Stable Diffusion にも慣れてきましたが、ついに Apple 製の Matryoshka スタイルの Diffusion モデルを手に入れることができました。
#生成 AI の時代では、拡散モデルは、画像、ビデオ、3D、オーディオ、そしてテキスト生成。ただし、モデルは各ステップですべての高解像度入力を再コード化する必要があるため、拡散モデルを高解像度ドメインに拡張することは依然として大きな課題に直面しています。これらの課題を解決するには、アテンション ブロックを備えたディープ アーキテクチャを使用する必要があります。これにより、最適化がより困難になり、より多くのコンピューティング パワーとメモリが消費されます。 ###############どうやってするの?最近の研究の中には、高解像度画像のための効率的なネットワーク アーキテクチャの調査に焦点を当てたものもあります。ただし、既存の方法はいずれも 512 × 512 の解像度を超える結果を実証しておらず、生成品質は主流のカスケードまたは潜在的な方法に比べて遅れています。 OpenAI DALL-E 2、Google IMAGEN、NVIDIA eDiffI を例として取り上げますが、これらは低解像度モデルと複数の超解像度拡散モデルを学習することで計算量を節約します。 、各コンポーネントは個別にトレーニングされます。一方、潜在拡散モデル (LDM) は低解像度の拡散モデルのみを学習し、個別にトレーニングされた高解像度のオートエンコーダーに依存します。どちらのソリューションでも、多段階のパイプラインによりトレーニングと推論が複雑になり、多くの場合、慎重な調整やハイパーパラメーターが必要になります。 この記事では、研究者らは、エンドツーエンドの高解像度画像生成のための新しい拡散モデルであるマトリョーシカ拡散モデル (MDM) を提案します。コードは近日公開予定です。 論文アドレス: https://arxiv.org/pdf/2310.15111.pdf
