
ホームページ >テクノロジー周辺機器 >AI >機械学習における正則化とは何ですか?
機械学習における正則化とは何ですか?

- 王林転載
- 2023-11-06 11:25:011015ブラウズ
1. はじめに
機械学習の分野では、トレーニング プロセス中に関連するモデルが過学習または過小学習になる可能性があります。これを防ぐために、機械学習で正則化操作を使用してモデルをテストセットに適切に適合させます。一般に、正則化操作は、過学習や過小学習の可能性を減らすことで、誰もが最適なモデルを取得できるようにします。
この記事では、正則化とは何か、正則化の種類について理解します。さらに、バイアス、分散、過小適合、過適合などの関連する概念についても説明します。
くだらない話はやめて、始めましょう!
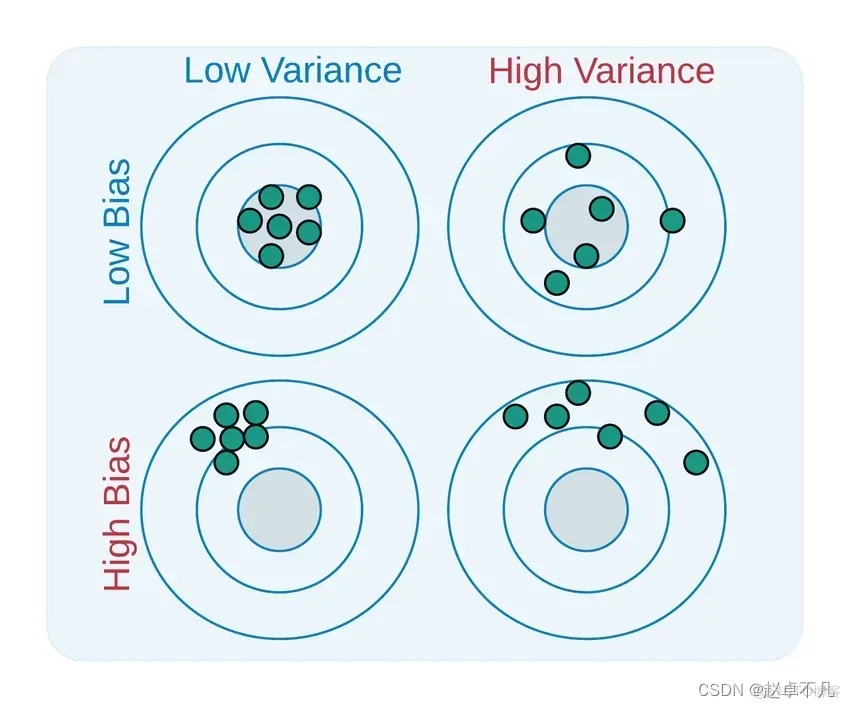
2. バイアスと分散
バイアスと分散は、学習したモデルと実際のモデルを説明するために使用されます。ギャップの 2 つの側面
を書き直す必要があります。この 2 つの定義は次のとおりです。
- バイアスとは、 use all 可能なトレーニング データ セットでトレーニングされたすべてのモデルの出力の平均と、真のモデルの出力値の差。
- 分散は、異なるトレーニング データセットでトレーニングされたモデルの出力値間の差です。
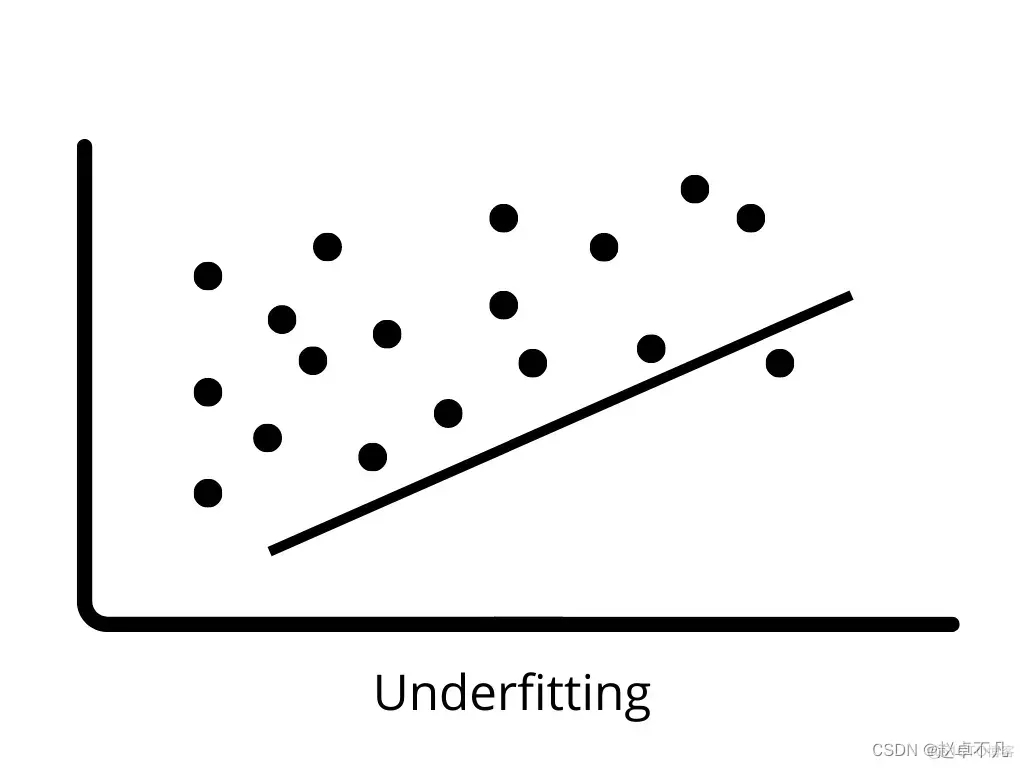
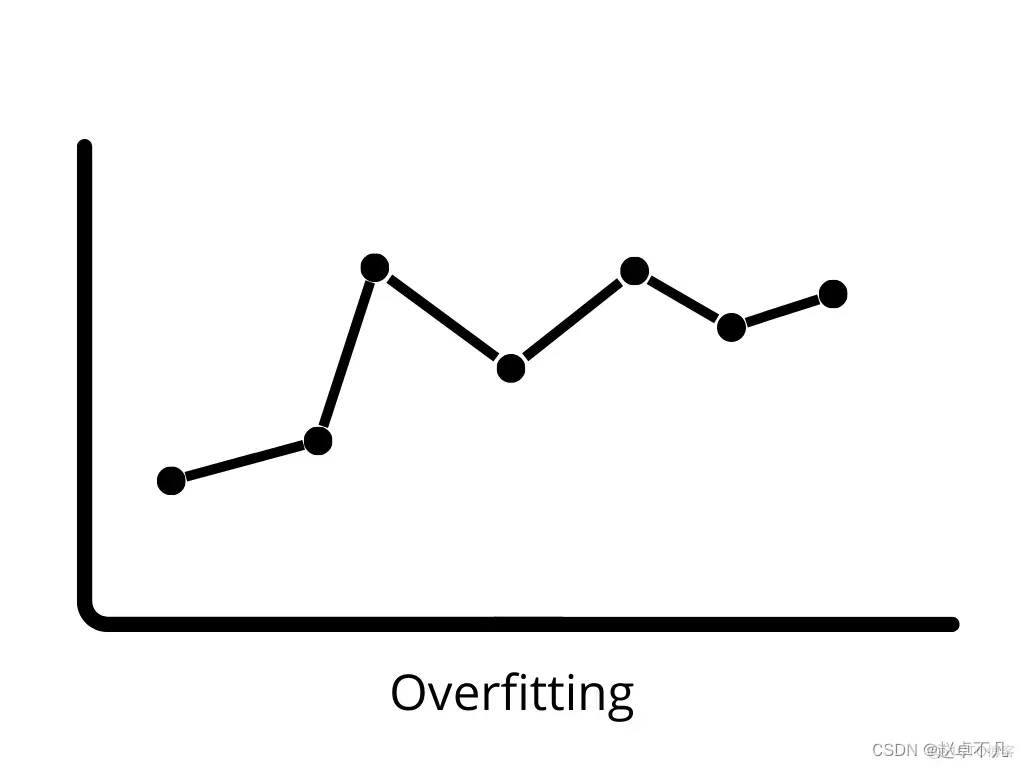
