

ゲーム向けの高精度かつ低コストの 3D 顔再構成ソリューション、Tencent AI Lab ICCV 2023 論文の解釈

3D 顔再構成は、ゲーム映画やテレビ制作、デジタル ピープル、AR/VR、顔認識と編集などの分野で広く使用されている主要なテクノロジーであり、その目標は、1 つまたは複数の画像から高品質の画像を取得することです。 3D顔モデル。スタジオでの複雑な撮影システムの助けを借りて、現在業界で成熟したソリューションは、本物の人間に匹敵する毛穴レベルの精度で再構成効果を達成できます[2]。しかし、それらの製造コストは高く、サイクルタイムは長く、これらは通常、S レベルの映画、テレビ、またはゲーム プロジェクトでのみ使用されます。
近年、低コストの顔再構成技術に基づくインタラクティブなゲームプレイ(ゲームキャラクターの顔つまみゲームプレイ、AR/VR仮想画像生成など)が市場に歓迎されています。携帯電話で撮影した1枚または複数枚の写真など、毎日入手できる写真を入力するだけで、すぐに3Dモデルを取得できます。しかし、既存の手法では画像品質が制御できず、再構成結果の精度が低く、顔の細部を表現することができません[3-4]。忠実度の高い 3D 顔を低コストで取得する方法は依然として未解決の問題です。
顔再構成の最初のステップは、顔の表情方法を定義することです。しかし、既存の主流の顔パラメータ化モデルでは表現能力が限られています。多視点画像などのより多くの制約情報があっても、再構成精度は難しいです。そこで、Tencent AI Lab は、顔事前分布を使用し、ガウス混合モデルを使用して顔マスキングを表現するパラメトリック顔モデルとして、改良された Adaptive Skinning Model (以下、ASM) を提案しました。自動的に解決できます。
テストにより、ASMメソッドはトレーニングを必要とせずに少数のパラメータのみを使用するため、顔の表現能力と多視点顔再構成の精度が大幅に向上し、SOTAレベルを革新することがわかりました# ##。当該論文がICCV-2023に採択されましたので、以下に論文の詳細を説明します。
論文タイトル: ASM: 高品質 3D 顔モデリングのための適応スキニング モデル

