
ホームページ >テクノロジー周辺機器 >AI >文字を入力するよりも大きなモデルの写真を効率的に見てみましょう。 NeurIPS 2023 の新しい研究では、精度が 7.8% 向上するマルチモーダル クエリ手法が提案されています
文字を入力するよりも大きなモデルの写真を効率的に見てみましょう。 NeurIPS 2023 の新しい研究では、精度が 7.8% 向上するマルチモーダル クエリ手法が提案されています

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-10-23 11:45:09841ブラウズ
大型モデルの「画像を読み取る」能力は非常に優れているのに、なぜ依然として間違ったものを見つけてしまうのでしょうか?
たとえば、見た目が似ていないコウモリとコウモリを混同したり、一部のデータセットで珍しい魚を認識しなかったり...
これは、「検索するときに大規模なモデルを使用しているため」です。何か」というテキスト # が入力されることがよくあります。
「コウモリ」 (コウモリかコウモリ?) や「悪魔のメダカ」 (キプリノドン ディアボリス) など、説明があいまいまたは偏りすぎている場合、AI は大いに混乱するでしょう。
これにより、ターゲット検出、特にオープンワールド (未知のシーン) ターゲット検出タスクに大規模なモデルが使用されるようになります。効果がないことが多いですが、想像通りでした。
NeurIPS 2023 に含まれる論文で、この問題がついに解決されました。

