
ホームページ >テクノロジー周辺機器 >AI >大規模モデルの波にさらされる時系列予測に関する記事
大規模モデルの波にさらされる時系列予測に関する記事

- 王林転載
- 2023-11-06 08:13:381243ブラウズ
今日は、時系列予測における大規模モデルの応用についてお話します。 NLP の分野における大規模モデルの開発に伴い、時系列予測の分野に大規模モデルを適用しようとする試みがますます増えています。この記事では、大規模モデルを時系列予測に適用する主な方法を紹介し、大規模モデル時代の時系列予測の研究方法を誰もが理解できるように、最近の関連研究をいくつかまとめます。
1. 大規模モデルの時系列予測手法
過去 3 か月間で、大規模モデルの時系列予測作業が数多く登場しましたが、それらは基本的に 2 つのタイプに分類できます。
内容を書き直しました: 1 つの方法は、時系列予測に NLP の大規模モデルを直接使用することです。この手法では、時系列予測に GPT や Llama などの大規模 NLP モデルを使用しますが、時系列データをいかに大規模モデルの入力に適したデータに変換するかが鍵となります。時系列学習の分野にある大型モデルです。このタイプの方法では、多数の時系列データ セットを使用して、時系列フィールドで GPT や Llama などの大規模なモデルを共同トレーニングし、それをダウンストリームの時系列タスクに使用します。
上記の 2 種類の方法を考慮して、関連する古典的な大規模モデルの時系列表現作品をいくつか紹介します。
2. NLP の大規模モデルを時系列に適用する
この方法は、大規模モデルの時系列予測作業の最も初期のバッチです