研究課題: 低コスト、高精度の 3D 顔再構成問題
2D 画像からより有益な 3D 画像を取得するモデルは次のとおりです。無限の解を持つ過小決定問題。これを解決可能にするために、研究者は再構成に顔事前分布を導入します。これにより、解決の難易度が軽減され、より少ないパラメータで顔の 3D 形状が表現されます。つまり、パラメトリック顔モデルです。現在のパラメトリック顔モデルのほとんどは、1999 年に Blanz と Vetter によって最初に提案された 3D Morphable Model (3DMM) とその改良版に基づいています [5]。この記事では、複数の異なる顔の線形または非線形の組み合わせによって顔が得られると仮定し、数百もの実際の顔の高精度 3D モデルを収集して顔ベース ライブラリを構築し、パラメータ化された顔を組み合わせて新しい特徴を表現します. 顔モデル。その後の研究では、より多様な素顔モデルを収集し [6、7]、次元削減方法を改善することで 3DMM を最適化しました [8、9]。 しかし、3DMMの顔型モデルは堅牢性は高いものの、表現力が不十分です。 3DMMは、入力画像にブレや遮蔽がある場合でも平均的な精度で安定して顔モデルを生成できますが、複数の高画質画像を入力とした場合、3DMMの表現能力には限界があり、より多くの入力情報を活用できないため、再構成精度に限界が生じます。この限界は 2 つの側面から生じています。第一に、手法自体の限界です。第二に、この手法は顔モデル データの収集に依存しています。データ取得コストが高いだけでなく、次の理由により実用化が困難です。顔データの機密性を重視し、広範に再利用します。ASM 手法: スケルトンスキンモデルの再設計
既存の 3DMM 顔モデルの表現力不足の問題を解決するために、この記事では「スケルトン」を紹介します。 -Skinned Model」をベースラインの表情として使用します。スケルトンスキンモデルは、ゲームやアニメーションの制作過程でゲームキャラクターの顔の形状や表情を表現するために使用される一般的な顔モデリング手法です。仮想ボーン ポイントを介して人間の顔のメッシュ頂点に接続されます。スキン ウェイトは、メッシュ頂点上のボーンのインフルエンス ウェイトを決定します。使用する場合、ボーンの動きを制御するだけで、間接的にボーンの動きを制御できます。メッシュの頂点。 通常、スケルトン - スキン モデルでは、アニメーターが正確なボーンの配置とスキン ウェイトの描画を実行する必要があり、これには制作閾値が高く、制作サイクルが長いという特徴があります。しかし、実際の人間の顔は、人によって骨や筋肉の形状が大きく異なり、固定的なスケルトンスキニングシステムで現実のさまざまな顔の形状を表現するのは難しいため、この記事では既存のスケルトンスキニングを使用します。システム さらなる設計に基づいて、ガウス混合スキニング重み (GMM Skinning Weights) と動的骨結合システム (Dynamic Bone Binding)に基づいて、骨をさらに改善する適応型骨スキニング モデル ASM が提案されます。スキニング 表現力と柔軟性により、ターゲットの顔ごとに固有のスケルトン - スキン モデルを適応的に生成し、より豊かな顔の詳細を表現します。 ASM では、さまざまな顔をモデリングするスケルトン - スキン モデルの表現力を向上させるために、スケルトン - スキン モデルのモデリング方法を新たに設計しました。
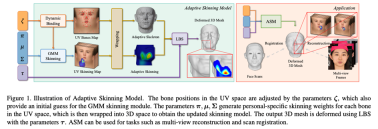
#スキニング (LBS) アルゴリズムは、ボーンの動き (回転、平行移動、スケーリング) を制御することにより、メッシュ頂点の変形を制御します。従来のボーン スキニングは、スキン ウェイト マトリックスとボーン バインディングの 2 つの部分で構成されており、ASM はこれら 2 つの部分を個別にパラメータ設定して、適応性のあるボーン スキニング モデルを実現します。次に、スキンウェイトマトリックスとボーンバインディングのパラメトリックモデリング手法をそれぞれ紹介します。
式 1: 従来のスケルトンスキンモデルの LBS 式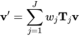
## FORMULA 2:ASMのLBSフォーミュラ
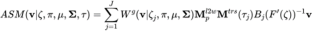
####The Skin Weight行列は mxn 次元の行列で、m はボーンの数、n はメッシュ上の頂点の数です。この行列は、各メッシュの頂点上の各ボーンの影響係数を保存するために使用されます。一般に、スキン ウェイト マトリックスは非常にスパースです。たとえば、Unity では、各メッシュ頂点は最大 4 つのボーンによってのみ影響を受けます。これらの 4 つのボーンを除き、頂点上の他のボーンの影響係数は 0 です。 。従来のボーンスキン モデルでは、スキン ウェイトはアニメーターによって描画され、スキン ウェイトが一度取得されると、使用時に変更されなくなります。近年、大量のデータとニューラル ネットワークの学習を組み合わせてスキニング ウェイトを自動的に生成する研究 [1] が試みられていますが、このような解決策には 2 つの問題があります。 3D 顔またはスキニングの場合、ウェイト データを取得するのはさらに困難です。第 2 に、ニューラル ネットワークを使用してスキン ウェイトをモデル化すると、パラメータの冗長性が大幅に高まります。
訓練なしで少ないパラメータで顔全体の皮膚重みを完全に表現できる皮膚重みモデリング手法はありますか?
一般的なスキニング ウェイトを観察すると、次の特性がわかります: 1. スキニング ウェイトは局所的に滑らかです; 2. メッシュ頂点が現在のボーン位置から離れるほど、対応するスキニング係数は次のようになります。通常はより小さいです。 ; そして、この特性は混合ガウス モデル (GMM) と非常に一致しています。したがって、この記事では、頂点とボーンの間の特定の距離関数に基づいてスキニング ウェイト マトリックスをガウス混合関数としてモデル化するガウス混合スキニング ウェイト (GMM スキニング ウェイト) を提案します。これにより、一連の GMM 係数を使用してスキニングを表現できるようになります。特定のボーンの重みが分散されます。スキン ウェイトのパラメータをさらに圧縮するために、顔のメッシュ全体を 3 次元空間から UV 空間に転送します。これにより、2 次元 GMM を使用し、頂点から UV 距離を使用するだけで済みます。特定の頂点の現在のボーンのマスキングを計算するためのボーン、スキン ウェイト係数。ダイナミックボーンバインディング
スキンウェイトのパラメトリックモデリングにより、少数のパラメータでスキンウェイトマトリックスを表現できるだけでなく、そこで、本記事では動的にボーンを結合する方法(Dynamic Bone Binding)を提案します。本記事ではスキンウェイトと同様にボーンの結合位置をUV空間上の座標点としてモデリングしており、UV空間内で任意に移動することができます。フェイス メッシュの頂点の場合、事前定義された UV マッピング関係を通じて、頂点を UV 空間内の固定座標にマッピングすることができます。ただし、ボーンは UV 空間で事前定義されていないため、そのためにはバインドされたボーンを 3 次元空間から UV 空間に転送する必要があります。この記事のこのステップは、ボーンと周囲の頂点の座標を補間することで実装されており、計算された補間係数を頂点の UV 座標に適用して、ボーンの UV 座標を取得します。逆も同様で、ボーン座標を UV 空間から 3 次元空間に転送する必要がある場合、現在のボーンの UV 座標と隣接する頂点の UV 座標の間の補間係数も計算し、 3次元空間上の同一頂点への補間係数を設定し、3次元座標上で、対応するボーンの3次元空間座標を補間することができます。このモデリング手法により、ボーンのバインディング位置とスキン ウェイト係数を UV 空間内の一連の係数に統一します。 ASM を使用する場合、フェイス メッシュ頂点の変形を、UV 空間でのボーン結合位置のオフセット係数、UV 空間でのガウス混合スキニング係数、およびボーンのモーション係数の組み合わせに変換します。スケルトンスキンモデルの表現力が向上し、より豊かな顔の詳細を生成できるようになります。