この論文では、マルチモーダル クエリMQ-Det に基づくターゲット検出方法を提案しています。これには、前の画像の例では、大規模なモデルを使用して物を見つける精度が大幅に向上します。
ベンチマーク検出データ セット LVIS では、ダウンストリーム タスク モデルの微調整を必要とせずに、MQ-Det により、主流の検出大規模モデルの GLIP 精度が約 # 向上します。平均 ##7.8%#。##、13 のベンチマークの小さなサンプルの下流タスクでは、平均精度が 6.3% 向上しました。 これはどのように行われるのでしょうか?見に来ましょう。
次の内容は、論文の著者であり Zhihu ブロガーである @沁园夏からの転載です:Directory
MQ-Det : マルチモード 動的クエリのための大規模なオープンワールド ターゲット検出モデル- 1.1 テキスト クエリからマルチモーダル クエリへ
- 1.2 MQ-Det プラグ アンド プレイ マルチモーダル クエリ モデルアーキテクチャ
- 1.3 MQ-Det の効率的なトレーニング戦略
- 1.4 実験結果: 微調整不要の評価
- 1.5 実験結果: 少数ショットの評価
- 1.6 マルチ-モーダル クエリ ターゲット検出 Prospect
- MQ-Det: マルチモーダル クエリを使用したオープンワールド オブジェクト検出のための大規模モデル
Multi-モーダル クエリされたオブジェクトの実際の検出
ペーパー リンク:https://www.php.cn/link/9c6947bd95ae487c81d4e19d3ed8cd6f
コードアドレス:https://www.php.cn/link/2307ac1cfee5db3a5402aac9db25cc5d

