
 テクノロジー周辺機器AIGoogle の大規模モデル研究は激しい論争を引き起こしました。トレーニング データを超えた一般化能力が疑問視されており、ネットユーザーは AGI 特異点が遅れる可能性があると述べています。
テクノロジー周辺機器AIGoogle の大規模モデル研究は激しい論争を引き起こしました。トレーニング データを超えた一般化能力が疑問視されており、ネットユーザーは AGI 特異点が遅れる可能性があると述べています。Google の大規模モデル研究は激しい論争を引き起こしました。トレーニング データを超えた一般化能力が疑問視されており、ネットユーザーは AGI 特異点が遅れる可能性があると述べています。

Google DeepMind によって最近発見された新しい結果は、Transformer 分野で広範な論争を引き起こしました:
その一般化能力は、トレーニング データを超えるコンテンツには拡張できません。
この結論はまださらに検証されていませんが、多くの著名人を驚かせています。たとえば、ケラスの父親であるフランソワ・ショレ氏は、もしこのニュースが本当なら、と述べました。 、それは大きなニュースになるでしょう、モデル界では大きな出来事です。

Google Transformer は今日の大規模モデルの背後にあるインフラストラクチャであり、私たちがよく知っている GPT の「T」はそれを指します。
一連の大規模モデルは強力なコンテキスト学習機能を示し、例を迅速に学習して新しいタスクを完了できます。
しかし現在、Google の研究者もその致命的な欠陥を指摘しているようです。それは、トレーニング データ、つまり人間の既存の知識を超えると無力です。
一時期、多くの専門家は、AGI は再び手の届かないものになったと信じていました。
一部のネチズンは、論文には見落とされている重要な詳細がいくつかあると指摘しました。たとえば、実験には GPT-2 の規模のみが含まれ、トレーニングは含まれていませんデータが十分に豊富ではない
時間が経つにつれて、この論文を注意深く研究したネットユーザーが研究結果自体には何も間違っていないことを指摘するようになりましたが、人々はそれを踏まえた過剰な解釈。

この論文がネチズンの間で激しい議論を引き起こした後、著者の一人も次の 2 つの点を公に明らかにしました:
まず第一に、実験では単純なトランスフォーマーを使用しました。は「大きな」モデルでも言語モデルでもありません;
第二に、モデルは新しいタスクを学習できますが、新しいタイプタスク##に一般化することはできません。