#sotAレベルに達する
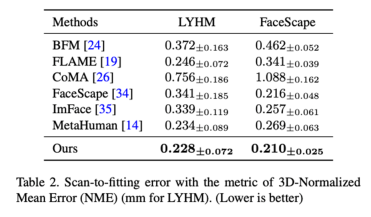
パラメトリック顔モデルの登録を使用します。高精度の顔スキャン モデル (登録) の手法は、PCA 手法 (BFM [6]、FLAME [7]) に基づく従来の 3DMM と ASM を組み合わせたものです。 ]、FaceScape [10])、ニューラルネットワーク次元削減法に基づく 3DMM(CoMA [8]、ImFace [9])、および業界をリードする骨スキンモデル(MetaHuman)を比較しました。結果は、ASM の発現能力が LYHM と FaceScape の両方のデータセットで SOTA レベルに達していることを示しています。
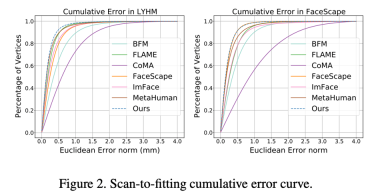
 ##図 2: LYHM と FaceScape での登録精度の誤差分布
##図 2: LYHM と FaceScape での登録精度の誤差分布
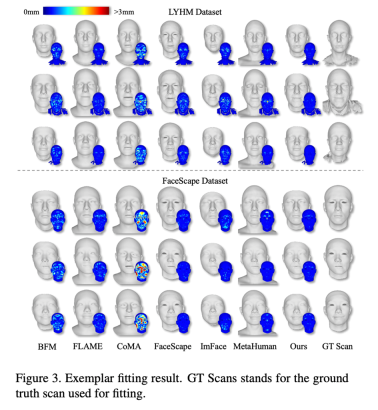
#図 3: LYHM 視覚化の結果とFaceScape での登録のエラー ヒート マップ
マルチビュー顔再構成におけるアプリケーション
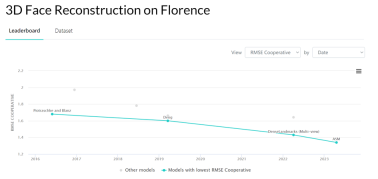 Florence MICC のデータを使用しました。このセットはパフォーマンスをテストしました多視点顔再構成タスクにおける ASM の再構成精度と、Coop (屋内近距離カメラ、表情のない人々) テスト セットでの再構成精度は SOTA レベルに達しました。
Florence MICC のデータを使用しました。このセットはパフォーマンスをテストしました多視点顔再構成タスクにおける ASM の再構成精度と、Coop (屋内近距離カメラ、表情のない人々) テスト セットでの再構成精度は SOTA レベルに達しました。
###図4:フィレンツェMICCデータセットの3Dフェイス再構築の結果

