
ホームページ >テクノロジー周辺機器 >AI >GPT4 はロボットにペンを回す方法を教えます。これを「シルクのような滑らかさ」と呼びます。
GPT4 はロボットにペンを回す方法を教えます。これを「シルクのような滑らかさ」と呼びます。

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-10-30 16:53:10816ブラウズ
最近、数学者のテレンス タオにインスピレーションを与えた GPT-4 は、チャットでペンを回す方法をロボットに教え始めました

このプロジェクトは、NVIDIA によって開発された Agent Eureka と呼ばれています、ペンシルバニア大学、カリフォルニア工科大学、テキサス大学オースティン校が共同開発しました。彼らの研究では、GPT-4 構造の力と強化学習の利点を組み合わせて、Eureka が絶妙な報酬関数を設計できるようにしました。
GPT-4 のプログラミング機能により、Eureka は強力な報酬関数設計スキルを得ることができます。これは、ほとんどのタスクにおいて、エウレカ独自の報酬体系が人間の専門家の報酬体系よりも優れていることを意味します。これにより、ペンを回す、引き出しを開ける、皿のクルミを開くなど、人間では完了するのが難しいいくつかのタスクを完了することができ、さらにはボールを投げたりキャッチしたり、ハサミを操作したりするなど、さらに複雑なタスクを完了することができます。
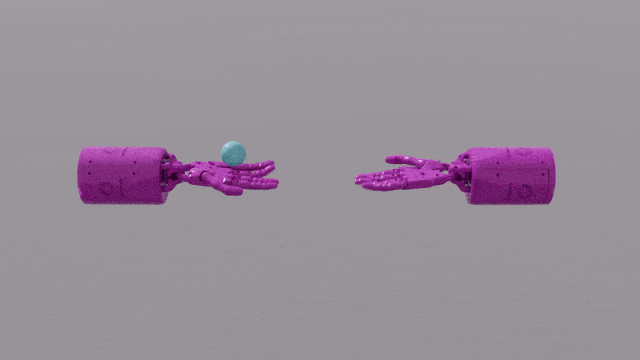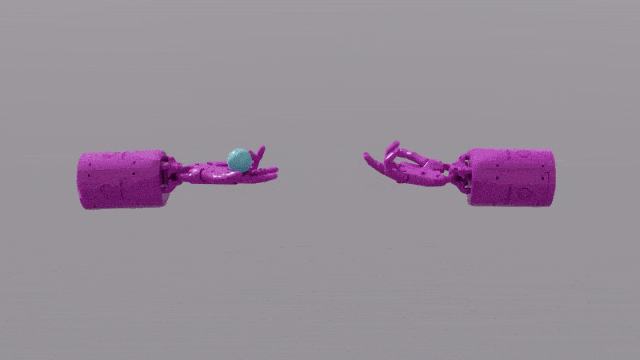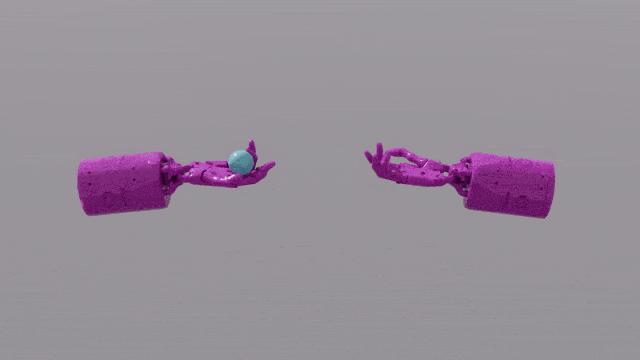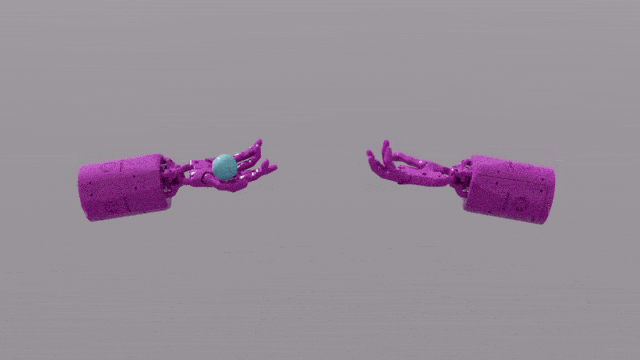 写真
写真
 写真
写真
これらは現在シミュレーション環境で行われていますが、これはすでに非常に強力です。
このプロジェクトはオープンソース化されており、プロジェクトのアドレスと論文のアドレスは記事の最後に記載されています。
論文の要点を簡単に要約します。
この論文では、大規模言語モデル (LLM) を使用して機械学習の報酬関数を設計および最適化する方法を検討します。優れた報酬関数を設計すると機械学習モデルのパフォーマンスを大幅に向上させることができるため、これは重要なトピックですが、そのような関数を設計するのは非常に困難です。
研究者らは、EUREKA と呼ばれる新しいアルゴリズムを提案しました。 EUREKA は報酬関数の生成と改善に LLM を採用しています。テストでは、EUREKA は 29 の異なる強化学習環境で人間レベルのパフォーマンスを達成し、タスクの 83% で人間の専門家によって設計された報酬関数を上回りました。
EUREKA は、これまで到達できなかったタスクのいくつかを解決することに成功しました。複雑な操作タスクは、人為的に設計された報酬関数によって解決されました。 、ペンを素早く回すための「シャドウハンド」の手の操作をシミュレートするなど、
#さらに、EUREKA は、より効果的な、人間の期待とより一致した報酬関数を生成できるまったく新しい方法を提供します。 EUREKA の動作方法は、次の 3 つの主要なステップで構成されます。コンテキストとしての環境: EUREKA は、環境のソース コードをコンテキストとして使用して、実行可能な報酬関数 2 を生成します。進化的探索: EUREKA は進化的探索を通じて報酬関数を継続的に提案および改善します 3. 報酬反映: EUREKA はポリシー トレーニングからの統計データに基づいて報酬の質のテキスト要約を生成し、それによって報酬関数を自動的かつ的を絞って改善します。 3. 報酬の反映: EUREKA は、ポリシー トレーニングからの統計データに基づいて報酬の質のテキスト要約を生成し、報酬関数を自動的かつ的を絞って改善します。この研究は、強化学習と報酬関数設計の分野に広範な影響を与える可能性があります。報酬関数を自動的に生成および改善する新しい効率的な方法を提供し、多くの場合、この方法のパフォーマンスは人間の専門家のパフォーマンスを超えるため、影響力があります。 プロジェクトアドレス:https://www.php.cn/link/e6b738eca0e6792ba8a9cbcba6c1881d
紙のリンク:https://www.php.cn/ link/ce128c3e8f0c0ae4b3e843dc7cbab0f7
以上がGPT4 はロボットにペンを回す方法を教えます。これを「シルクのような滑らかさ」と呼びます。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。