研究では、主なアイデアは、ネストされた UNet アーキテクチャを使用して複数の解像度で共同拡散プロセスを実行することにより、高解像度生成の一部として低解像度の拡散プロセスを使用することです。 調査では、MDM とネストされた UNet アーキテクチャが連携して、1) 多重解像度損失: 高解像度入力ノイズ除去の収束速度を大幅に向上、2) 効率的なプログレッシブを実現することがわかりました。トレーニング計画。低解像度の拡散モデルのトレーニングから始まり、計画に従って徐々に高解像度の入力と出力を追加します。実験結果は、多重解像度損失とプログレッシブ トレーニングを組み合わせることで、トレーニング コストとモデルの品質の間でより良いバランスを達成できることを示しています。 この研究では、クラス条件付き画像生成とテキスト条件付き画像およびビデオ生成に関する MDM を評価します。 MDM を使用すると、カスケードや潜在拡散を使用せずに高解像度モデルをトレーニングできます。アブレーション研究では、多重解像度損失とプログレッシブ トレーニングの両方がトレーニングの効率と質を大幅に向上させることが示されています。 MDM によって生成された次の写真とビデオを楽しみましょう。  #方法の概要
#方法の概要
研究者の紹介MDM 拡散モデルは、階層構造のデータ形成を活用しながら、高解像度でエンドツーエンドでトレーニングされます。 MDM は、まず拡散空間における標準拡散モデルを一般化してから、専用のネストされたアーキテクチャとトレーニング プロセスを提案します。 まず、拡張空間で
を一般化する方法を見てみましょう。
カスケード法や潜在法との違いは、MDM が拡張空間に多重解像度の拡散プロセスを導入することで、階層構造を持つ単一の拡散プロセスを学習することです。詳細を以下の図 2 に示します。 具体的には、データ点 x ∈ R^N が与えられた場合、研究者は時間関連の潜在変数 z_t = z_t^1, . . . , z_t^R ∈ を定義します。 R^N_1...NR。
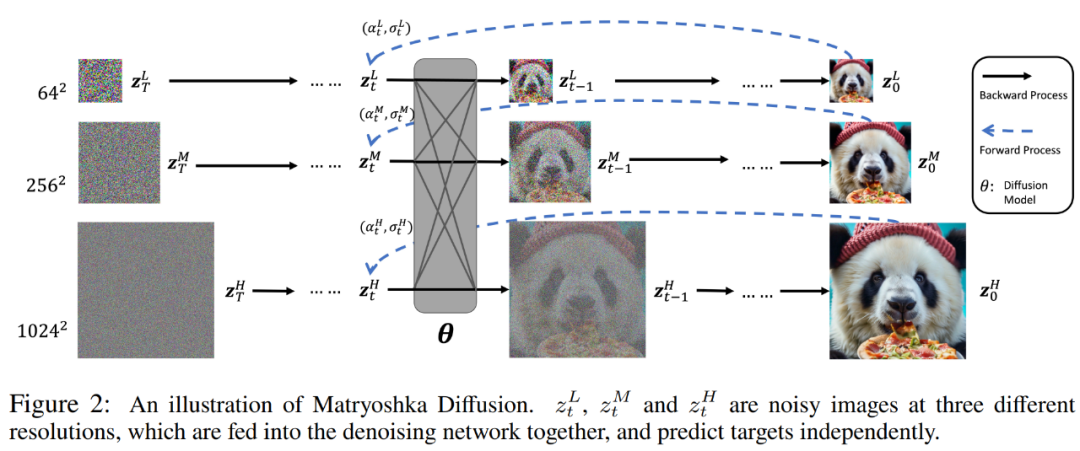 研究者らは、拡張空間で拡散モデリングを行うことには次の 2 つの利点があると述べています。 1 つは、通常、推論中にフル解像度の出力 z_t^R を考慮するため、他のすべての中間解像度が追加の潜在変数 z_t^r として扱われるため、分布のモデル化が複雑になります。第 2 に、多重解像度の依存関係により、z_t^r 全体で重みと計算を共有する機会が得られ、それによって計算がより効率的に再分散され、効率的なトレーニングと推論が可能になります。 