


「自己回帰 LLM はすでに人間レベルの AI に近づいていると考えている人、または人間レベルの AI に到達するには単純にスケールアップする必要があると考えている人は、必ずこれを読んでください。AR-LLM の推論は非常に限られており、計画能力、この問題を解決するには、計画能力を大きくし、より多くのデータでトレーニングすることでは解決できません。」
長い間、図Spirit Award の受賞者である Yann LeCun は LLM の「質問者」であり、自己回帰モデルは LLM モデルの GPT シリーズが依存する学習パラダイムです。彼は自己回帰と LLM に対する批判を何度も公に表明しており、次のような多くの金言を生み出しています。自己回帰モデルを使用します。"
"自己回帰生成モデルは最悪です!"
"LLM は世界を非常に表面的に理解しています。 "
# LeCun が最近再び叫んだのは、新しくリリースされた 2 つの論文です:
## 「Can LLM」文献が示唆しているように、そのソリューションを本当に自己批判 (そして反復的に改善) していますか? 私たちのグループからの 2 つの新しい論文、reason (https://arxiv.org/abs/2310.12397) と planing (https://arxiv.org/abs/2310.08118) ) これらの主張を調査する (そして異議を唱える) という使命があります。」 
参照 さて、GPT-4 の検証および自己批判機能を調査するこれら 2 つの論文のテーマは、多くの人々の共感を呼びました。 。
論文の著者らは、LLM が (言語形式であれコード形式であれ) 優れた「アイデア生成器」であると信じていると述べましたが、彼ら自身の計画/推論を保証することはできません能力。したがって、これらは LLM-Modulo 環境 (ループ内に信頼できる推論者または人間の専門家がいる環境) で使用するのが最適です。自己批判には検証が必要であり、検証は推論の一形態です (したがって、LLM の自己批判能力に関するあらゆる主張には驚かれます)。
同時に、疑問の声もあります。「畳み込みネットワークの推論能力はより制限されていますが、だからといって AlphaZero の成果が現れるのを妨げるものではありません。推論プロセスと確立 (RL) フィードバック ループ。モデル機能により、非常に深い推論 (研究レベルの数学など) が可能になると思います。」
これに関して、LeCun 氏のアイデアは次のとおりです。「AlphaZero は計画を「本当に」実行します。これは、畳み込みネットワークを使用して適切なアクションを見つけ出し、別の畳み込みネットワークを使用して位置を評価するモンテカルロ ツリー検索によって行われます。ツリーの探索に費やす時間は無限になる可能性がありますが、それはすべて推論と計画です。 "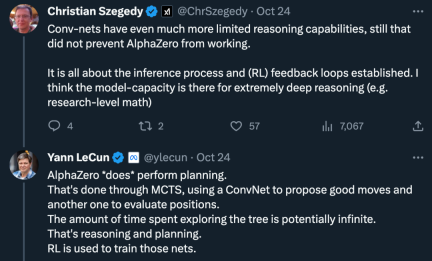
将来的には、自己回帰 LLM に推論機能と計画機能があるかどうかというテーマが最終決定されない可能性があります。
次に、これら 2 つの新しい論文が何について述べているかを見てみましょう。
論文 1: GPT-4 はそれが間違っていることを知らない: 推論問題に対する反復プロンプトの分析
最初の論文は、GPT-4 を含む最先端の LLM の自己批判能力について研究者の間で疑問を引き起こしました。
論文アドレス: https://arxiv.org/pdf/2310.12397.pdf
接続論文の紹介を見てみましょう。
大規模言語モデル (LLM) の推論機能については、人々の間で常にかなりの意見の相違がありました。当初、研究者らは、モデルの規模が拡大するにつれて、LLM の推論機能が自動的に現れるだろうと楽観視していました。しかし、失敗が増えるにつれ、期待は薄れていきました。その後、研究者は一般に、LLM には反復的な方法で LLM ソリューションを自己批判し、改善する能力があると信じており、この見解は広く普及しました。
しかし、これは本当にそうなのでしょうか?
アリゾナ州立大学の研究者らは、新しい研究で LLM の推論能力を調査しました。具体的には、最も有名な NP 完全問題の 1 つであるグラフの色付け問題における反復プロンプトの有効性に焦点を当てました。
研究では、(i) LLM はグラフの色付けインスタンスを解決するのが苦手 (ii) LLM は解決策を検証するのが得意ではないため、反復モードでは効果がないことが示されています。したがって、この論文の結果は、最先端の LLM の自己批判的な機能について疑問を引き起こします。
この論文では、いくつかの実験結果を示しています。たとえば、ダイレクト モードでは、LLM はグラフの色付けインスタンスを解決するのが非常に苦手です。さらに、この研究では、LLM が検証するのが苦手であることも判明しました。ソリューション。さらに悪いことに、システムは正しい色を認識できず、間違った色が表示されてしまいます。
次の図はグラフの色付け問題の評価です。この設定では、GPT-4 は独立した自己クリティカル モードで色を推測できます。自己クリティカル ループの外側には、外部音声バリデータがあります。