多視点再構成タスクにおける再構成結果の写真枚数の割合をFaceScapeデータセットでテストした結果、写真枚数が5枚程度の場合、ASMは他の表情手法と比較して最高の再構成精度を達成できることがわかりました。 。

##この研究は解決に向けて重要な一歩を踏み出しました低コストで忠実度の高い人間の顔を取得するという業界の課題。私たちが提案する新しいパラメトリック顔モデルは、表情能力を大幅に向上させ、多視点顔再構成の精度の上限を新たなレベルに引き上げます。この手法は、ゲーム制作における3Dキャラクターモデリング、顔の自動挟み込みゲームプレイ、AR/VRにおけるアバター生成など、さまざまな分野で活用可能です。 顔の表情能力が大幅に向上した後、再構成結果の精度をさらに向上させるために、多視点画像からより強力な一貫性制約を構築する方法が、現在の顔再構成分野における新たなボトルネックおよび新たな課題となっています。これは私たちの今後の研究の方向性でもあります。 参考文献 [1] Noranart Vesdapunt、Mitch Rundle、HsiangTao Wu、Baoyuan Wang. Jnr: コンパクトな 3D フェイスのためのジョイントベースのニューラル リグ表現In Computer Vision – ECCV 2020: 第 16 回欧州会議、英国グラスゴー、2020 年 8 月 23 ~ 28 日、議事録、パート XVIII 16、389 ~ 405 ページ。Springer、2020. [2] Thabo Beeler、Bernd Bickel、Paul Beardsley、Bob Sumner、Markus Gross. 顔のジオメトリの高品質なシングルショット キャプチャ. ACM SIGGRAPH 2010 論文、1 ~ 9 ページ。2010. #[3] Yu Deng、Jiaolong Yang、Sicheng Xu、Dong Chen、Yunde Jia、Xin Tong. 弱教師学習による正確な 3D 顔再構成: 単一画像から画像セットへ. IEEE 論文集コンピューター ビジョンとパターン認識ワークショップに関する /CVF カンファレンス、0 ~ 0 ページ、2019. [4] Yao Feng、Haiwen Feng、Michael J Black、Timo Bolkart。アニメーションの学習野生の画像からの詳細な 3D 顔モデル。ACM Transactions on Graphics (ToG)、40 (4):1–13、2021. [5] Volker Blanz および Thomas Vetter. 3D 顔の合成のためのモーファブル モデル. コンピュータ グラフィックスとインタラクティブ技術に関する第 26 回年次会議議事録、187 ~ 194 ページ、1999. [6] Pascal Paysan 、Reinhard Knothe、Brian Amberg、Sami Romdhani、および Thomas Vetter. ポーズと照明の不変顔認識のための 3D 顔モデル. 2009 年、高度なビデオおよび信号ベースの監視に関する第 6 回 IEEE 国際会議、296 ~ 301 ページ. Ieee、2009. [8] Anurag Ranjan、Timo Bolkart、soubhik Sanyal、Michael J Black. 畳み込みメッシュ オートエンコーダーを使用した 3D フェイスの生成。コンピューター ビジョンに関する欧州会議 (ECCV)、704 ~ 720 ページ、2018 年. [9] Mingwu Zheng、Hongyu Yang、Di Huang、Liming Chen. Imface: A nonlinear 3d暗黙的なニューラル表現を備えたモーファブル顔モデルコンピュータ ビジョンとパターン認識に関する IEEE/CVF 会議議事録、20343 ~ 20352 ページ、2022. [10] Haotian Yang、Hao Zhu 、Yanru Wang、Mingkai Huang、Qiu Shen、Ruigang Yang、および Xun Cao. Facescape: 大規模で高品質の 3D 顔データセットと詳細なリグ可能な 3D 顔予測. コンピュータ ビジョンとパターン認識に関する IEEE/CVF 会議の議事録 ,ページ 601–610、2020.
以上がゲーム向けの高精度かつ低コストの 3D 顔再構成ソリューション、Tencent AI Lab ICCV 2023 論文の解釈の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 迅速なエンジニアリングにおける思考のグラフは何ですかApr 13, 2025 am 11:53 AM
迅速なエンジニアリングにおける思考のグラフは何ですかApr 13, 2025 am 11:53 AM導入 迅速なエンジニアリングでは、「思考のグラフ」とは、グラフ理論を使用してAIの推論プロセスを構造化および導く新しいアプローチを指します。しばしば線形sを含む従来の方法とは異なります
