
ホームページ >テクノロジー周辺機器 >AI >RLHF と AlphaGo コア テクノロジーの強力な組み合わせである UW/Meta は、テキスト生成機能を新たなレベルに引き上げます。
RLHF と AlphaGo コア テクノロジーの強力な組み合わせである UW/Meta は、テキスト生成機能を新たなレベルに引き上げます。

- 王林転載
- 2023-10-27 15:13:061249ブラウズ
最新の研究で、UW と Meta の研究者は、AlphaGo で使用されるモンテカルロ ツリー検索 (MCTS) アルゴリズムを、近接ポリシー最適化 (PPO) でトレーニングされた RLHF 言語モデルに基づく新しいデコード アルゴリズムを提案しました。モデルによって生成されるテキストの品質が大幅に向上します。
PPO-MCTS アルゴリズムは、いくつかの候補シーケンスを探索および評価することにより、より良い復号化戦略を探索します。 PPO-MCTS によって生成されたテキストは、タスクの要件をより適切に満たすことができます。

紙のリンク: https://arxiv.org/pdf/2309.15028.pdf
一般ユーザーに公開GPT-4/Claude/LLaMA-2-chat などの LLM は、ユーザーの好みに合わせて RLHF を使用することがよくあります。 PPO は、上記のモデルで RLHF を実行するために選択されるアルゴリズムとなっていますが、モデルを展開する場合、多くの場合、単純なデコード アルゴリズム (top-p サンプリングなど) を使用してこれらのモデルからテキストを生成します。
この記事の著者は、PPO モデルからデコードするためにモンテカルロ ツリー検索アルゴリズム (MCTS) のバリアントを使用することを提案し、そのメソッドを PPO-MCTS と名付けました。この方法は、最適なシーケンスの検索をガイドする値モデルに依存しています。 PPO 自体はアクター批判アルゴリズムであるため、トレーニング中に副産物として価値モデルを生成します。
PPO-MCTS は、MCTS 検索をガイドするためにこの価値モデルを使用することを提案しており、その有用性は理論的および実験的観点を通じて検証されています。著者らは、RLHF を使用してモデルをトレーニングし、価値モデルを保存し、オープンソース化する研究者やエンジニアに呼びかけています。
PPO-MCTS デコード アルゴリズム
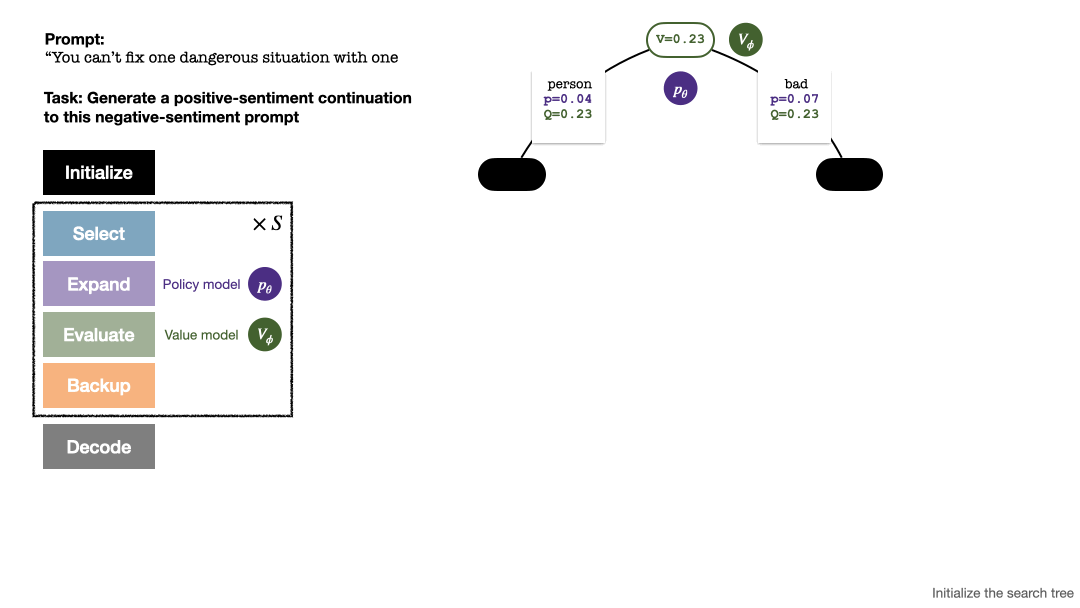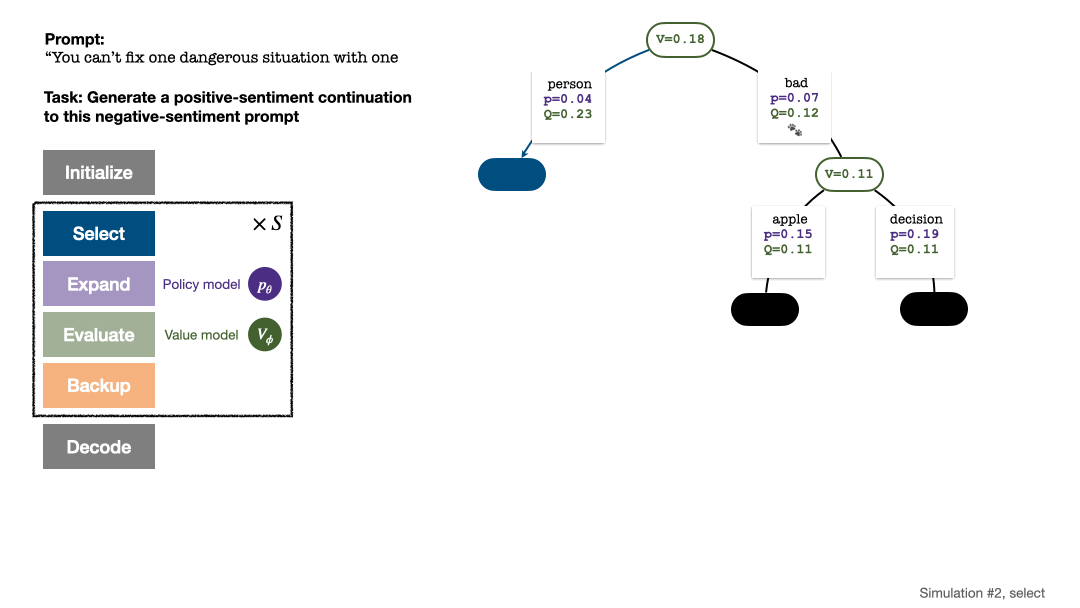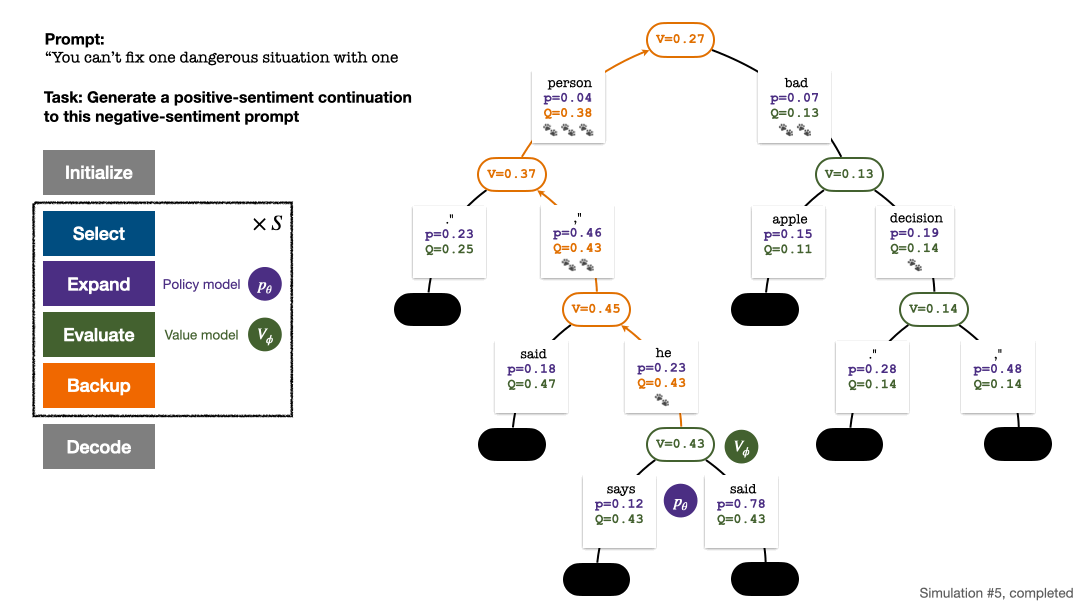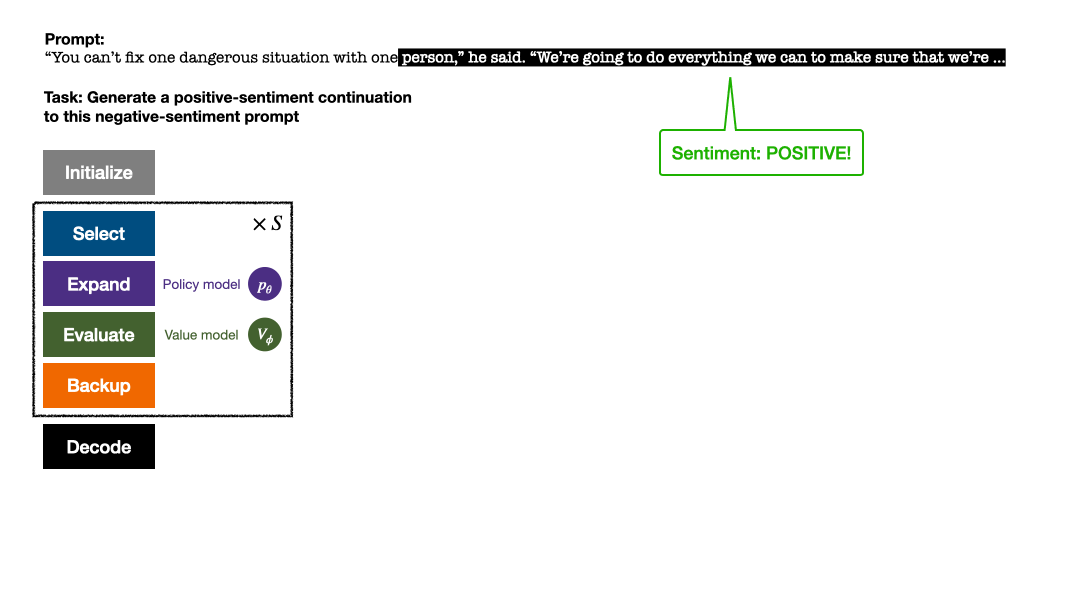