ニューヨーク大学とカーネギーメロンの論文では、「大学が共同出版した「ゼロサンプル時系列予測子としての大規模言語モデル」では、時系列のデジタル表現は、GPT などの大規模モデルで認識できる入力に変換するためにトークン化されるように設計されています。そしてラマ。大規模モデルが異なれば数値のトークン化方法も異なるため、異なるモデルを使用する場合はパーソナライゼーションが必要になります。たとえば、GPT は数値の文字列を異なるサブシーケンスに分割します。これはモデルの学習に影響します。したがって、この記事では、GPT の入力形式に対応するために、数値の間にスペースを強制的に挿入します。最近リリースされた LLaMa などの大型モデルの場合は、個別の番号が区切られていることが多いため、スペースを追加する必要はありません。同時に、時系列値が大きすぎるために入力シーケンスが長すぎることを避けるために、この記事ではいくつかのスケーリング操作を実行して、元の時系列の値をより適切な範囲に制限します。
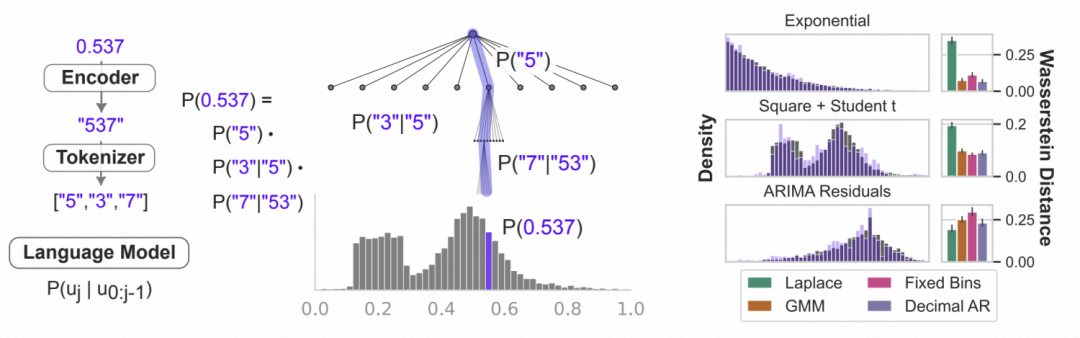
Picture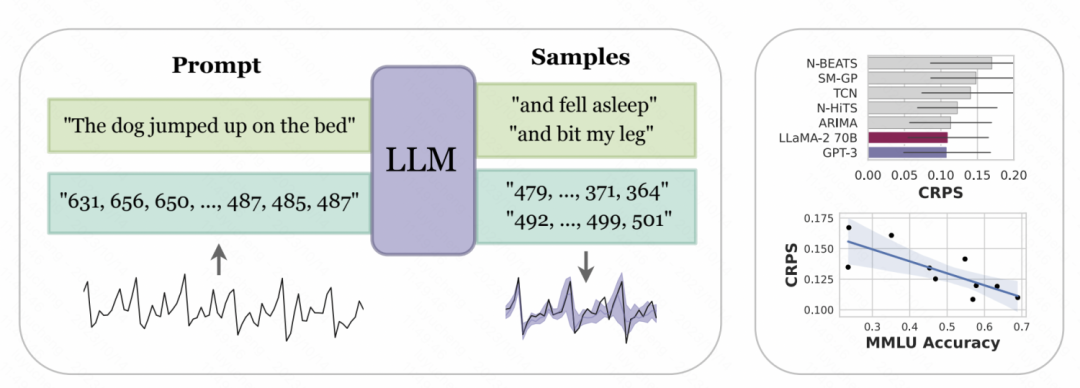 上記で処理されたデジタル文字列が大規模モデルに入力され、大規模モデルが自己回帰的に次の数値を予測し、最終的に予測された数値を次の数値に変換できるようになります。対応する時系列値。下の図は概略図を示しています. 言語モデルの条件付き確率を数値のモデル化に使用することは, 前の数値に基づいて次の桁が各数値である確率を予測することです. これは反復的な階層的ソフトマックス構造であり, 表現能力を加えたものです大規模モデルの は、さまざまな分布タイプに適応できるため、このように大規模モデルを時系列予測に使用できます。同時に、モデルによって予測された次の数値の確率を不確実性の予測に変換して、時系列の不確実性の推定を実現することもできます。