百聞は一見にしかず : 画像とテキストの事前トレーニングの台頭と、テキストのオープン セマンティクスの助けにより、ターゲット検出は徐々にオープンの段階に入りました。世界認識。この目的を達成するために、多くの大規模な検出モデルはテキスト クエリのパターンに従い、カテゴリ別テキストの説明を使用してターゲット画像内の潜在的なターゲットをクエリします。ただし、このアプローチは「広範囲であるが正確ではない」という問題に直面することがよくあります。
たとえば、(1) 図 1 のきめの細かいオブジェクト(魚種) の検出では、限られたテキストでさまざまなきめの細かい魚種を説明するのが難しいことがよくあります。 2) カテゴリの曖昧さ (「バット」はコウモリとコウモリの両方を指す可能性があります) 。
しかし、上記の問題は画像の例によって解決できます。テキストと比較して、画像は対象オブジェクトのより豊富な特徴のヒント を提供できますが、同時にテキストには があります。強力な汎用性。
したがって、2 つのクエリ方法を有機的に組み合わせる方法は自然なアイデアになりました。マルチモーダル クエリ機能を取得する際の難しさ : マルチモーダル クエリを使用してこのようなモデルを取得する方法には 3 つの課題があります: (1) 直接微調整するのは非常に困難です。画像例が限られているため、壊滅的な忘却を引き起こしやすいです; (2) 大規模な検出モデルを最初からトレーニングすると、より一般化できますが、多額の費用がかかります。たとえば、1 枚のカードで GLIP をトレーニングするには、480 日間で 3,000 万のデータが必要です。