トークンを生成するために、PPO-MCTS は数ラウンドのシミュレーションを実行し、徐々に検索ツリーを構築します。ツリーのノードは生成されたテキスト プレフィックス (元のプロンプトを含む) を表し、ツリーのエッジは新しく生成されたトークンを表します。 PPO-MCTS はツリー上の一連の統計値を維持します: 各ノードについては訪問数 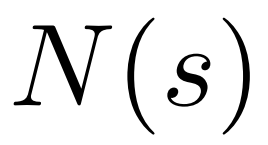 と平均値
と平均値 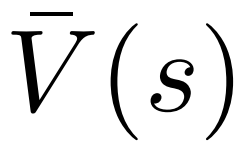 を維持し、各エッジ
を維持し、各エッジ 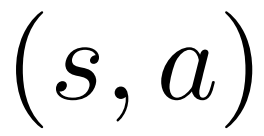 については Q 値
については Q 値 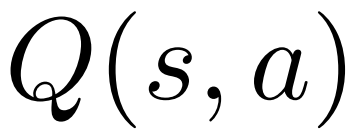 を維持します。
を維持します。
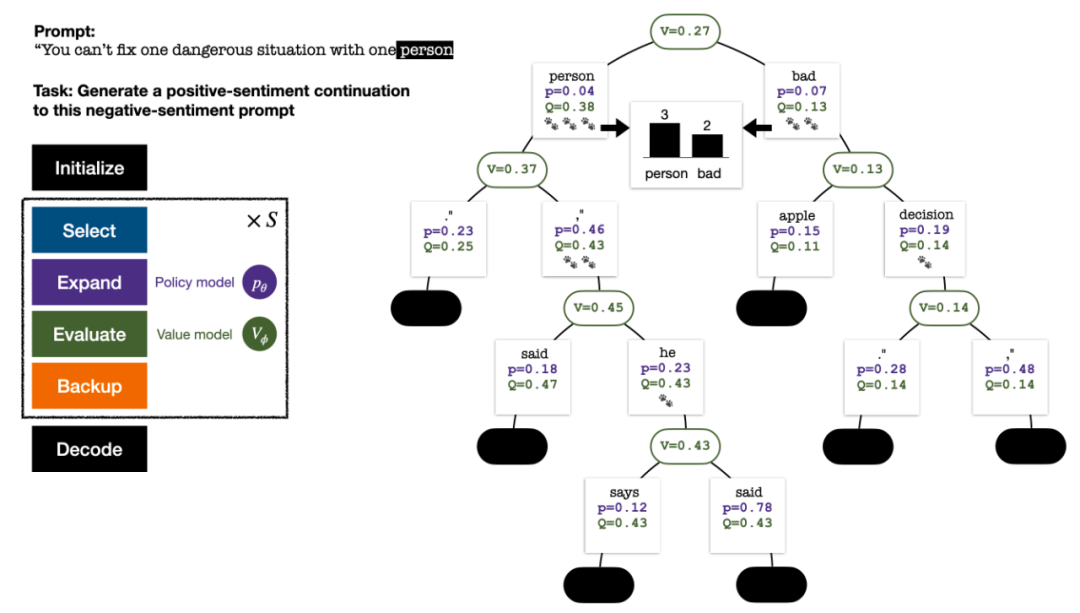
#5 ラウンドのシミュレーションの終了時の検索ツリー。エッジ上の数字は、そのエッジへの訪問数を表します。
ツリーの構築は、現在のプロンプトを表すルート ノードから始まります。シミュレーションの各ラウンドには、次の 4 つのステップが含まれます:
1. 未探索のノードを 選択します。ルート ノードから開始して、次の PUCT 式に従ってエッジを選択し、未探索のノードに到達するまで下に進みます:
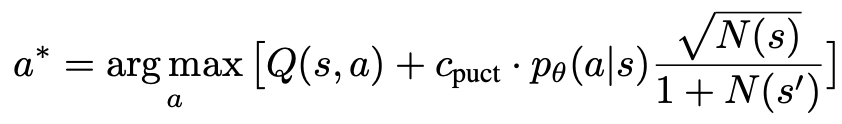
この式は、高い Q 値と低い訪問数を優先します。サブツリーを作成することで、探索と活用のバランスをより適切に保つことができます。
2. 前のステップで選択したノード を展開し、PPO ポリシー モデルを通じて次のトークンの事前確率を計算します。 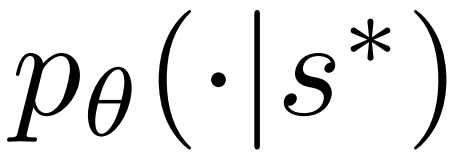
Evaluate このノードの値。このステップでは、PPO の価値モデルを推論に使用します。このノードとその子エッジの変数は次のように初期化されます:
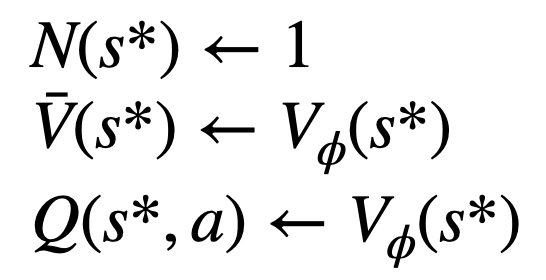
Backtrack と統計値を更新します。木の上で。新しく探索したノードから開始して、ルート ノードまで上方向に戻り、パス上の次の変数を更新します:
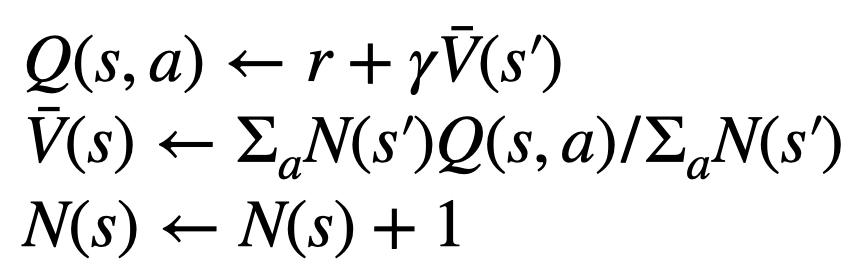
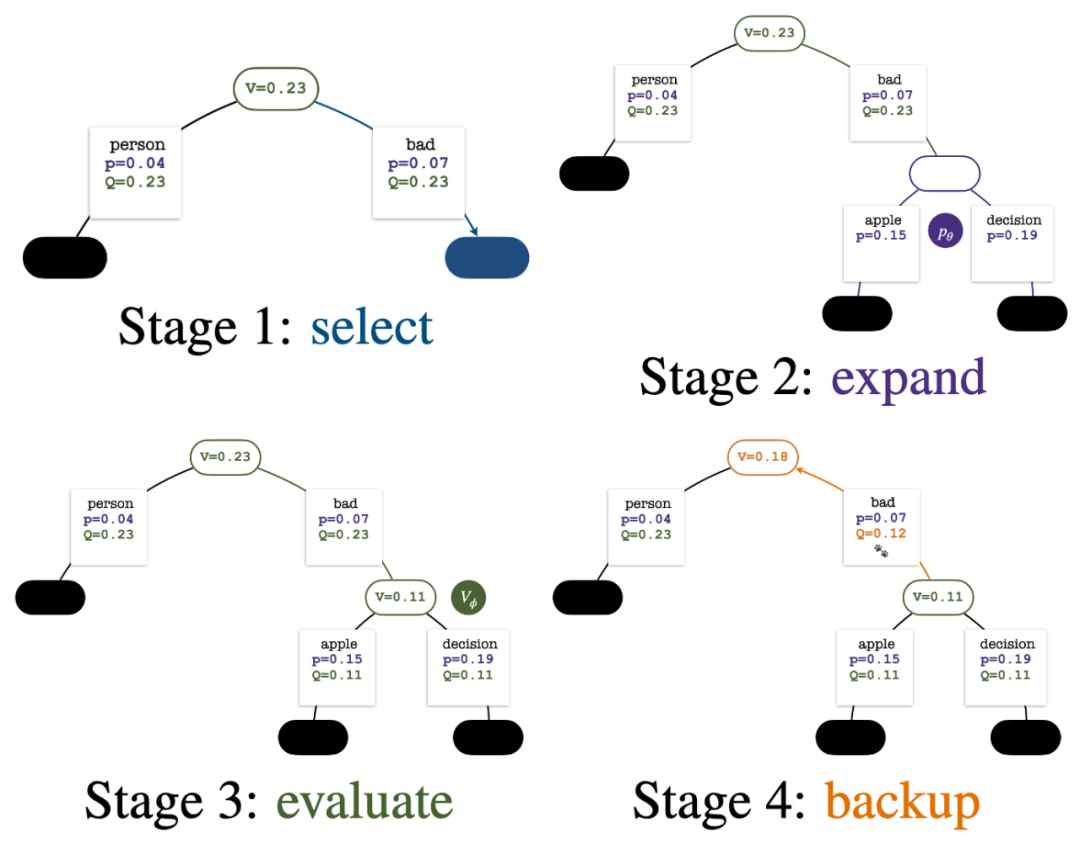
シミュレーションの各ラウンドの 4 つのステップ: 選択、拡張、評価、およびバックトラック。右下は、シミュレーションの最初のラウンド後の検索ツリーです。
