



強化学習 (RL) は、エージェントが試行錯誤を通じて環境内でどのように動作するかを学習できる機械学習手法です。エージェントは、望ましい結果につながるアクションを実行すると、報酬または罰を受けます。時間が経つにつれて、エージェントは期待される報酬を最大化するアクションを取ることを学習します
RL エージェントは通常、数学的フレームワークであるマルコフ決定プロセス (MDP) を使用します。逐次的な意思決定問題をモデル化します。 MDP は 4 つの部分で構成されます。
- #状態: 環境の可能な状態のセット。
- アクション: エージェントが実行できる一連のアクション。
- 遷移関数: 現在の状態とアクションを考慮して、新しい状態に遷移する確率を予測する関数。
- 報酬関数: コンバージョンごとにエージェントに報酬を割り当てる関数。
エージェントの目標は、状態をアクションにマッピングするポリシー機能を学習することです。ポリシー機能を通じて、エージェントの長期にわたる期待収益を最大化します。
ディープ Q ラーニングは、ディープ ニューラル ネットワークを使用してポリシー関数を学習する強化学習アルゴリズムです。ディープ ニューラル ネットワークは現在の状態を入力として受け取り、値のベクトルを出力します。各値は可能なアクションを表します。その後、エージェントは最も高い値に基づいてアクションを実行します。
ディープ Q ラーニングは、値ベースの強化学習アルゴリズムです。つまり、各状態とアクションのペアの値を学習します。状態とアクションのペアの値は、その状態でエージェントがそのアクションを実行することで期待される報酬です。
Actor-Critic は、価値ベースとポリシーベースを組み合わせた RL アルゴリズムです。 2 つのコンポーネントがあります:
#アクター: アクターは操作の選択を担当します。
批評家: アクターの動作を評価する責任があります。
俳優と批評家は同時に訓練を受けます。アクターは期待される報酬を最大化するようにトレーニングされ、批評家は各状態アクションのペアの期待される報酬を正確に予測するようにトレーニングされます。
アクター-クリティック アルゴリズムには、他の強化学習アルゴリズムの利点に比べていくつかの利点があります。まず、より安定しているため、トレーニング中にバイアスが発生する可能性が低くなります。第二に、より効率的であり、より速く学習できることを意味します。第三に、スケーラビリティが向上し、大きな状態空間と操作空間を持つ問題に適用できます。
下の表は、Deep Q-learning と Actor-Critic の違いをまとめたものです。主な違いは次のとおりです。