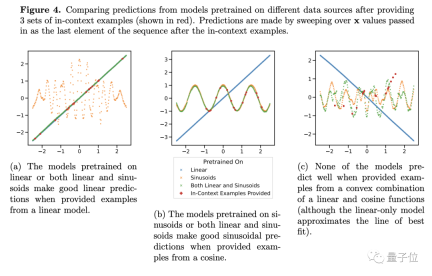
彼の結論をさらに検証するために、著者は線形または正弦関数の重みを調整しましたが、それでも Transformer の予測パフォーマンスは大きく変わりませんでした。
例外が 1 つだけあります。項目の 1 つの重みが 1 に近い場合、モデルの予測結果は実際の状況とより一致します。
##重みが 1 の場合、未知の新しい関数がトレーニング中に見られた関数になることを意味します。この種のデータは明らかにモデルの一般化能力には役立ちません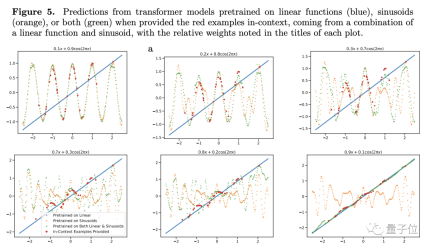
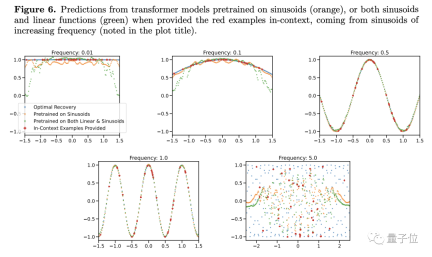 #したがって、著者は条件が少しでも良ければと考えていますが、それは少し異なります。大規模なモデルではどうすればよいかわかりません。これは一般化能力が低いということを意味しませんか?
#したがって、著者は条件が少しでも良ければと考えていますが、それは少し異なります。大規模なモデルではどうすればよいかわかりません。これは一般化能力が低いということを意味しませんか?
著者は、研究におけるいくつかの制限と、関数データの観察をトークン化された自然言語の問題に適用する方法についても説明します。
チームは言語モデルでも同様の実験を試みましたが、いくつかの障害に遭遇し、タスクファミリー(ここでは関数の種類に相当)や凸の組み合わせなどを適切に定義する方法はまだ解決されていません。
ただし、Samuel のモデルは規模が小さく、レイヤーが 4 つしかありません。Colab で 5 分間トレーニングした後は、線形関数と正弦関数の組み合わせに適用できます
##一般化できない場合はどうすればよいか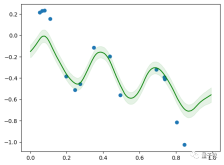
スローン賞受賞者でUCLA教授のGu Quanquan氏は、論文の結論自体は物議を醸すものではないが、過度に解釈すべきではないと述べた。 
Transformer の汎化能力を注意深く調査すると、残念ながらかなりの時間がかかると思います。弾丸だ、もう少し長く飛べ。 
は万能薬ではないため、この現象は実際には驚くべきことではありません。
トレーニング データが適切であるため、大規模モデルのパフォーマンスは良好です。私たちが重視するコンテンツ。
Jim はさらに付け加えました。「これは、1,000 億枚の犬と猫の写真を使用して視覚モデルをトレーニングし、そのモデルに航空機を識別させて、次のことを見つけてください、と言っているようなものです。」うわー、本当に彼のことを知りません。