マルチモーダル クエリ ターゲット検出: 上記の考慮事項に基づいて、著者はシンプルで効果的なモデル設計とトレーニング戦略 MQ-Det を提案しました。
MQ-Det は、既存の大規模なフリーズ テキスト クエリ検出モデルに基づいて少数のゲート知覚モジュール(GCP) を挿入し、視覚的な例から入力を受け取り、視覚条件マスクも設計します。言語予測トレーニング戦略により、マルチモーダル クエリに対する高性能の検出器が効率的に得られます。
1.2 MQ-Det プラグ アンド プレイ マルチモーダル クエリ モデル アーキテクチャ
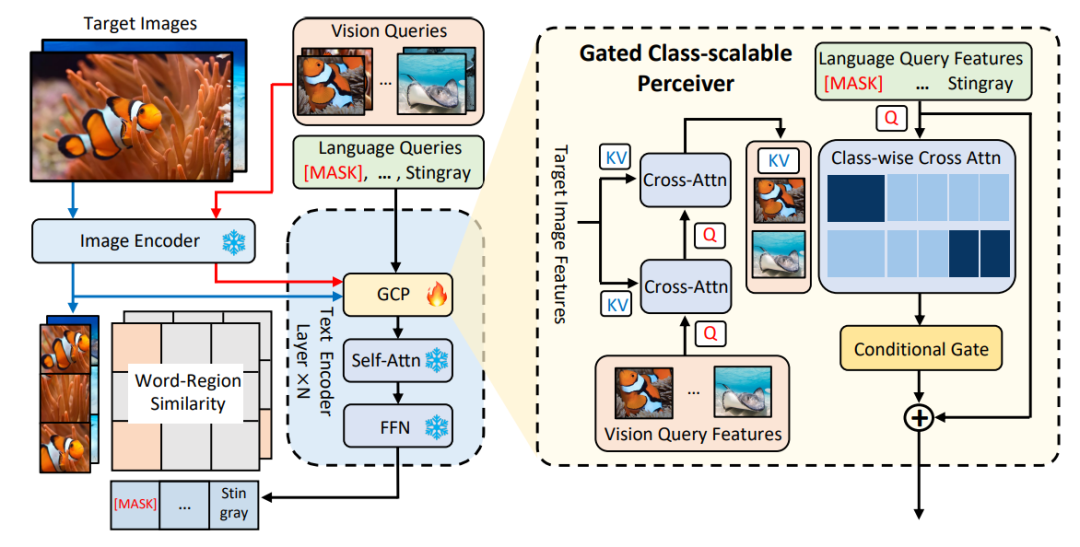
図 1 に示すように、作成者は、既存のフリーズ テキスト クエリ検出大規模モデルのテキスト エンコーダー側に、ゲート アウェアネス モジュール
(GCP) をレイヤーごとに挿入しました。 ##、GCP の動作モードは、次の式で簡潔に表すことができます。
i 番目のカテゴリについて、最初に交差する視覚的な例 Vi を入力します。ターゲット画像 I アテンション 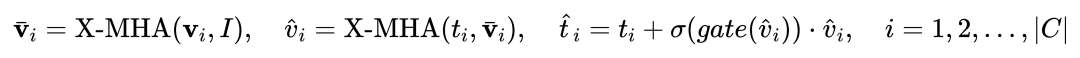 (X-MHA)
(X-MHA)
を取得し、各カテゴリのテキスト ti は対応するカテゴリの視覚的な例 とクロスアテンションされて ## を取得します。 #、その後、元のテキスト ti と視覚的に拡張されたテキスト が、ゲート モジュールのゲートを通じて融合され、現在のレイヤーの出力 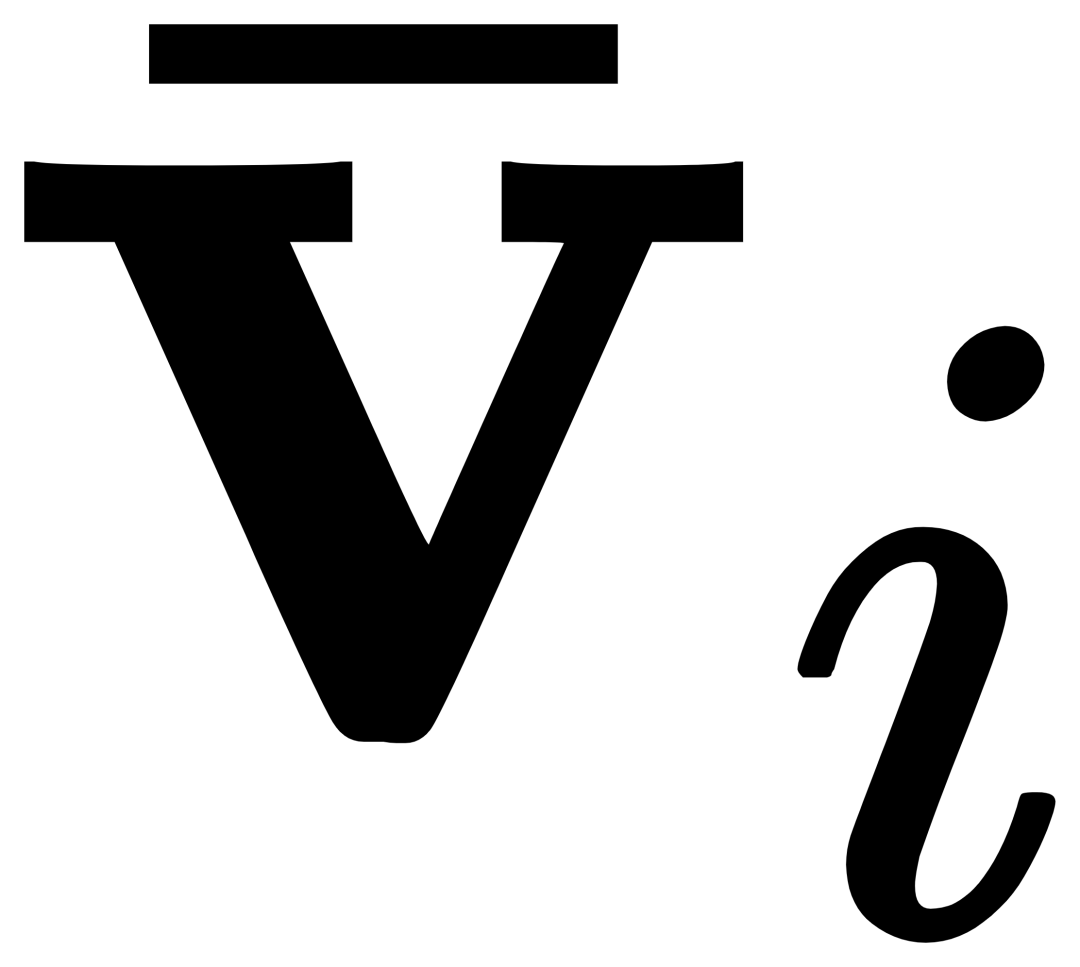 が得られます。