Actor-Critic (A2C) の利点
Actor-Critic は、一般的な強化学習アーキテクチャです。ポリシーベースのアプローチと価値ベースのアプローチを組み合わせています。これには、さまざまな強化学習タスクを解決するための強力な選択肢となる多くの利点があります:
1. 低い分散
従来のポリシーとの比較勾配法では、A2C は通常、トレーニング中の分散が低くなります。これは、A2C がポリシー勾配と値関数の両方を使用し、勾配の計算の分散を減らすために値関数を使用するためです。分散が低いということは、トレーニング プロセスがより安定しており、より良い戦略により早く収束できることを意味します
2. 学習速度の向上
原因:分散が低いという特徴により、A2C は通常、優れた戦略をより早く学習できます。学習速度が速くなることで貴重な時間とコンピューティング リソースが節約されるため、これは広範なシミュレーションを必要とするタスクでは特に重要です。
3. ポリシーと価値関数の組み合わせ
A2C の特徴の 1 つは、ポリシーと価値関数を同時に学習することです。この組み合わせにより、エージェントは環境とアクションの相関関係をよりよく理解できるようになり、ポリシーの改善をより適切に導くことができます。値関数の存在は、ポリシー最適化におけるエラーを減らし、トレーニング効率を向上させるのにも役立ちます。
4. 連続アクション スペースと離散アクション スペースのサポート
A2C は、連続アクションと離散アクションを含む、さまざまなタイプのアクション スペースに適応できます。非常に多用途です。これにより、A2C は、ロボット制御からゲームプレイの最適化まで、さまざまなタスクに適用できる、広く適用可能な強化学習アルゴリズムになります。
5. 並列トレーニング
#A2C は簡単に並列化して、マルチコア プロセッサと分散コンピューティング リソースを最大限に活用できます。これは、より短い時間でより多くの経験的データを収集できることを意味し、トレーニング効率が向上します。
Actor-Critic 手法にはいくつかの利点がありますが、ハイパーパラメータの調整やトレーニングにおける潜在的な不安定性など、いくつかの課題にも直面しています。ただし、エクスペリエンス リプレイやターゲット ネットワークなどの適切な調整とテクニックを使用すると、これらの課題を大幅に軽減できるため、Actor-Critic は強化学習における貴重なアプローチになります
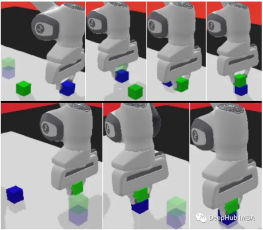
panda-gym
##panda-gym は PyBullet エンジンに基づいて開発されており、リーチ、プッシュ、スライドなど 6 つのタスクをカプセル化しています。 pick&place、stack、flip は主に OpenAI Fetch からインスピレーションを得ています。
1. インストールライブラリ
まず、強化学習環境のコードを初期化する必要があります:
!apt-get install -y \libgl1-mesa-dev \libgl1-mesa-glx \libglew-dev \xvfb \libosmesa6-dev \software-properties-common \patchelf !pip install \free-mujoco-py \pytorch-lightning \optuna \pyvirtualdisplay \PyOpenGL \PyOpenGL-accelerate\stable-baselines3[extra] \gymnasium \huggingface_sb3 \huggingface_hub \ panda_gym
2. ライブラリをインポート import os import gymnasium as gym import panda_gym from huggingface_sb3 import load_from_hub, package_to_hub from stable_baselines3 import A2C from stable_baselines3.common.evaluation import evaluate_policy from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize from stable_baselines3.common.env_util import make_vec_env
3. 実行環境を作成するenv_id = "PandaReachDense-v3" # Create the env env = gym.make(env_id) # Get the state space and action space s_size = env.observation_space.shape a_size = env.action_space print("\n _____ACTION SPACE_____ \n") print("The Action Space is: ", a_size) print("Action Space Sample", env.action_space.sample()) # Take a random action
4. 観察と報酬の標準化
最適化するための良い方法強化学習は、入力特徴を正規化して最適化することです。ラッパーを通じて入力フィーチャの移動平均と標準偏差を計算します。同時に、norm_reward = True
env = make_vec_env(env_id, n_envs=4) env = VecNormalize(env, norm_obs=True, norm_reward=True, clip_obs=10.)
5 を追加することで報酬が正規化されます。A2C モデルを作成します
公式モデルを使用しますStable-Baselines3 チームによるトレーニング エージェント
model = A2C(policy = "MultiInputPolicy",env = env,verbose=1)
6、トレーニング A2Cmodel.learn(1_000_000) # Save the model and VecNormalize statistics when saving the agent model.save("a2c-PandaReachDense-v3") env.save("vec_normalize.pkl")
7、評価エージェントfrom stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize # Load the saved statistics eval_env = DummyVecEnv([lambda: gym.make("PandaReachDense-v3")]) eval_env = VecNormalize.load("vec_normalize.pkl", eval_env) # We need to override the render_mode eval_env.render_mode = "rgb_array" # do not update them at test time eval_env.training = False # reward normalization is not needed at test time eval_env.norm_reward = False # Load the agent model = A2C.load("a2c-PandaReachDense-v3") mean_reward, std_reward = evaluate_policy(model, eval_env) print(f"Mean reward = {mean_reward:.2f} +/- {std_reward:.2f}")
