
ホームページ >テクノロジー周辺機器 >AI >SMPLer-X: 7 つの主要なリストを覆し、最初のヒューマン モーション キャプチャ モデルを提示します。
SMPLer-X: 7 つの主要なリストを覆し、最初のヒューマン モーション キャプチャ モデルを提示します。

- 王林転載
- 2023-10-30 16:01:08779ブラウズ
現在、人間の全身の姿勢と形状の推定 (EHPS、表情豊かな人間の姿勢と形状の推定) では研究が大きく進歩していますが、最も先進的な方法はトレーニング データ セットの制限によって依然として制限されています。
最近、南洋理工大学 S-Lab、SenseTime、東京大学上海人工知能研究所、IDEA 研究所の研究者らは、人体の姿勢と姿勢の推定を初めて提案しました。ボディ形状SMPLer-X、ミッションの大型モーションキャプチャーモデル。この調査では、さまざまなデータ ソースからの最大 450 万のインスタンスを使用してモデルをトレーニングし、7 つの主要なリストで最高のパフォーマンスを達成しました。
SMPLer-X は体の動きをキャプチャするだけでなく、出力もできます顔と手の動き、体型の推定

論文リンク: https://arxiv.org/ abs/2309.17448
プロジェクトのホームページ: https://caizhongang.github.io/projects/SMPLer-X/
豊富なデータと巨大なモデルにより、SMPLer-X は強力なパフォーマンスを示しますさまざまなテストやランキングで高い評価を獲得し、未知の環境でも優れた汎用性を備えています
データの拡張に関しては、研究者らは 32 の 3D 人体データセットの包括的な評価と分析を実施して、モデル トレーニングのリファレンス
2. モデルのスケーリングに関しては、視覚的な大きなモデルを使用して、モデル パラメーターの増加を検討します。パフォーマンスに対する量の改善効果
3. 微調整戦略により、SMPLer-X の一般的な大型モデルを専用の大型モデルに変換し、さらなるパフォーマンスの向上を実現できます。