上記で処理されたデジタル文字列が大規模モデルに入力され、大規模モデルが自己回帰的に次の数値を予測し、最終的に予測された数値を次の数値に変換できるようになります。対応する時系列値。下の図は概略図を示しています. 言語モデルの条件付き確率を数値のモデル化に使用することは, 前の数値に基づいて次の桁が各数値である確率を予測することです. これは反復的な階層的ソフトマックス構造であり, 表現能力を加えたものです大規模モデルの は、さまざまな分布タイプに適応できるため、このように大規模モデルを時系列予測に使用できます。同時に、モデルによって予測された次の数値の確率を不確実性の予測に変換して、時系列の不確実性の推定を実現することもできます。
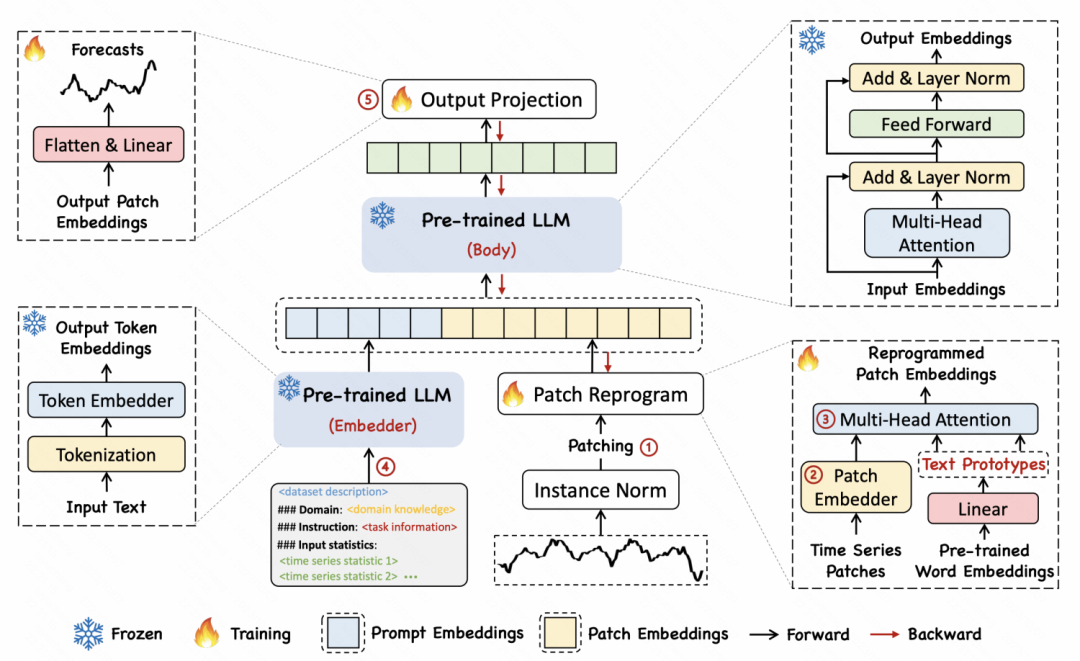
 「TIME-LLM: 大規模言語モデルの再プログラミングによる時系列予測」というタイトルの別の記事で、著者は、次のような再プログラミング手法を提案しました。時系列をテキストに変換して、時系列とテキストの 2 つの形式の間の位置合わせを実現します。
「TIME-LLM: 大規模言語モデルの再プログラミングによる時系列予測」というタイトルの別の記事で、著者は、次のような再プログラミング手法を提案しました。時系列をテキストに変換して、時系列とテキストの 2 つの形式の間の位置合わせを実現します。
 3. 時系列大規模モデル
3. 時系列大規模モデル
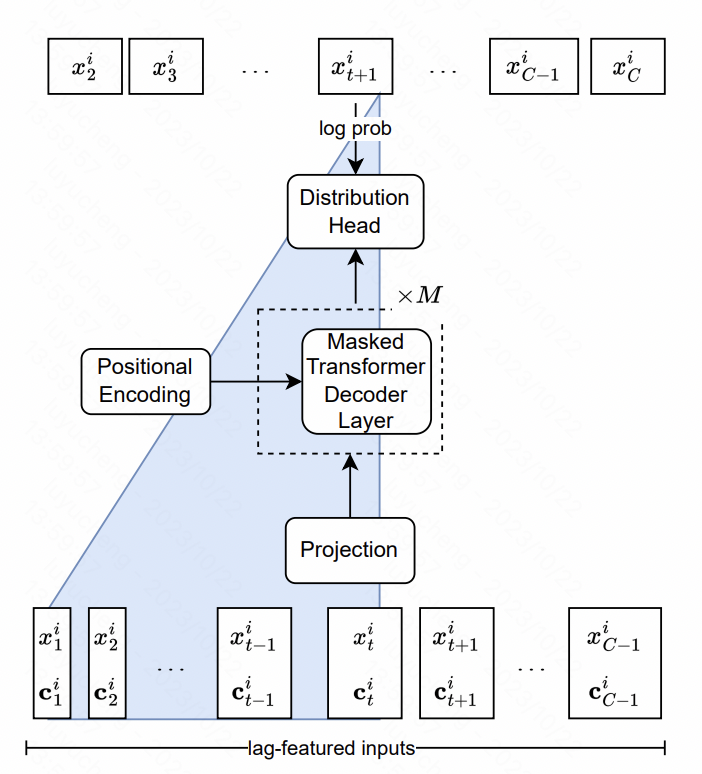
特徴の点では、この記事では、主に元の時系列のさまざまな時間窓の履歴シーケンス統計値であるマルチスケールおよびマルチタイプのラグ特徴を抽出します。これらのシーケンスは追加の特徴としてモデルに入力されます。モデル構造の観点から見ると、NLP における LlaMA 構造の中核は Transformer であり、正規化方法と位置エンコード部分が最適化されています。