このような単純な設計は、(1) カテゴリの拡張性、(2) 意味の補完、(3) 忘れ防止の 3 つの原則に従っています。詳細な説明については、原文を参照してください。
が得られます。このような単純な設計は、(1) カテゴリの拡張性、(2) 意味の補完、(3) 忘れ防止の 3 つの原則に従っています。詳細な説明については、原文を参照してください。 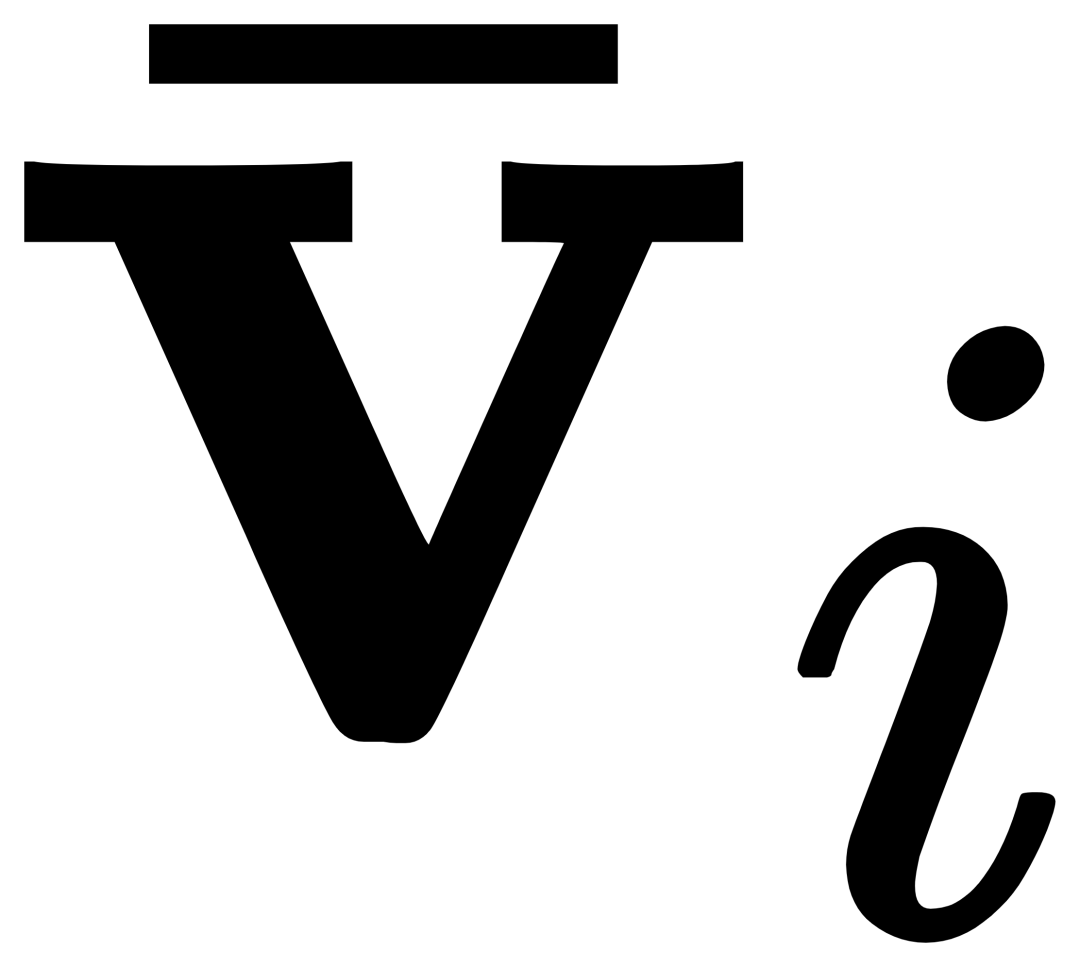
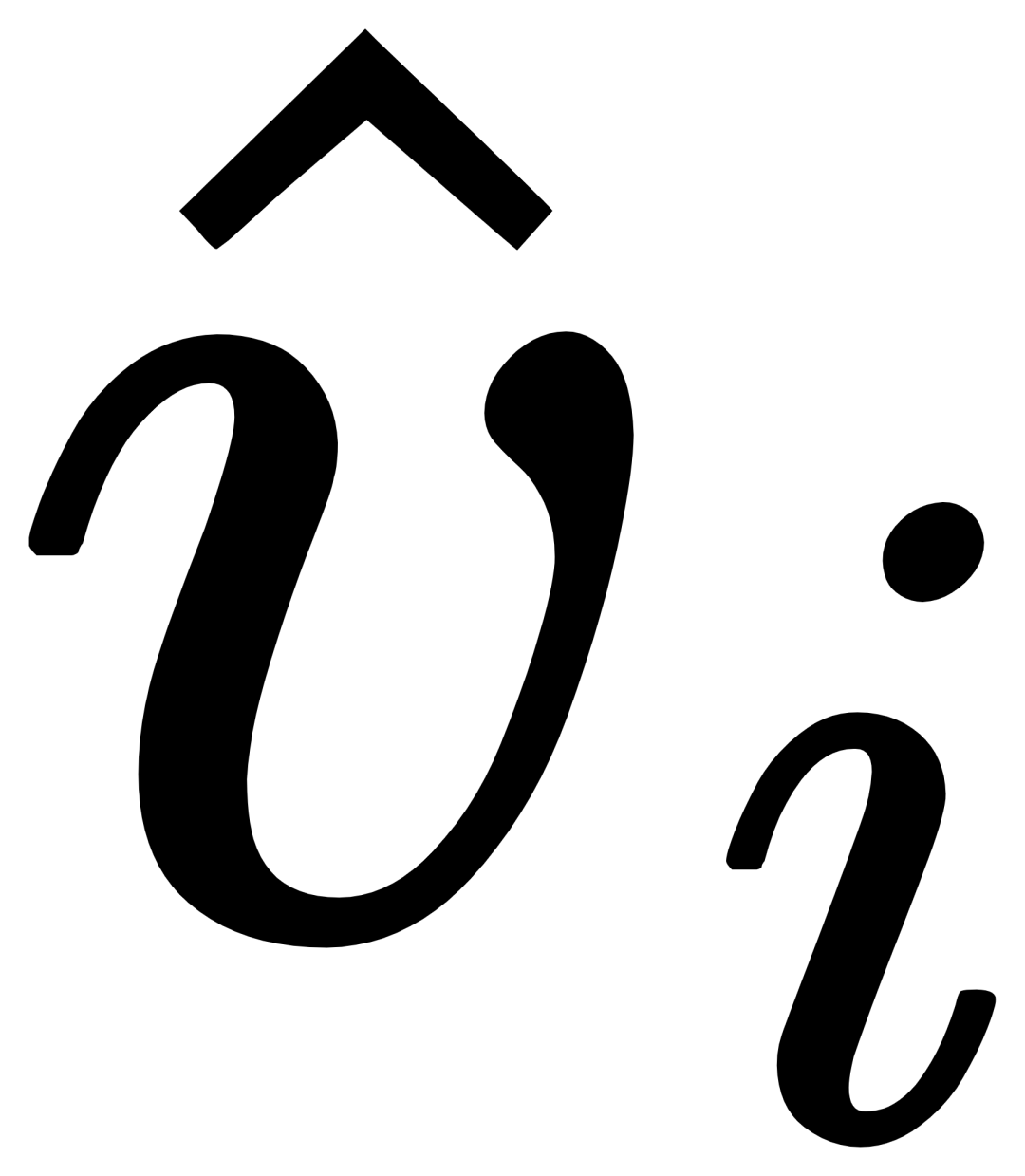 1.3 MQ-Det の効率的なトレーニング戦略
1.3 MQ-Det の効率的なトレーニング戦略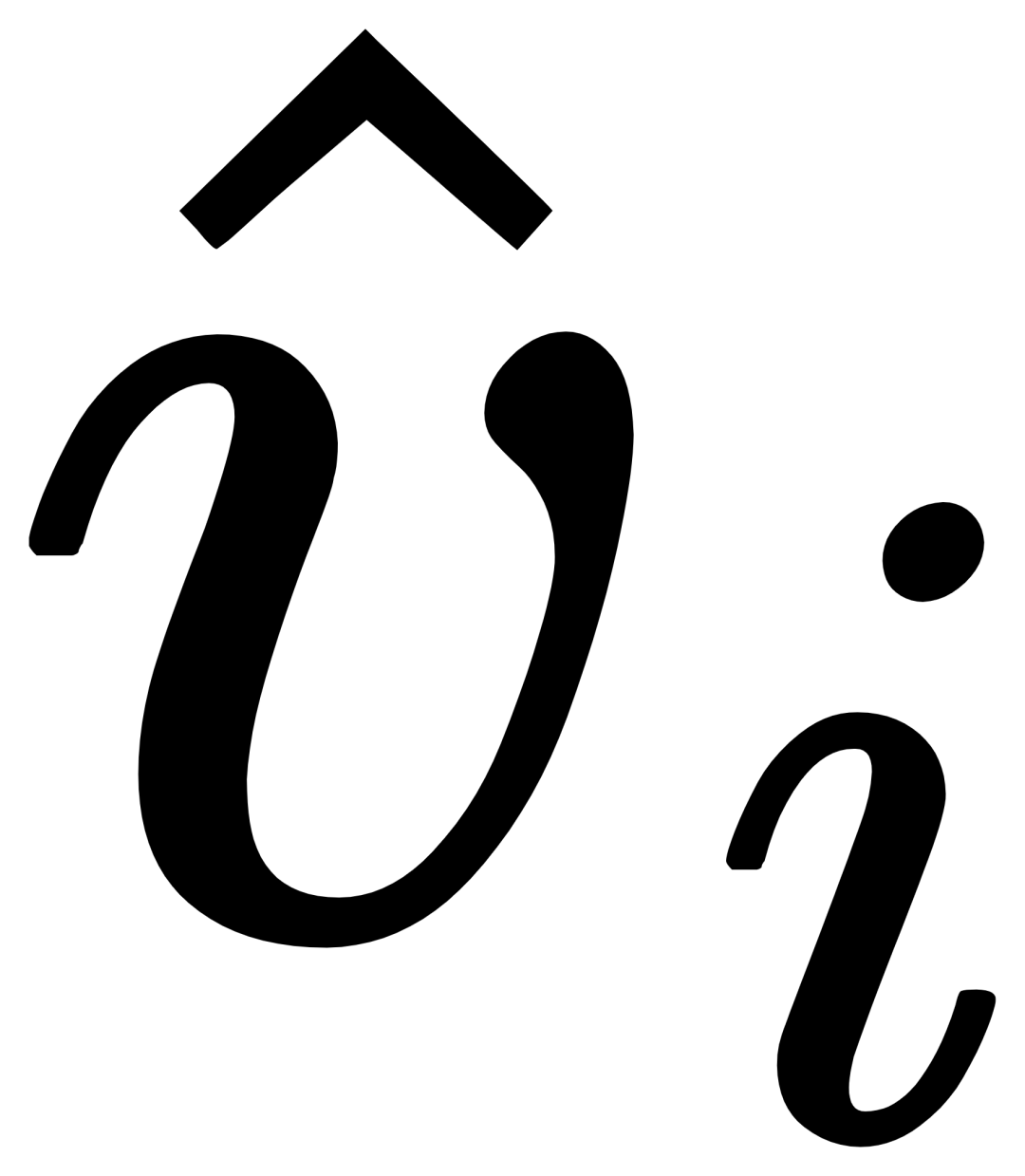
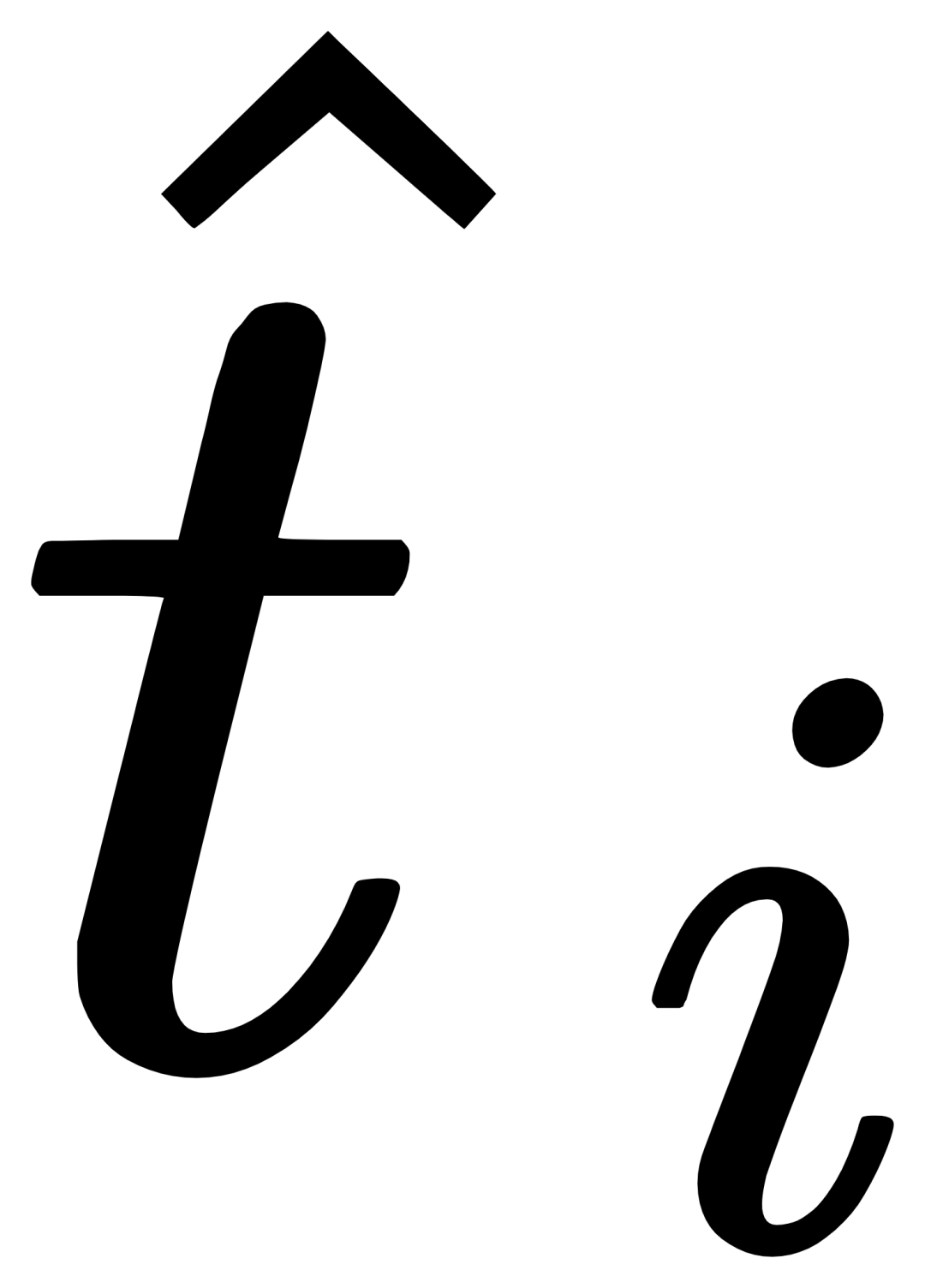
現在の大規模な事前トレーニング済み検出モデルにより、テキスト クエリ 優れた一般化能力を備えており、論文の著者は、元のテキストの特徴に基づいて視覚的な詳細をわずかに調整するだけで十分だと考えています。 この記事には、元の事前トレーニング済みモデルのパラメーターを開いた後で微調整すると、壊滅的な忘却の問題が発生しやすく、代わりにオープンワールドを検出する能力が失われる可能性があることを発見した具体的な実験デモンストレーションもあります。 。
したがって、MQ-Det は、フリーズされたテキスト クエリの事前トレーニングされた検出器に基づいてトレーニングに挿入された GCP モジュールを調整するだけで、既存のテキスト クエリの検出器に視覚情報を効率的に挿入できます。