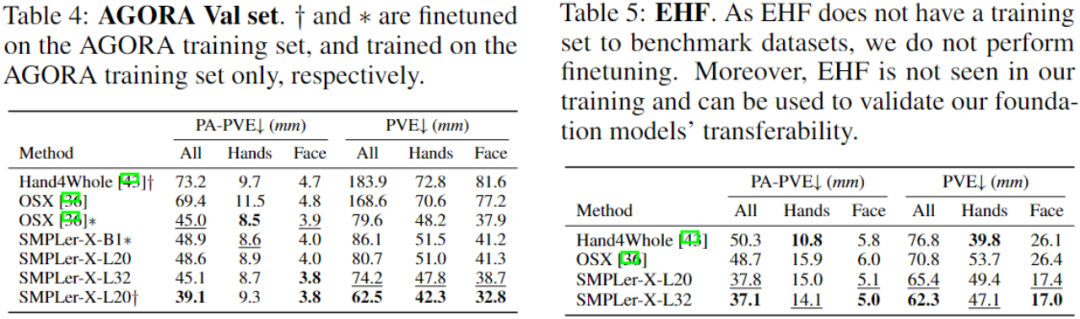
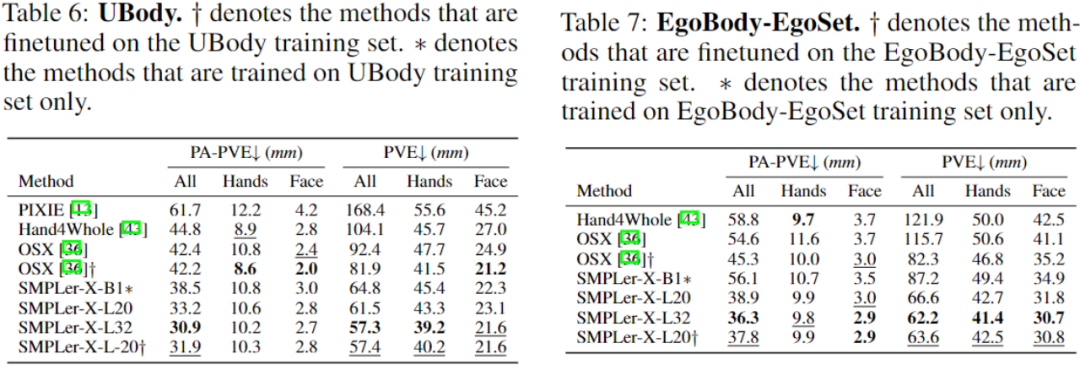
要約すると、SMPLer-X はデータ スケーリングとモデル スケーリングを調査し (図 1 を参照)、32 の学術データに対して実行しました。 450 万のインスタンスで同時に設定およびトレーニングした結果、AGORA、UBody、EgoBody、EHF を含む 7 つの主要なリストで最高のパフォーマンスを達成しました
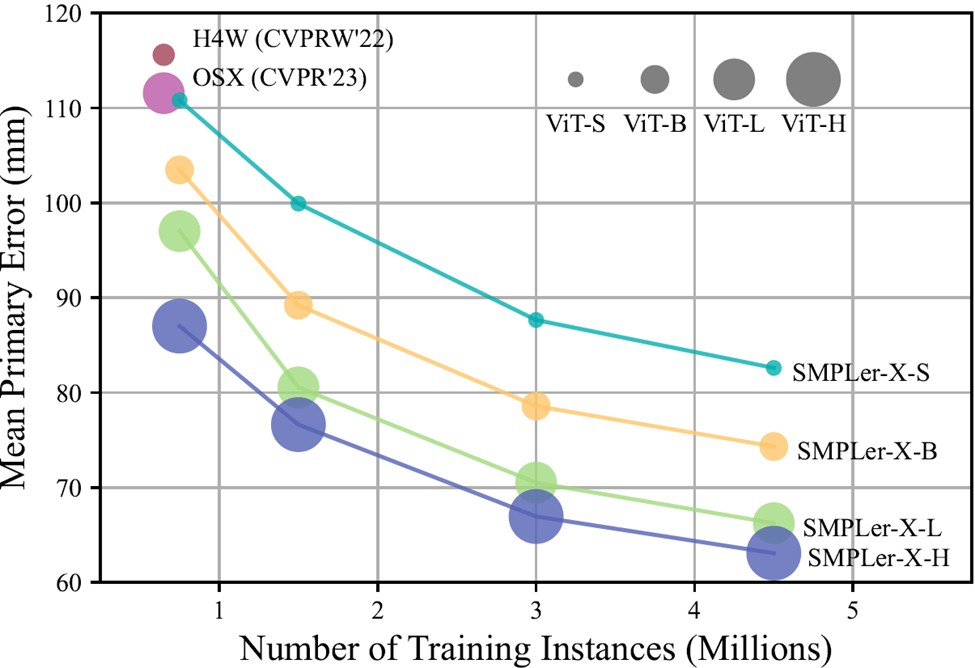
図 1データとモデル パラメーターの量を増やすことは、キー リスト (AGORA、UBody、EgoBody、3DPW、および EHF) の平均主誤差 (MPE) を減らすのに効果的です
既存の 3D 人体データセットに関する一般化研究
研究者らは 32 の学術データセットについて一般化研究を実施しました。ランキングが実行されました。各データセットのパフォーマンスを測定するために、モデルは以下を使用してトレーニングされました。そのデータセットとモデルは、AGORA、UBody、EgoBody、3DPW、および EHF の 5 つの評価データセットで評価されました。
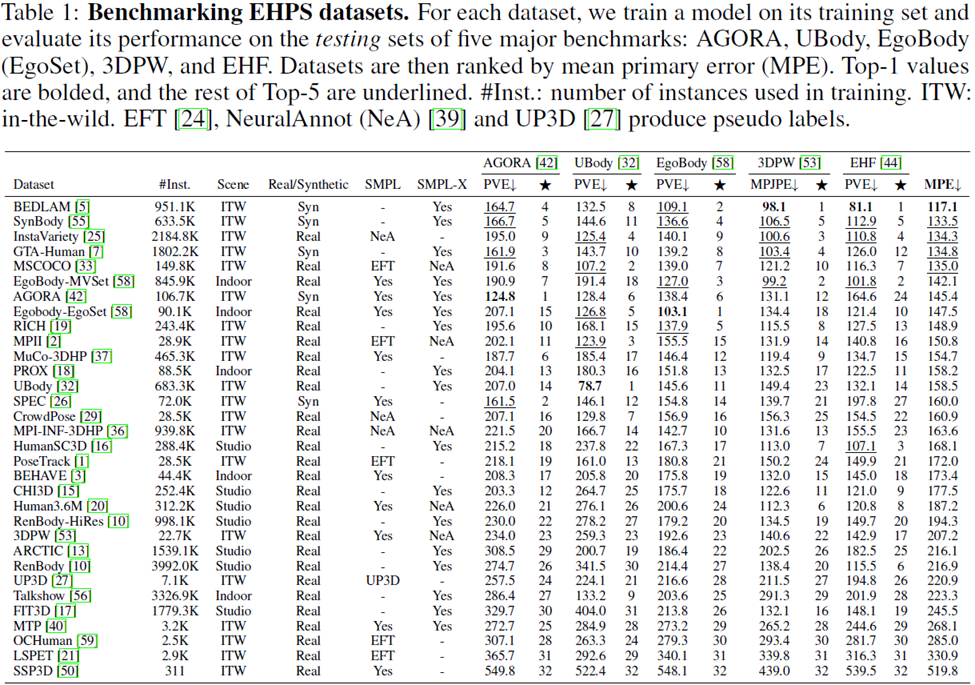
平均一次誤差 (MPE) も表で計算され、さまざまなデータセット間の簡単な比較が容易になります。
データセットの一般化の研究からのインスピレーション
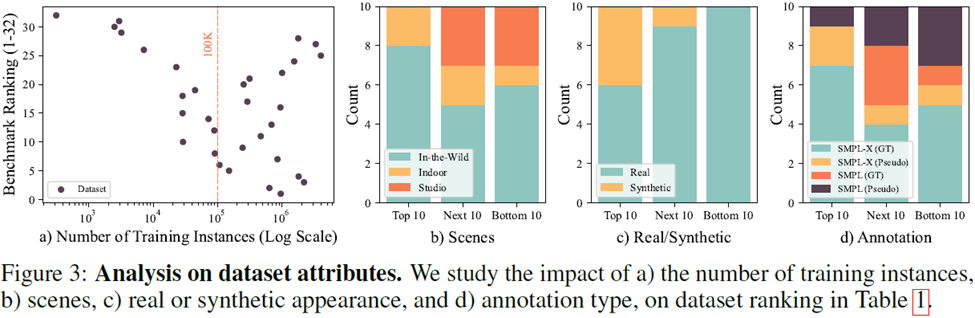
多数のデータ セットを分析すると (図 3 を参照)、次の 4 つの結論が導き出されます:
1. 単一のデータ セットのデータ量に関しては、 100,000 インスタンスのオーダー モデルのトレーニングに使用して、より高いコストパフォーマンスを実現できます;
2. データセットの収集シナリオに関しては、In-the-wild データセットは最高の効果。データが屋内でしか収集できない場合、トレーニング効果を高めるためには、単一のシーンからのデータの使用を避ける必要があります。
データセットの収集に関して、上位 3 つのうち 2 つは、データセットは生成されたデータセットです。近年、生成されたデータセットは優れたパフォーマンスを示しています