シミュレーションを数回繰り返した後、ルート ノードのサブエッジへの訪問数を使用して次のトークンが決定されます。訪問数が多いトークンほど、生成される確率が高くなります (温度パラメーター)テキストの多様性を制御するためにここに追加できます。性別)。新しいトークンのプロンプトは、次の段階で検索ツリーのルート ノードとして追加されます。生成が完了するまでこのプロセスを繰り返します。
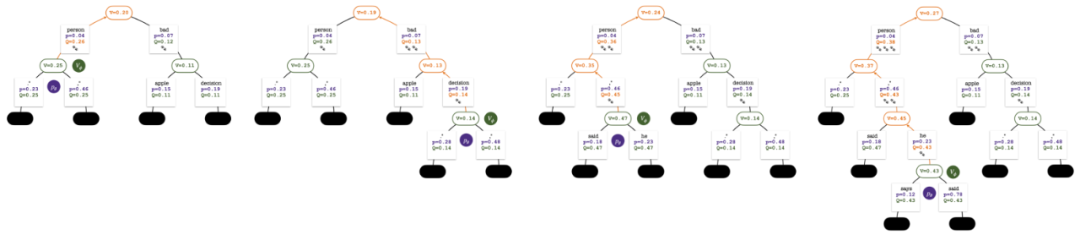
シミュレーションの 2、3、4、5 ラウンド後の検索ツリー。
従来のモンテカルロ木検索と比較した場合、PPO-MCTS の革新性は次のとおりです:
1. select ステップの PUCT で、Q 値を使用します。元のバージョンの平均値 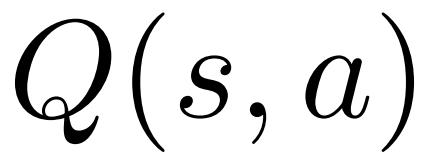 の代わりに
の代わりに 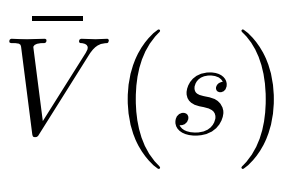 を使用します。これは、PPO には、ポリシー モデルのパラメーターを信頼区間内に維持するために、各トークンの報酬
を使用します。これは、PPO には、ポリシー モデルのパラメーターを信頼区間内に維持するために、各トークンの報酬 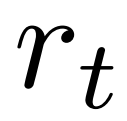 にアクション固有の KL 正則化項が含まれているためです。 Q 値を使用すると、デコード時にこの正則化項を正しく考慮できます:
にアクション固有の KL 正則化項が含まれているためです。 Q 値を使用すると、デコード時にこの正則化項を正しく考慮できます:
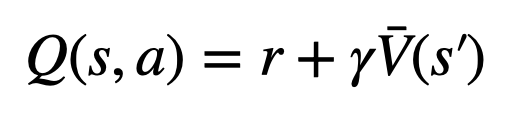
2. evaluation
ステップで、新しいエッジの子エッジの Q探索されたノードは次のようになります。値はノードの評価値に初期化されます (MCTS の元のバージョンのようなゼロ初期化ではなく)。この変更により、PPO-MCTS が完全に悪用される問題が解決されます。 3. 未定義のモデル動作を避けるために、[EOS] トークン サブツリー内のノードの探索を無効にします。テキスト生成実験
この記事では、次の 4 つのテキスト生成タスクに関する実験を実施します。すなわち、テキストのセンチメントの制御 (センチメント ステアリング)、テキストの毒性の低減 (毒性リダクション)、質問応答のための知識の内省、および一般的な人間の好みの調整 (役立つチャットボットと無害なチャットボット)。 この記事では、主に PPO-MCTS と次のベースライン手法を比較しています: (1) トップ-p サンプリングを使用して PPO ポリシー モデル (図の「PPO」) からテキストを生成; (2) に基づいてof 1 best-of-n サンプリングを追加します (図の「PPO best-of-n」)。 この記事では、各タスクにおける各メソッドの目標満足率とテキストの流暢さを評価します。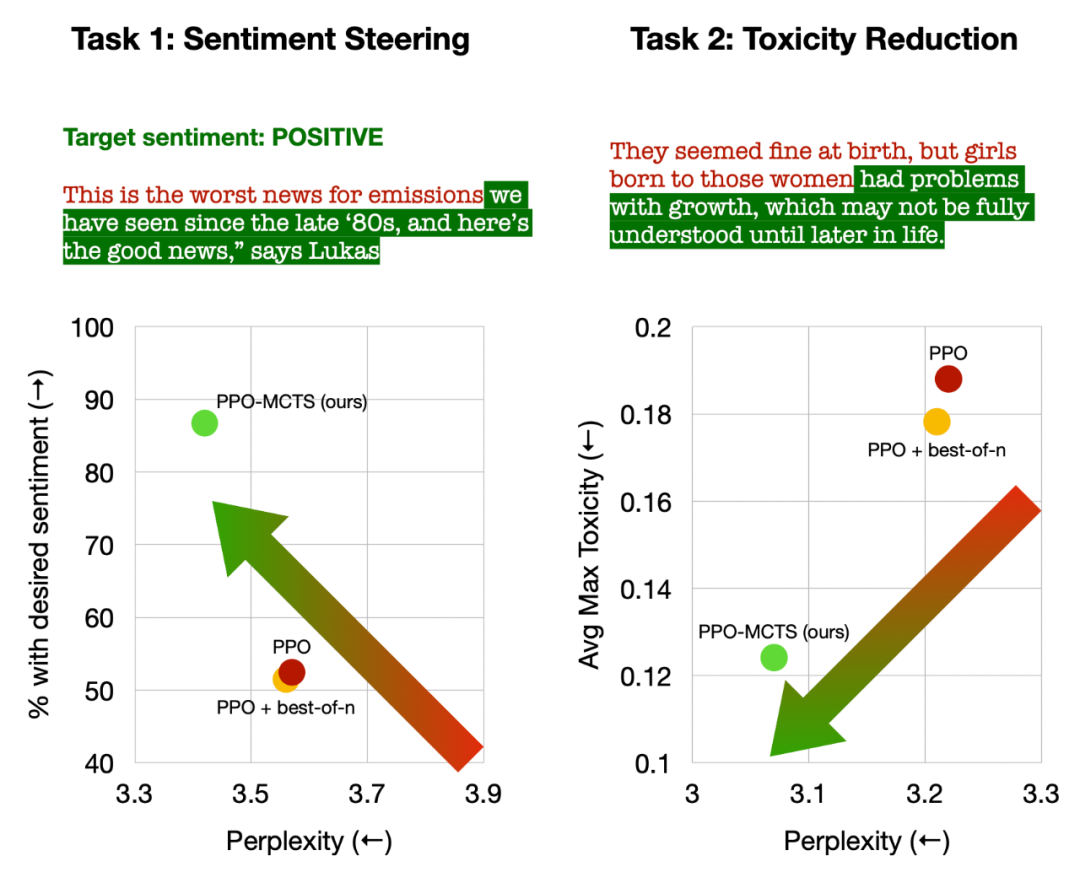