まとめ
「panda-gym」では、Panda ロボットアームと GYM 環境を効果的に組み合わせることで、ローカルでロボットアームの強化学習を簡単に実行できます。
Actor-Critic アーキテクチャでは、エージェントはタイム ステップごとに段階的に改善することを学習します。これは、スパース報酬関数 (結果がバイナリである) とは対照的です。 Actor-Critic メソッドは、そのようなタスクに特に適しています。
ポリシー学習と価値推定をシームレスに組み合わせることで、ロボット エージェントはロボット アームのエンド エフェクターを巧みに操作して、指定された目標位置に正確に到達することができます。これは、ロボット制御などのタスクに実用的なソリューションを提供するだけでなく、機敏で情報に基づいた意思決定を必要とするさまざまな分野を変革する可能性を秘めています。
以上がPanda-Gym のロボット アーム シミュレーションを使用した Deep Q-learning 強化学習の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 迅速なエンジニアリングにおける思考のグラフは何ですかApr 13, 2025 am 11:53 AM
迅速なエンジニアリングにおける思考のグラフは何ですかApr 13, 2025 am 11:53 AM導入 迅速なエンジニアリングでは、「思考のグラフ」とは、グラフ理論を使用してAIの推論プロセスを構造化および導く新しいアプローチを指します。しばしば線形sを含む従来の方法とは異なります
 Genaiエージェントとの電子メールマーケティングを組織に最適化しますApr 13, 2025 am 11:44 AM
Genaiエージェントとの電子メールマーケティングを組織に最適化しますApr 13, 2025 am 11:44 AM導入 おめでとう!あなたは成功したビジネスを運営しています。ウェブページ、ソーシャルメディアキャンペーン、ウェビナー、会議、無料リソース、その他のソースを通じて、毎日5000の電子メールIDを収集します。次の明白なステップはです
 Apache Pinotによるリアルタイムアプリのパフォーマンス監視Apr 13, 2025 am 11:40 AM
Apache Pinotによるリアルタイムアプリのパフォーマンス監視Apr 13, 2025 am 11:40 AM導入 今日のペースの速いソフトウェア開発環境では、最適なアプリケーションパフォーマンスが重要です。応答時間、エラーレート、リソース利用などのリアルタイムメトリックを監視することで、メインに役立ちます
 ChatGptは10億人のユーザーにヒットしますか? 「わずか数週間で2倍になりました」とOpenai CEOは言いますApr 13, 2025 am 11:23 AM
ChatGptは10億人のユーザーにヒットしますか? 「わずか数週間で2倍になりました」とOpenai CEOは言いますApr 13, 2025 am 11:23 AM「ユーザーは何人いますか?」彼は突き出した。 「私たちが最後に言ったのは毎週5億人のアクティブであり、非常に急速に成長していると思います」とアルトマンは答えました。 「わずか数週間で2倍になったと言った」とアンダーソンは続けた。 「私はそのprivと言いました
 PIXTRAL -12B:Mistral AI'の最初のマルチモーダルモデル-Analytics VidhyaApr 13, 2025 am 11:20 AM
PIXTRAL -12B:Mistral AI'の最初のマルチモーダルモデル-Analytics VidhyaApr 13, 2025 am 11:20 AM導入 Mistralは、最初のマルチモーダルモデル、つまりPixtral-12B-2409をリリースしました。このモデルは、Mistralの120億個のパラメーターであるNemo 12bに基づいて構築されています。このモデルを際立たせるものは何ですか?これで、画像とTexの両方を採用できます
 生成AIアプリケーションのエージェントフレームワーク - 分析VidhyaApr 13, 2025 am 11:13 AM
生成AIアプリケーションのエージェントフレームワーク - 分析VidhyaApr 13, 2025 am 11:13 AMクエリに応答するだけでなく、情報を自律的に収集し、タスクを実行し、テキスト、画像、コードなどの複数のタイプのデータを処理するAIを搭載したアシスタントがいることを想像してください。未来的に聞こえますか?これでa
 金融セクターにおける生成AIの応用Apr 13, 2025 am 11:12 AM
金融セクターにおける生成AIの応用Apr 13, 2025 am 11:12 AM導入 金融業界は、効率的な取引と信用の可用性を促進することにより経済成長を促進するため、あらゆる国の発展の基礎となっています。取引の容易さとクレジット
 オンライン学習とパッシブアグレッシブアルゴリズムのガイドApr 13, 2025 am 11:09 AM
オンライン学習とパッシブアグレッシブアルゴリズムのガイドApr 13, 2025 am 11:09 AM導入 データは、ソーシャルメディア、金融取引、eコマースプラットフォームなどのソースから前例のないレートで生成されています。この連続的な情報ストリームを処理することは課題ですが、


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

ドリームウィーバー CS6
ビジュアル Web 開発ツール

MantisBT
Mantis は、製品の欠陥追跡を支援するために設計された、導入が簡単な Web ベースの欠陥追跡ツールです。 PHP、MySQL、Web サーバーが必要です。デモおよびホスティング サービスをチェックしてください。

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

MinGW - Minimalist GNU for Windows
このプロジェクトは osdn.net/projects/mingw に移行中です。引き続きそこでフォローしていただけます。 MinGW: GNU Compiler Collection (GCC) のネイティブ Windows ポートであり、ネイティブ Windows アプリケーションを構築するための自由に配布可能なインポート ライブラリとヘッダー ファイルであり、C99 機能をサポートする MSVC ランタイムの拡張機能が含まれています。すべての MinGW ソフトウェアは 64 ビット Windows プラットフォームで実行できます。

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