ネストされたアーキテクチャ (NestedUNet) がどのように機能するか見てみましょう。 典型的な拡散モデルと同様に、研究者は UNet ネットワーク構造を使用して MDM を実装します。この場合、残差接続と計算ブロックが並行して使用され、きめの細かい入力情報が保存されます。ここの計算ブロックには、畳み込み層とセルフアテンション層の複数の層が含まれています。 NestedUNet と標準 UNet のコードは次のとおりです。
研究者らは、拡張空間で拡散モデリングを行うことには次の 2 つの利点があると述べています。 1 つは、通常、推論中にフル解像度の出力 z_t^R を考慮するため、他のすべての中間解像度が追加の潜在変数 z_t^r として扱われるため、分布のモデル化が複雑になります。第 2 に、多重解像度の依存関係により、z_t^r 全体で重みと計算を共有する機会が得られ、それによって計算がより効率的に再分散され、効率的なトレーニングと推論が可能になります。 ネストされたアーキテクチャ (NestedUNet) がどのように機能するか見てみましょう。 典型的な拡散モデルと同様に、研究者は UNet ネットワーク構造を使用して MDM を実装します。この場合、残差接続と計算ブロックが並行して使用され、きめの細かい入力情報が保存されます。ここの計算ブロックには、畳み込み層とセルフアテンション層の複数の層が含まれています。 NestedUNet と標準 UNet のコードは次のとおりです。

NestedUNet では、他の階層メソッドと比較した単純さに加えて、最も効率的な方法で計算を分散できます。以下の図 3 に示すように、研究者による初期の調査により、MDM はほとんどのパラメーターと計算を最低の解像度で割り当てた場合に大幅に優れたスケーラビリティを達成できることがわかりました。 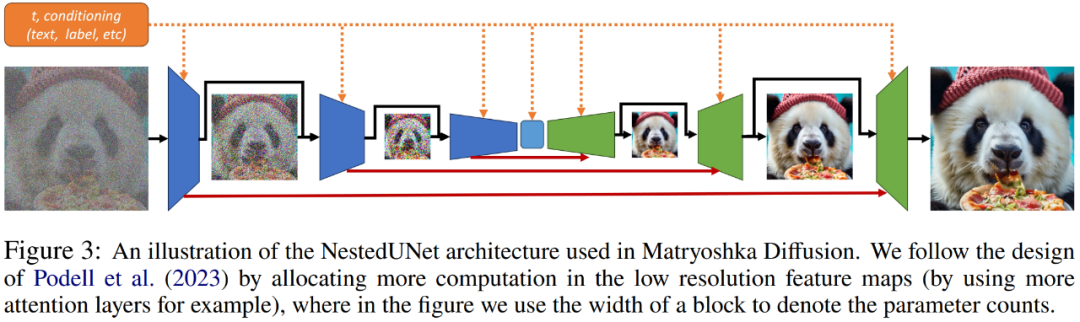
研究者は、以下の式 (3) に示すように、従来のノイズ除去ターゲットを使用して、複数の解像度で MDM をトレーニングします。 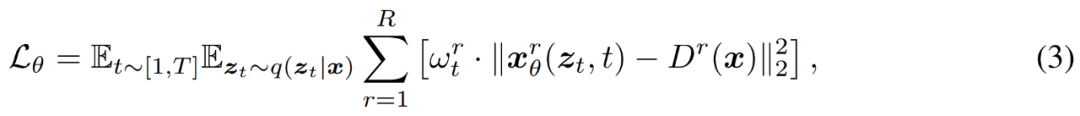