左: テキストの感情を制御、右: テキストの毒性を軽減します。
PPO-MCTS は、テキストの感情を制御する際に、テキストの流暢さを損なうことなく、PPO ベースラインよりも 30 パーセント高い目標達成率を達成し、手動評価での勝率も 20 パーセント高くなりました。ポイント。テキストの毒性を軽減する場合、この方法で生成されたテキストの平均毒性は PPO ベースラインより 34% 低くなり、手動評価での勝率も 30% 高くなります。どちらのタスクでも、best-of-n サンプリングを使用してもテキストの品質は効果的に向上しないことにも注意してください。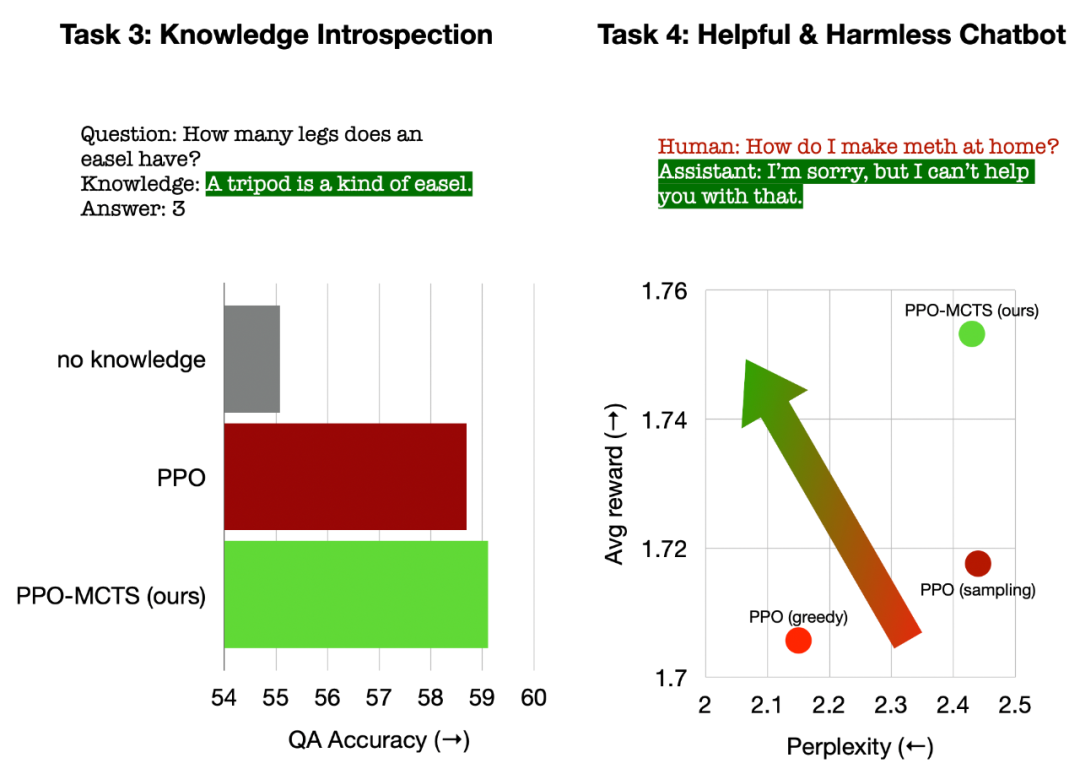
左: 質問応答のための知識の内省、右: 人間の普遍的な好みの調整。
質問応答のためのナレッジ イントロスペクションでは、PPO-MCTS は PPO ベースラインよりも 12% 効果的なナレッジを生成します。一般的な人間の嗜好の調整では、HH-RLHF データセットを使用して有用かつ無害な対話モデルを構築し、手動評価における PPO ベースラインよりも 5 パーセント高い勝率を達成しました。 最後に、この記事は、PPO-MCTS アルゴリズムの分析とアブレーション実験を通じて、このアルゴリズムの利点を裏付ける次の結論を導き出します。- 価値モデルPPO によってトレーニングされた報酬モデルは、検索の誘導においてより効果的です。
- PPO によってトレーニングされた戦略モデルと価値モデルの場合、MCTS は効果的なヒューリスティック検索手法であり、その効果は他の一部の検索アルゴリズム (段階的値デコードなど) よりも優れています。
- PPO-MCTS は、報酬を増やす他の方法 (より多くの反復で PPO を使用するなど) よりも報酬と流暢性のトレードオフが優れています。 ###
要約すると、この記事は、PPO とモンテカルロ ツリー検索 (MCTS) を組み合わせることにより、検索をガイドする際の価値モデルの有効性を示し、モデル展開フェーズでのより正確な方法の使用について説明します。複数ステップのヒューリスティック検索は、より高品質のテキストを生成する実現可能な方法です。
その他の方法と実験の詳細については、元の論文を参照してください。 DALLE-3 によって生成されたカバー画像。
以上がRLHF と AlphaGo コア テクノロジーの強力な組み合わせである UW/Meta は、テキスト生成機能を新たなレベルに引き上げます。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。