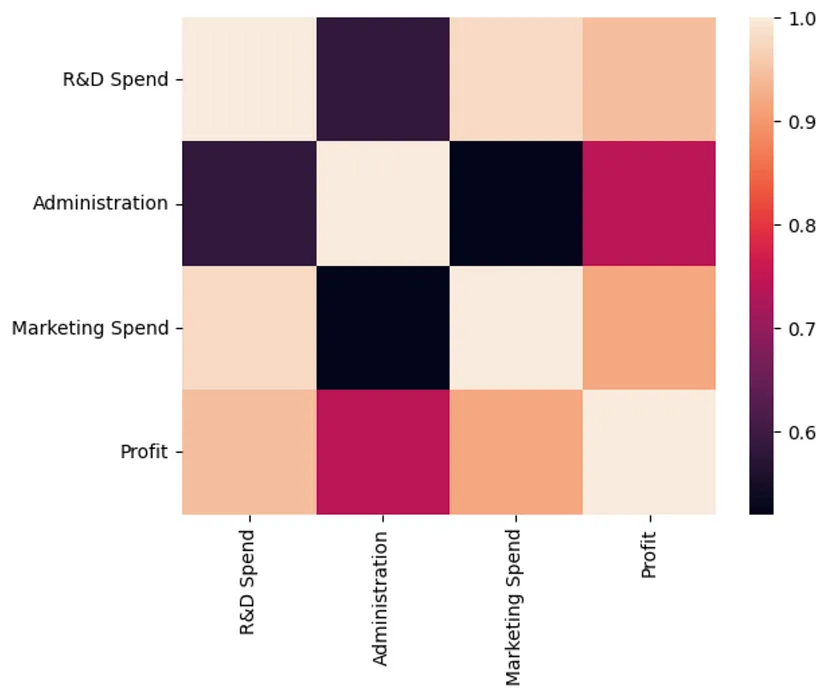
問題を単純化するために、この記事では地域データを使用します。データは会社の経費カテゴリと利益を表します。さまざまなデータポイントの例をいくつか見ることができます。この記事では、支出データを使用して線形回帰モデルをトレーニングし、利益を予測したいと考えています。
この記事で説明されているデータは企業の支出に関するものであることを理解することが重要です。有意義な予測力は、支出データを収益増加、地方税、償却、市場状況に関するデータと組み合わせた場合にのみ導き出されます
研究開発費 |
管理 |
# #マーケティング
|
投資収益 |
| 書き換える必要がある内容は次のとおりです: 165349.2 | ##136897.8
| 書き換える必要があるのは: 192261.83||
|
|
|
|
|
| #153441.51 | ##101145.55
|
|
以上が利益予測はもう難しくありません。scikit-learn 線形回帰手法を使用すると、半分の労力で 2 倍の結果を得ることができますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。