論文では、著者は、MQ-Det の構造設計とトレーニング技術を現行の SOTA モデルである GLIP と GroundingDINO にそれぞれ適用し、手法の汎用性を検証しています。
視覚条件付きマスク言語予測トレーニング戦略著者は、フリーズした事前プログラミングの問題を解決するために、視覚条件付きマスク言語予測トレーニング戦略も提案しました。モデルのトレーニングによって引き起こされる学習の慣性の問題。 いわゆる学習慣性とは、検出器がトレーニング プロセス中に元のテキスト クエリの特徴を維持する傾向があるため、新しく追加されたビジュアル クエリの特徴を無視することを意味します。
この目的のために、MQ-Det はトレーニング中にテキスト トークンを [MASK] トークンにランダムに置き換え、モデルにビジュアル クエリ機能側からの学習を強制します。
##この戦略は単純ですが、非常に効果的であり、実験結果から判断すると、この戦略は大幅なパフォーマンスの向上をもたらしました。 1.4 実験結果: 微調整不要の評価微調整不要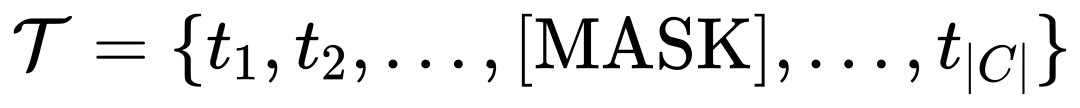 : 従来のゼロショットとの比較
: 従来のゼロショットとの比較
評価では、カテゴリ テキストがテストされ、MQ-Det はより現実的な評価戦略
finetuning-freeを提案します。これは、ダウンストリームでの微調整を行わずに、ユーザーがカテゴリ テキスト、画像の例、または両方の組み合わせを使用してオブジェクト検出を実行できるように定義されています。