 Genaiエージェントとの電子メールマーケティングを組織に最適化しますApr 13, 2025 am 11:44 AM
Genaiエージェントとの電子メールマーケティングを組織に最適化しますApr 13, 2025 am 11:44 AM導入 おめでとう!あなたは成功したビジネスを運営しています。ウェブページ、ソーシャルメディアキャンペーン、ウェビナー、会議、無料リソース、その他のソースを通じて、毎日5000の電子メールIDを収集します。次の明白なステップはです
 Apache Pinotによるリアルタイムアプリのパフォーマンス監視Apr 13, 2025 am 11:40 AM
Apache Pinotによるリアルタイムアプリのパフォーマンス監視Apr 13, 2025 am 11:40 AM導入 今日のペースの速いソフトウェア開発環境では、最適なアプリケーションパフォーマンスが重要です。応答時間、エラーレート、リソース利用などのリアルタイムメトリックを監視することで、メインに役立ちます
 ChatGptは10億人のユーザーにヒットしますか? 「わずか数週間で2倍になりました」とOpenai CEOは言いますApr 13, 2025 am 11:23 AM
ChatGptは10億人のユーザーにヒットしますか? 「わずか数週間で2倍になりました」とOpenai CEOは言いますApr 13, 2025 am 11:23 AM「ユーザーは何人いますか?」彼は突き出した。 「私たちが最後に言ったのは毎週5億人のアクティブであり、非常に急速に成長していると思います」とアルトマンは答えました。 「わずか数週間で2倍になったと言った」とアンダーソンは続けた。 「私はそのprivと言いました
 PIXTRAL -12B:Mistral AI'の最初のマルチモーダルモデル-Analytics VidhyaApr 13, 2025 am 11:20 AM
PIXTRAL -12B:Mistral AI'の最初のマルチモーダルモデル-Analytics VidhyaApr 13, 2025 am 11:20 AM導入 Mistralは、最初のマルチモーダルモデル、つまりPixtral-12B-2409をリリースしました。このモデルは、Mistralの120億個のパラメーターであるNemo 12bに基づいて構築されています。このモデルを際立たせるものは何ですか?これで、画像とTexの両方を採用できます
 生成AIアプリケーションのエージェントフレームワーク - 分析VidhyaApr 13, 2025 am 11:13 AM
生成AIアプリケーションのエージェントフレームワーク - 分析VidhyaApr 13, 2025 am 11:13 AMクエリに応答するだけでなく、情報を自律的に収集し、タスクを実行し、テキスト、画像、コードなどの複数のタイプのデータを処理するAIを搭載したアシスタントがいることを想像してください。未来的に聞こえますか?これでa
 金融セクターにおける生成AIの応用Apr 13, 2025 am 11:12 AM
金融セクターにおける生成AIの応用Apr 13, 2025 am 11:12 AM導入 金融業界は、効率的な取引と信用の可用性を促進することにより経済成長を促進するため、あらゆる国の発展の基礎となっています。取引の容易さとクレジット
 オンライン学習とパッシブアグレッシブアルゴリズムのガイドApr 13, 2025 am 11:09 AM
オンライン学習とパッシブアグレッシブアルゴリズムのガイドApr 13, 2025 am 11:09 AM導入 データは、ソーシャルメディア、金融取引、eコマースプラットフォームなどのソースから前例のないレートで生成されています。この連続的な情報ストリームを処理することは課題ですが、


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

ドリームウィーバー CS6
ビジュアル Web 開発ツール

MantisBT
Mantis は、製品の欠陥追跡を支援するために設計された、導入が簡単な Web ベースの欠陥追跡ツールです。 PHP、MySQL、Web サーバーが必要です。デモおよびホスティング サービスをチェックしてください。

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

MinGW - Minimalist GNU for Windows
このプロジェクトは osdn.net/projects/mingw に移行中です。引き続きそこでフォローしていただけます。 MinGW: GNU Compiler Collection (GCC) のネイティブ Windows ポートであり、ネイティブ Windows アプリケーションを構築するための自由に配布可能なインポート ライブラリとヘッダー ファイルであり、C99 機能をサポートする MSVC ランタイムの拡張機能が含まれています。すべての MinGW ソフトウェアは 64 ビット Windows プラットフォームで実行できます。

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