最後の出力層は、複数のヘッドを使用して確率分布のパラメーターを適合させます。たとえば、ガウス分布は平均分散に適合します。この記事では、スチューデント t 分布が使用され、自由度、平均、スケールの 3 つの対応するパラメーターが使用されます。を出力し、最終的に各時刻を求め、その点の予測確率分布結果を求めます。
 写真
写真
もう 1 つの同様の成果は、時系列フィールドで GPT モデルを構築する TimeGPT-1 です。データ トレーニングの観点から、TimeGPT はさまざまな種類のドメイン データを含む、合計 100 億のデータ サンプル ポイントに達する大量の時系列データを使用します。トレーニング中は、トレーニングの堅牢性を向上させるために、より大きなバッチ サイズとより小さな学習率が使用されます。モデルの主な構造は古典的な GPT モデルです
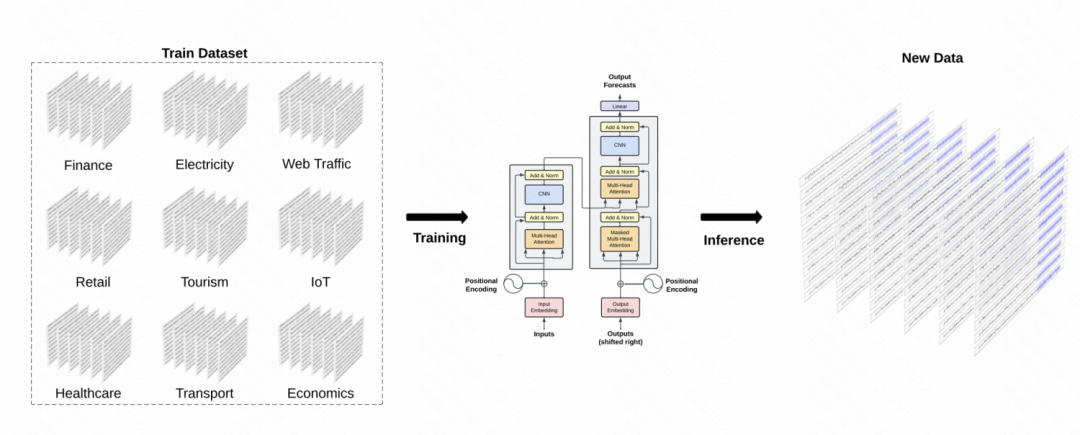 写真
写真
次の実験結果からもわかるように、一部のゼロショット学習では時系列で事前トレーニングされた大規模モデルは、基本モデルと比較して大幅な改善を達成しました。
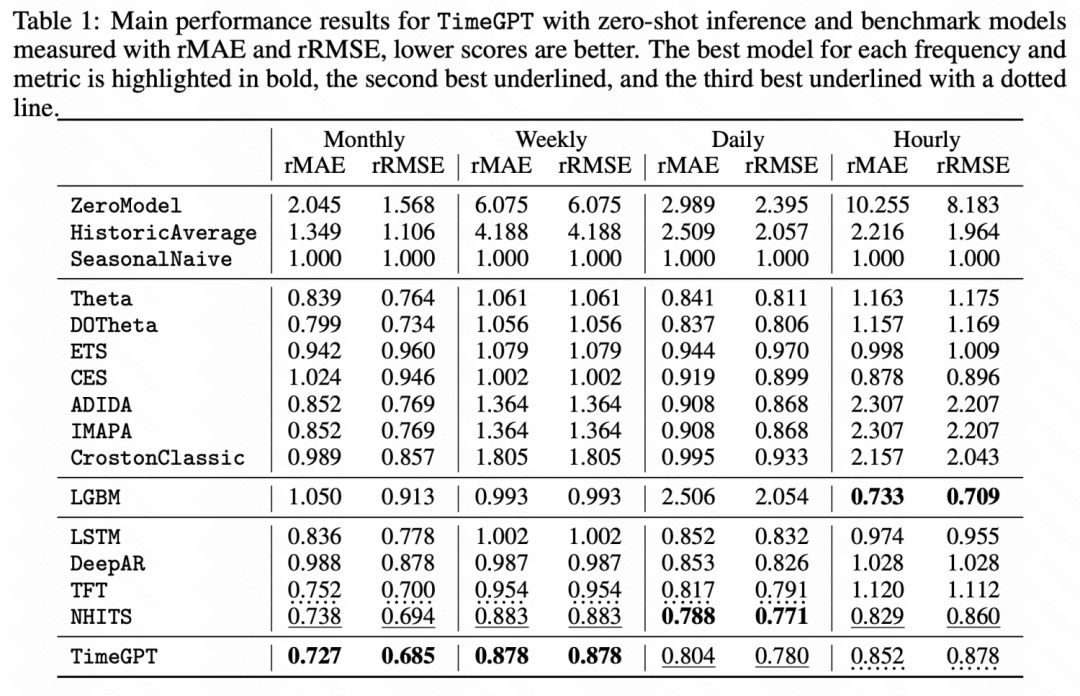 写真
写真
4. 概要
この記事では、直接モデルを含む大規模モデルの波の下での時系列予測の研究アイデアを紹介します。 NLP 大規模モデルを使用して、時系列予測を行い、時系列フィールドで大規模モデルをトレーニングします。どの方法が使用されるとしても、それは大規模モデル時系列の可能性を示しており、詳細な研究に値する方向性です。
以上が大規模モデルの波にさらされる時系列予測に関する記事の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。