その結果、GPT4 の色の推測精度は 20% 未満であり、さらに驚くべきことに、自己批判モードの精度が低いことがわかりました (下の画像)。列 2) の精度が最も低くなります。この論文では、外部の音声検証者が推測した色について証明可能な正しい批判を提供した場合に、GPT-4 がその解決策を改善するかどうかという関連する問題も検討します。この場合、リバースヒンティングによりパフォーマンスが大幅に向上します。
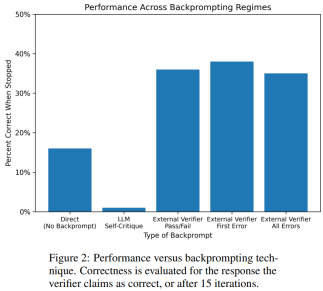
GPT-4 が誤って有効な色を推測したとしても、その自己批判により違反が存在しないという幻覚を引き起こす可能性があります。

#最後に、グラフの色付けの問題について、著者が要約を示します。
- 自己批判 GPT-4 は検証能力が低いため、実際に LLM のパフォーマンスに悪影響を及ぼします;
- 外部バリデーターからのフィードバックにより、LLM のパフォーマンスが大幅に向上します。
論文 2: 大規模な言語モデルは、自身の計画を自己批判することで本当に改善できるのか?
「自分自身の計画を自己批判することで、大規模言語モデルは本当に改善できるのか?」という論文で、研究チームは、計画のコンテキストで自己検証/批判する LLM の能力を調査しました。
この論文では、特に古典的な計画問題の文脈において、LLM が自身の出力を批評する能力についての体系的な研究を提供します。最近の研究は、特に反復設定における LLM の自己批判的な可能性について楽観的ですが、この研究は別の視点を示唆しています。

論文アドレス: https://arxiv.org/abs/2310.08118
予想外 ただし、結果は、自己批判により、特に外部検証者や LLM 検証者を備えたシステムと比較して、計画生成のパフォーマンスが低下することを示しています。 LLM は大量のエラー メッセージを生成する可能性があるため、システムの信頼性が損なわれます。
古典的な AI 計画ドメイン Blocksworld に関する研究者らの実証的評価は、LLM の自己批判的機能が問題の計画には効果的ではないことを浮き彫りにしました。バリデーターは大量のエラーを生成する可能性があり、特に計画の正確さが重要な領域では、システム全体の信頼性に悪影響を及ぼします。
興味深いことに、フィードバックの性質 (バイナリ フィードバックまたは詳細フィードバック) は、プラン生成のパフォーマンスに大きな影響を与えません。これは、中心的な問題は、問題ではなく LLM のバイナリ検証機能にあることを示唆しています。フィードバックの粒度。
以下の図に示すように、この調査の評価アーキテクチャには、ジェネレーター LLM とベリファイアー LLM の 2 つの LLM が含まれています。特定のインスタンスについて、生成者 LLM は候補計画を生成する責任を負い、検証者 LLM はその正しさを判断します。計画が間違っていると判明した場合、バリデーターはエラーの理由を示すフィードバックを提供します。次に、このフィードバックはジェネレーター LLM に転送され、ジェネレーター LLM に新しい候補プランを生成するよう促します。この研究のすべての実験では、GPT-4 をデフォルトの LLM として使用しました。

この研究では、Blocksworld でのいくつかの計画生成方法を実験し、比較します。具体的には、この研究ではさまざまな方法を評価するために 100 個のランダムなインスタンスを生成しました。最終的な LLM 計画の正確性を現実的に評価するために、この研究では外部バリデーター VAL を採用しています。
表 1 に示すように、LLM LLM バックプロンプト方式は、精度の点で非バックプロンプト方式よりわずかに優れています。

100 個のインスタンスのうち、バリデーターは 61 個 (61%) を正確に識別しました。
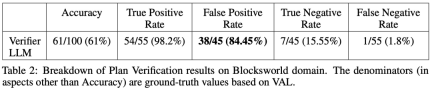
#以下の表は、フィードバックなしを含む、さまざまなレベルのフィードバックを受け取ったときの LLM のパフォーマンスを示しています。