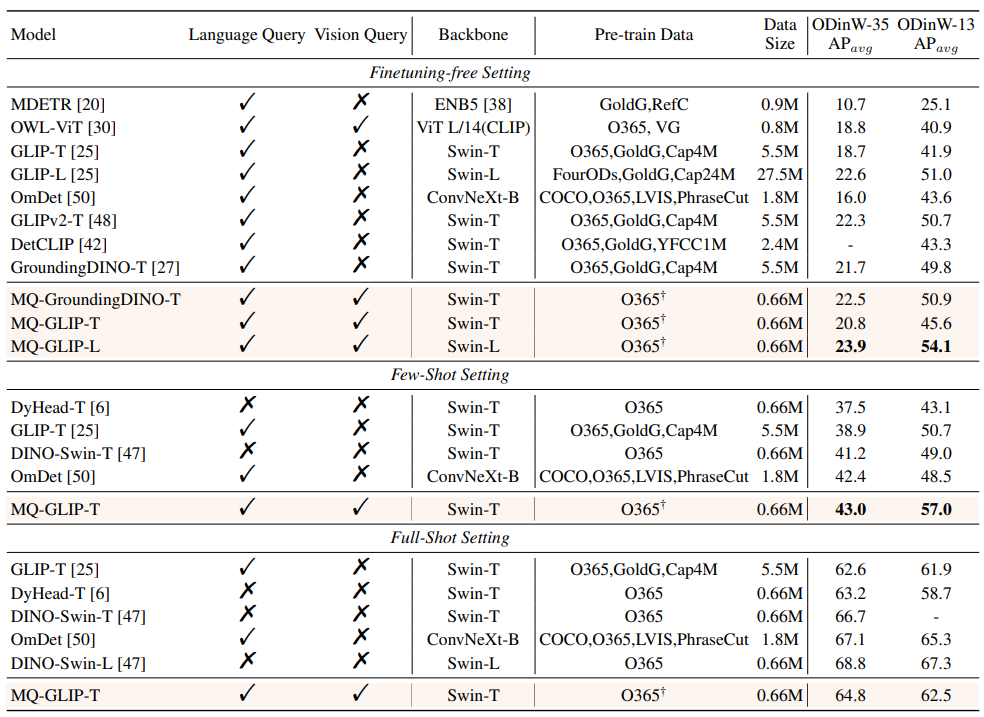
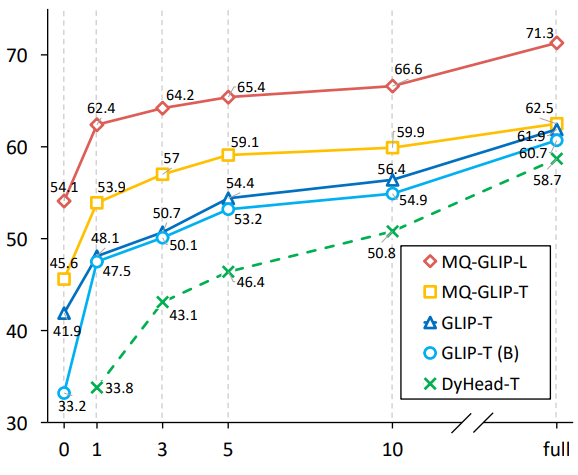
微調整なしの設定では、MQ-Det はカテゴリごとに 5 つの視覚的な例を選択し、カテゴリ テキストを組み合わせてターゲット検出を行います。ただし、他の既存のモデルは視覚的なクエリをサポートしておらず、プレーン テキストでのオブジェクト検出のみが可能です。説明。以下の表は、LVIS MiniVal および LVIS v1.0 での検出結果を示しています。マルチモーダル クエリの導入により、オープンワールドのターゲット検出能力が大幅に向上することがわかります。 △表 1 LVIS ベンチマーク データ セットにおける各検出モデルの微調整なしのパフォーマンス 表 1 からわかるように、MQ-GLIP-L はGLIP最高性能 - Lを基準にAPが7%以上増加し、効果は絶大! △表 2 各モデルは 35 の検出タスクを実行します。ODinW-35 とその 13 のサブセット ODinW-13 のパフォーマンス 著者はさらに、35 の下流検出タスク ODinW-35 について包括的な実験を実施しました。表 2 からわかるように、微調整不要の強力なパフォーマンスに加えて、MQ-Det は優れた小規模サンプル検出機能も備えており、これによりマルチモーダル クエリの可能性がさらに裏付けられます。図 2 は、GLIP 上の MQ-Det の大幅な改善も示しています。 △図 2 データ利用効率の比較、横軸: トレーニングサンプル数、縦軸: OdinW-13 ターゲット検出は実用化に基づく研究分野として、アルゴリズムの実装が非常に重要視されています。 以前の純粋なテキスト クエリ ターゲット検出モデルは良好な一般化を示しましたが、実際のオープンワールド検出ではテキストがきめ細かい情報をカバーすることは困難であり、画像の豊富な情報の粒度を完全にカバーすることは困難です。このリンクは完了しました。 これまでのところ、テキストは一般的ですが正確ではなく、画像は正確ではありますが一般的ではないことがわかりました。この 2 つ、つまりマルチモーダル クエリを効果的に組み合わせることができれば、オープンワールドのターゲット検出が推進されるでしょう。さらに前へ。 MQ-Det はマルチモーダル クエリの最初の一歩を踏み出し、その大幅なパフォーマンスの向上は、マルチモーダル クエリのターゲット検出の大きな可能性も示しています。 同時に、テキストによる説明と視覚的な例の導入により、ユーザーの選択肢が増え、ターゲット検出がより柔軟でユーザーフレンドリーになります。 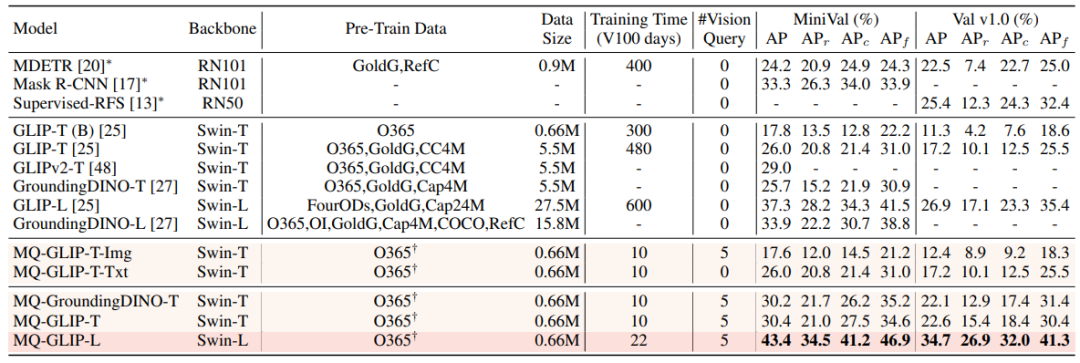
1.5 実験結果: 少数ショット評価
1.6 マルチの平均 AP modal ターゲット検出の展望を問い合わせる
以上が文字を入力するよりも大きなモデルの写真を効率的に見てみましょう。 NeurIPS 2023 の新しい研究では、精度が 7.8% 向上するマルチモーダル クエリ手法が提案されていますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。