ここではプログレッシブ トレーニングが使用されます。研究者らは、上記の式 (3) に従って MDM をエンドツーエンドで直接トレーニングし、元のベースライン方法よりも優れた収束を実証しました。彼らは、GAN 論文で提案されているものと同様のシンプルなプログレッシブ トレーニング方法を使用すると、高解像度モデルのトレーニングが大幅に高速化されることを発見しました。 このトレーニング方法では、コストのかかる高解像度トレーニングを最初から回避し、全体的な収束を加速します。それだけでなく、混合解像度トレーニングも組み込まれており、異なる最終解像度を持つサンプルを単一のバッチで同時にトレーニングします。
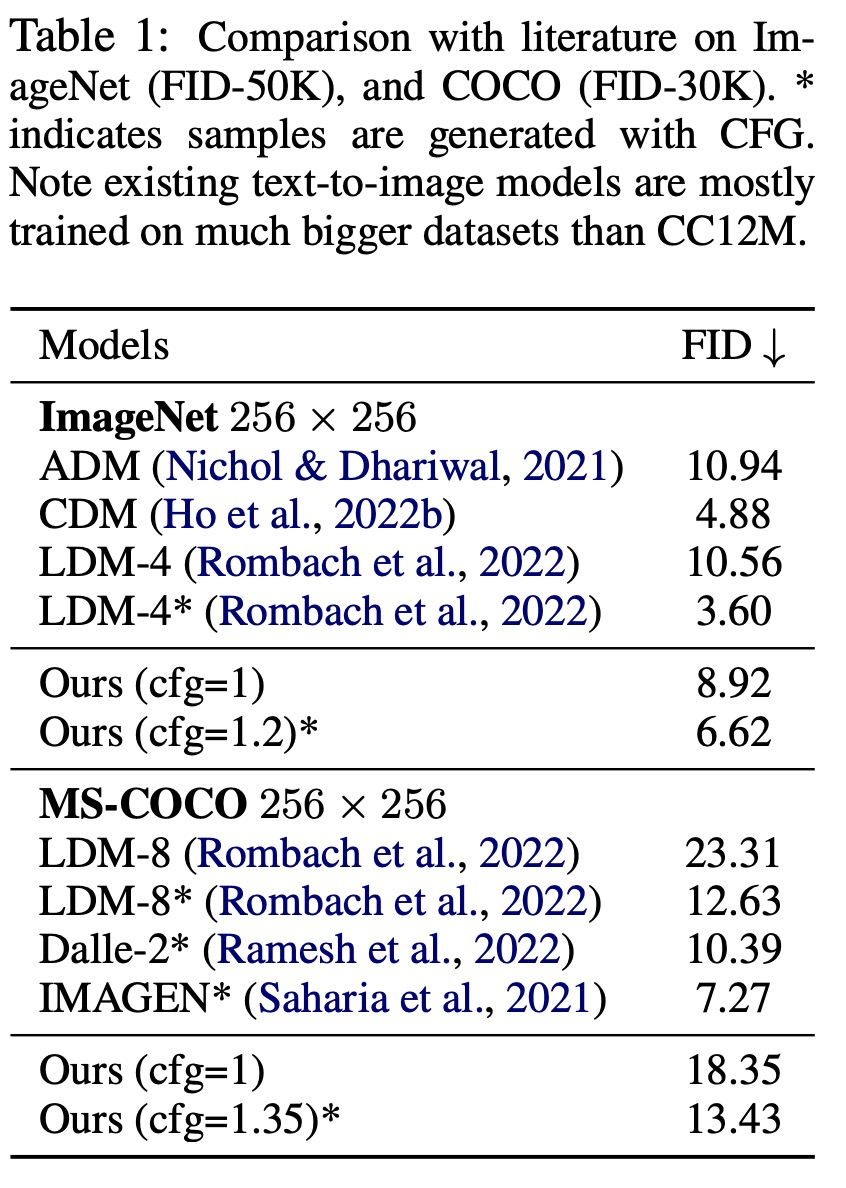
##MDM は一般的なテクノロジであり、圧縮に関する問題を徐々に解決することができます。入力寸法。 MDM とベースライン アプローチの比較を以下の図 4 に示します。 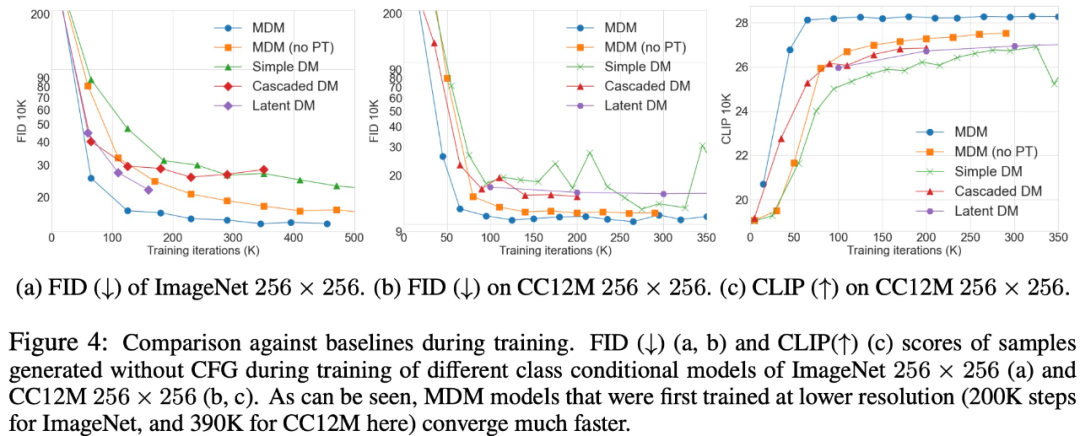 ImageNet (FID-50K) と COCO (FID-30K) の比較結果を表 1 に示します。
ImageNet (FID-50K) と COCO (FID-30K) の比較結果を表 1 に示します。
 以下の図 5、6、および 7 は、画像生成 (図 5)、テキストから画像 (図 6)、およびテキストからビデオ (図 7) における MDM のパフォーマンスを示しています。結果。比較的小さなデータセットでトレーニングされているにもかかわらず、MDM は高解像度の画像やビデオを生成する強力なゼロショット機能を示します。
以下の図 5、6、および 7 は、画像生成 (図 5)、テキストから画像 (図 6)、およびテキストからビデオ (図 7) における MDM のパフォーマンスを示しています。結果。比較的小さなデータセットでトレーニングされているにもかかわらず、MDM は高解像度の画像やビデオを生成する強力なゼロショット機能を示します。


 興味のある読者は、論文の原文を読んで研究内容について詳しく知ることができます。 。
興味のある読者は、論文の原文を読んで研究内容について詳しく知ることができます。 。
以上がAppleの大きなVincent写真モデルが発表:ロシアのマトリョーシカのようなスプレッド、1024x1024の解像度をサポートの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