# データセットのアノテーションに関しては、擬似ラベルもトレーニングにおいて非常に重要な役割を果たしています#大規模なモーション キャプチャ モデルのトレーニングと微調整
今日の最先端の手法では、通常、トレーニングに少数のデータ セット (MSCOCO、MPII、Human3.6M など) のみが使用されます。この論文では、その他のデータセットの使用について研究します
#
よりランクの高いデータ セットが優先されることを考慮して、トレーニング セットとして 5、10、20、および 32 データ セットの 4 つの異なるデータ サイズを使用し、合計サイズは 750,000、150 万、300 万、4.5 です。
#さらに、研究者らは、一般的な大規模モデルを特定のシーンに適応させるための低コストの微調整戦略も実証しました。
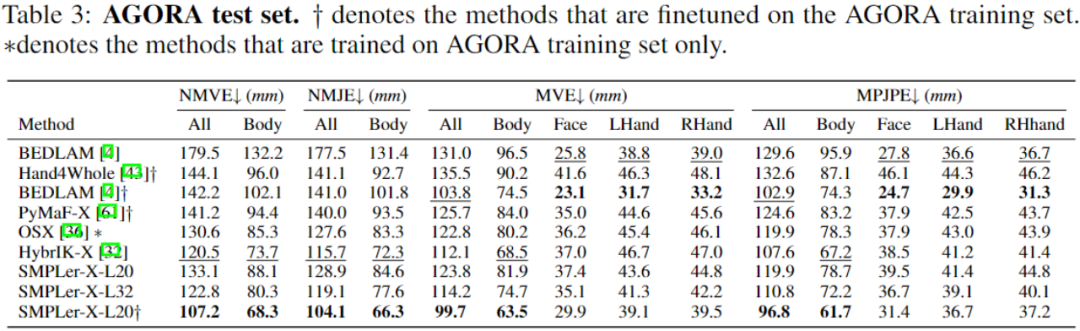
さらに、研究者らは、ARCTIC と DNA レンダリングの 2 つのテスト セットで大規模モーション キャプチャ モデルの一般化も評価しました。
研究者SMPLer-X がアルゴリズム設計を超えたインスピレーションをもたらし、強力な全身ヒューマン モーション キャプチャの大型モデルを学術コミュニティに提供できることを期待しています。
コードと事前トレーニングされたモデルは、プロジェクトのホームページでオープンソース化されています。詳細については、https://caizhongang.github.io/projects/SMPLer-X/ をご覧ください。
結果表示



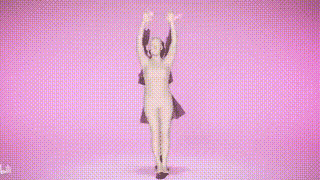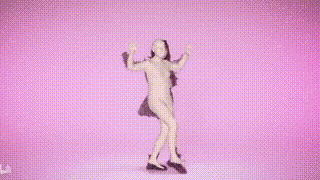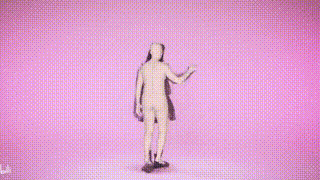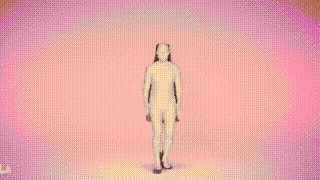



以上がSMPLer-X: 7 つの主要なリストを覆し、最初のヒューマン モーション キャプチャ モデルを提示します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。