以上がLeCun 氏は再び自己回帰 LLM の悪口を言った: 2 つの論文で証明されているように、GPT-4 の推論能力は非常に限られているの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 最高の迅速なエンジニアリング技術の最新の年次編集Apr 10, 2025 am 11:22 AM
最高の迅速なエンジニアリング技術の最新の年次編集Apr 10, 2025 am 11:22 AM私のコラムに新しいかもしれない人のために、具体化されたAI、AI推論、AIのハイテクブレークスルー、AIの迅速なエンジニアリング、AIのトレーニング、AIのフィールディングなどのトピックなど、全面的なAIの最新の進歩を広く探求します。
 ヨーロッパのAI大陸行動計画:GigaFactories、Data Labs、Green AIApr 10, 2025 am 11:21 AM
ヨーロッパのAI大陸行動計画:GigaFactories、Data Labs、Green AIApr 10, 2025 am 11:21 AMヨーロッパの野心的なAI大陸行動計画は、人工知能のグローバルリーダーとしてEUを確立することを目指しています。 重要な要素は、AI GigaFactoriesのネットワークの作成であり、それぞれが約100,000の高度なAIチップを収容しています。
 Microsoftの簡単なエージェントストーリーは、より多くのファンを作成するのに十分ですか?Apr 10, 2025 am 11:20 AM
Microsoftの簡単なエージェントストーリーは、より多くのファンを作成するのに十分ですか?Apr 10, 2025 am 11:20 AMAIエージェントアプリケーションに対するMicrosoftの統一アプローチ:企業の明確な勝利 新しいAIエージェント機能に関するマイクロソフトの最近の発表は、その明確で統一されたプレゼンテーションに感銘を受けました。 TEで行き詰まった多くのハイテクアナウンスとは異なり
 従業員へのAI戦略の販売:Shopify CEOのマニフェストApr 10, 2025 am 11:19 AM
従業員へのAI戦略の販売:Shopify CEOのマニフェストApr 10, 2025 am 11:19 AMShopify CEOのTobiLütkeの最近のメモは、AIの能力がすべての従業員にとって基本的な期待であると大胆に宣言し、会社内の重大な文化的変化を示しています。 これはつかの間の傾向ではありません。これは、pに統合された新しい運用パラダイムです
 IBMは、完全なAI統合でZ17メインフレームを起動しますApr 10, 2025 am 11:18 AM
IBMは、完全なAI統合でZ17メインフレームを起動しますApr 10, 2025 am 11:18 AMIBMのZ17メインフレーム:AIを強化した事業運営の統合 先月、IBMのニューヨーク本社で、Z17の機能のプレビューを受け取りました。 Z16の成功に基づいて構築(2022年に開始され、持続的な収益の成長の実証
 5 chatgptプロンプトは他の人に依存して停止し、自分を完全に信頼するApr 10, 2025 am 11:17 AM
5 chatgptプロンプトは他の人に依存して停止し、自分を完全に信頼するApr 10, 2025 am 11:17 AM揺るぎない自信のロックを解除し、外部検証の必要性を排除します! これらの5つのCHATGPTプロンプトは、完全な自立と自己認識の変革的な変化に向けて導きます。 ブラケットをコピー、貼り付け、カスタマイズするだけです
 AIはあなたの心に危険なほど似ていますApr 10, 2025 am 11:16 AM
AIはあなたの心に危険なほど似ていますApr 10, 2025 am 11:16 AM人工知能のセキュリティおよび研究会社であるAnthropicによる最近の[研究]は、これらの複雑なプロセスについての真実を明らかにし始め、私たち自身の認知領域に不穏に似た複雑さを示しています。自然知能と人工知能は、私たちが思っているよりも似ているかもしれません。 内部スヌーピング:人類の解釈可能性研究 人類によって行われた研究からの新しい発見は、AIの内部コンピューティングをリバースエンジニアリングすることを目的とする機械的解釈可能性の分野の大きな進歩を表しています。AIが何をするかを観察するだけでなく、人工ニューロンレベルでそれがどのように行うかを理解します。 誰かが特定のオブジェクトを見たり、特定のアイデアについて考えたりしたときに、どのニューロンが発射するかを描くことによって脳を理解しようとすることを想像してください。 a
 Dragonwingは、QualcommのEdge Momentumを紹介していますApr 10, 2025 am 11:14 AM
Dragonwingは、QualcommのEdge Momentumを紹介していますApr 10, 2025 am 11:14 AMQualcomm's DragonWing:企業とインフラストラクチャへの戦略的な飛躍 Qualcommは、新しいDragonwingブランドで世界的に企業やインフラ市場をターゲットにして、モバイルを超えてリーチを積極的に拡大しています。 これは単なるレブランではありません


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

Safe Exam Browser
Safe Exam Browser は、オンライン試験を安全に受験するための安全なブラウザ環境です。このソフトウェアは、あらゆるコンピュータを安全なワークステーションに変えます。あらゆるユーティリティへのアクセスを制御し、学生が無許可のリソースを使用するのを防ぎます。

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

SublimeText3 英語版
推奨: Win バージョン、コードプロンプトをサポート!

メモ帳++7.3.1
使いやすく無料のコードエディター
ホットトピック
 7453
7453 15137452
15137452