# #4.過学習
モデルがトレーニング データでは非常に優れたパフォーマンスを発揮するが、テスト データではパフォーマンスが低下する場合、それは過学習 (新しいデータ) と呼ばれます。この場合、機械学習モデルはトレーニング データのノイズに適合し、テスト データに対するモデルのパフォーマンスに悪影響を及ぼします。バイアスが低く分散が大きいと、過学習が発生する可能性があります。
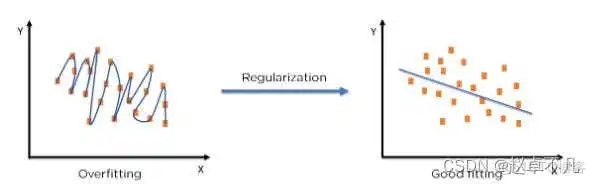
5. 正則化の概念
「規則的な」という用語「」では、調整された損失関数を削減し、過剰適合または過小適合を回避するために機械学習モデルを調整する方法について説明します。
#6.L1 正則化
#カラー回帰と比較して、L1 正則化の実装は主に損失関数にペナルティ項を追加することです。この項のペナルティ値は、次のようにすべての係数の絶対値の合計です。
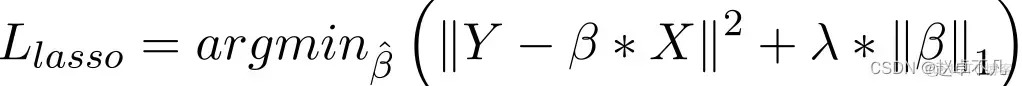
Lasso 回帰モデルでは、回帰係数の絶対値を増やすことでペナルティが増加します。リッジ回帰項目と同様の方法で実現します。さらに、L1 正則化は、線形回帰モデルの精度を向上させる優れたパフォーマンスを発揮します。同時に、L1 正則化はすべてのパラメーターに均等にペナルティを課すため、一部の重みがゼロになる可能性があり、その結果、特定の特徴を削除できるスパース モデルが生成されます (重み 0 は削除と同等です)。
#7. L2 正則化
L2 正則化は、損失関数にペナルティ項を追加することによっても実現されます。ペナルティ項はすべての係数の二乗の合計に等しいということです。次のように:##############################