この表現を中国語に変えてください。汎化能力が足りないので、学習サンプル以外のデータがなくなるまで学習させます。
それでは、この研究についてどう思いますか?
文書アドレス: https://arxiv.org/abs/2311.00871
以上がGoogle の大規模モデル研究は激しい論争を引き起こしました。トレーニング データを超えた一般化能力が疑問視されており、ネットユーザーは AGI 特異点が遅れる可能性があると述べています。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 踊りましょう:私たちの人間のニューラルネットを微調整するための構造化された動きApr 27, 2025 am 11:09 AM
踊りましょう:私たちの人間のニューラルネットを微調整するための構造化された動きApr 27, 2025 am 11:09 AM科学者は、彼らの機能を理解するために、人間とより単純なニューラルネットワーク(C. elegansのものと同様)を広く研究してきました。 ただし、重要な疑問が生じます。新しいAIと一緒に効果的に作業するために独自のニューラルネットワークをどのように適応させるのか
 新しいGoogleリークは、Gemini AIのサブスクリプションの変更を明らかにしますApr 27, 2025 am 11:08 AM
新しいGoogleリークは、Gemini AIのサブスクリプションの変更を明らかにしますApr 27, 2025 am 11:08 AMGoogleのGemini Advanced:Horizonの新しいサブスクリプションティア 現在、Gemini Advancedにアクセスするには、1か月あたり19.99ドルのGoogle One AIプレミアムプランが必要です。 ただし、Android Authorityのレポートは、今後の変更を示唆しています。 最新のGoogle p
 データ分析の加速がAIの隠されたボトルネックをどのように解決しているかApr 27, 2025 am 11:07 AM
データ分析の加速がAIの隠されたボトルネックをどのように解決しているかApr 27, 2025 am 11:07 AM高度なAI機能を取り巻く誇大宣伝にもかかわらず、エンタープライズAIの展開内に大きな課題が潜んでいます:データ処理ボトルネック。 CEOがAIの進歩を祝う間、エンジニアはクエリの遅い時間、過負荷のパイプライン、
 MarkitDown MCPは、任意のドキュメントをマークダウンに変換できます!Apr 27, 2025 am 09:47 AM
MarkitDown MCPは、任意のドキュメントをマークダウンに変換できます!Apr 27, 2025 am 09:47 AMドキュメントの取り扱いは、AIプロジェクトでファイルを開くだけでなく、カオスを明確に変えることです。 PDF、PowerPoint、Wordなどのドキュメントは、あらゆる形状とサイズでワークフローをフラッシュします。構造化された取得
 建物のエージェントにGoogle ADKを使用する方法は? - 分析VidhyaApr 27, 2025 am 09:42 AM
建物のエージェントにGoogle ADKを使用する方法は? - 分析VidhyaApr 27, 2025 am 09:42 AMGoogleのエージェント開発キット(ADK)のパワーを活用して、実際の機能を備えたインテリジェントエージェントを作成します。このチュートリアルは、ADKを使用して会話エージェントを構築し、GeminiやGPTなどのさまざまな言語モデルをサポートすることをガイドします。 w
 効果的な問題解決のためにLLMを介したSLMの使用 - 分析VidhyaApr 27, 2025 am 09:27 AM
効果的な問題解決のためにLLMを介したSLMの使用 - 分析VidhyaApr 27, 2025 am 09:27 AMまとめ: Small Language Model(SLM)は、効率のために設計されています。それらは、リソース不足、リアルタイム、プライバシーに敏感な環境の大手言語モデル(LLM)よりも優れています。 特にドメインの特異性、制御可能性、解釈可能性が一般的な知識や創造性よりも重要である場合、フォーカスベースのタスクに最適です。 SLMはLLMSの代替品ではありませんが、精度、速度、費用対効果が重要な場合に理想的です。 テクノロジーは、より少ないリソースでより多くを達成するのに役立ちます。それは常にドライバーではなく、プロモーターでした。蒸気エンジンの時代からインターネットバブル時代まで、テクノロジーの力は、問題の解決に役立つ範囲にあります。人工知能(AI)および最近では生成AIも例外ではありません
 コンピュータービジョンタスクにGoogle Geminiモデルを使用する方法は? - 分析VidhyaApr 27, 2025 am 09:26 AM
コンピュータービジョンタスクにGoogle Geminiモデルを使用する方法は? - 分析VidhyaApr 27, 2025 am 09:26 AMコンピュータービジョンのためのGoogleGeminiの力を活用:包括的なガイド 大手AIチャットボットであるGoogle Geminiは、その機能を会話を超えて拡張して、強力なコンピュータービジョン機能を網羅しています。 このガイドの利用方法については、
 Gemini 2.0 Flash vs O4-Mini:GoogleはOpenaiよりもうまくやることができますか?Apr 27, 2025 am 09:20 AM
Gemini 2.0 Flash vs O4-Mini:GoogleはOpenaiよりもうまくやることができますか?Apr 27, 2025 am 09:20 AM2025年のAIランドスケープは、GoogleのGemini 2.0 FlashとOpenaiのO4-Miniの到着とともに感動的です。 数週間離れたこれらの最先端のモデルは、同等の高度な機能と印象的なベンチマークスコアを誇っています。この詳細な比較


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

Safe Exam Browser
Safe Exam Browser は、オンライン試験を安全に受験するための安全なブラウザ環境です。このソフトウェアは、あらゆるコンピュータを安全なワークステーションに変えます。あらゆるユーティリティへのアクセスを制御し、学生が無許可のリソースを使用するのを防ぎます。

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

SublimeText3 中国語版
中国語版、とても使いやすい

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター
ホットトピック
 7767
7767 15164414139952129325123429
15164414139952129325123429