一般に、データが多重共線性 (独立変数の相関性が高い) を示す場合に採用される手法と考えられます。多重共線性における最小二乗推定 (OLS) は不偏ですが、分散が大きいため、観測値が実際の値と大きく異なる可能性があります。 L2 により、回帰推定の誤差がある程度減少します。通常、多重共線性の問題を解決するには収縮パラメーターを使用します。 L2 正則化により、重みの固定比率が減り、重みが平滑化されます。
8. 概要
上記の分析を経て、この記事の関連する正則化に関する知識は次のように要約されます。
##L1 正則化では、特徴の選択に使用できる疎な重み行列、つまり疎なモデルを生成できます; L2 正則化では、モデルの過学習を防ぐことができます。ある程度、L1 は過学習を防止し、モデルの汎化能力を向上させることもできます。L1 (ラグランジュ) 正則化では、パラメーターの事前分布がラプラス分布であると仮定し、モデルのスパース性を確保できます。つまり、一部のパラメータは 0 に等しくなります。L2 (リッジ回帰) の仮定は、パラメータの事前分布がガウス分布であるということであり、これによりモデルの安定性が保証されます。 実際のアプリケーションでは、特徴が高次元で疎である場合は、L1 正則化を使用する必要があります。特徴が低次元で密である場合は、L1 正則化を使用する必要があります。 、L2 正規化を使用する必要があります以上が機械学習における正則化とは何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。