
ホームページ >テクノロジー周辺機器 >AI >LLaMA2 コンテキストの長さは 100 万トークンにまで急増し、調整する必要があるハイパーパラメータは 1 つだけです。
LLaMA2 コンテキストの長さは 100 万トークンにまで急増し、調整する必要があるハイパーパラメータは 1 つだけです。

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-10-21 14:25:01781ブラウズ
ほんの少し調整するだけで、大規模モデルのサポート コンテキスト サイズを 16,000 トークンから 100 万 に拡張できます。 !
まだ LLaMA 2 を使用していますが、パラメーターは 70 億しかありません。
最も人気のある Claude 2 と GPT-4 でさえ、コンテキスト長が 100,000 と 32,000 しかサポートしていないことを知っておく必要があります。この範囲を超えると、大規模なモデルは無意味なことを話し始め、物事を記憶できなくなります。
さて、復旦大学と上海人工知能研究所による新しい研究では、一連の大規模モデルのコンテキスト ウィンドウの長さを増やす方法を発見しただけでなく、ルール##も発見しました。 #。

は 1 つのハイパーパラメータを調整するだけで済み、 は大規模モデルを安定して改善しながら出力効果を確保できます 外挿パフォーマンス。 外挿とは、大規模モデルの入力長が事前トレーニングされたテキストの長さを超えた場合の出力パフォーマンスの変化を指します。外挿能力が良くない場合、入力の長さが事前トレーニングされたテキストの長さを超えると、大規模なモデルは「意味のないことを話す」ことになります。
それでは、大規模モデルの外挿機能を正確にどのように改善できるのでしょうか?また、どのように実現するのでしょうか?大規模モデルの外挿能力を向上させる「仕組み」
大規模モデルの外挿能力を向上させるこの方法は、Transformer アーキテクチャにおける位置コーディング
と同じです。 . モジュール関連。実際、単純なアテンション メカニズム (アテンション) モジュールでは、異なる位置にあるトークンを区別することができません。たとえば、「私はリンゴを食べる」と「リンゴが私を食べる」は目に違いがありません。
したがって、語順情報を理解して文の意味を真に理解できるようにするには、位置コーディングを追加する必要があります。 現在の Transformer の位置エンコード方法には、絶対位置エンコード (位置情報を入力に統合)、相対位置エンコード (位置情報をアテンション スコア計算に書き込む)、回転位置エンコードが含まれます。その中で最もよく使われているのは、回転位置エンコーディングであるRoPE
です。RoPE は、絶対位置エンコードを通じて相対位置エンコードの効果を実現しますが、相対位置エンコードと比較して、大規模モデルの外挿可能性をより向上させることができます。
RoPE 位置エンコーディングを使用して大規模モデルの外挿機能をさらに刺激する方法が、最近の多くの研究の新しい方向性になりました。 これらの研究は、主に注意力の制限
と回転角度の調整 という 2 つの主要な学派に分かれています。 注意力の制限に関する代表的な研究には、ALiBi、xPos、BCA などが含まれます。 MIT によって最近提案された StreamingLLM は、大規模なモデルが無限の入力長を達成できるようにします (ただし、コンテキスト ウィンドウの長さは増加しません)。これは、この方向の研究の種類に属します。
△ソース作成者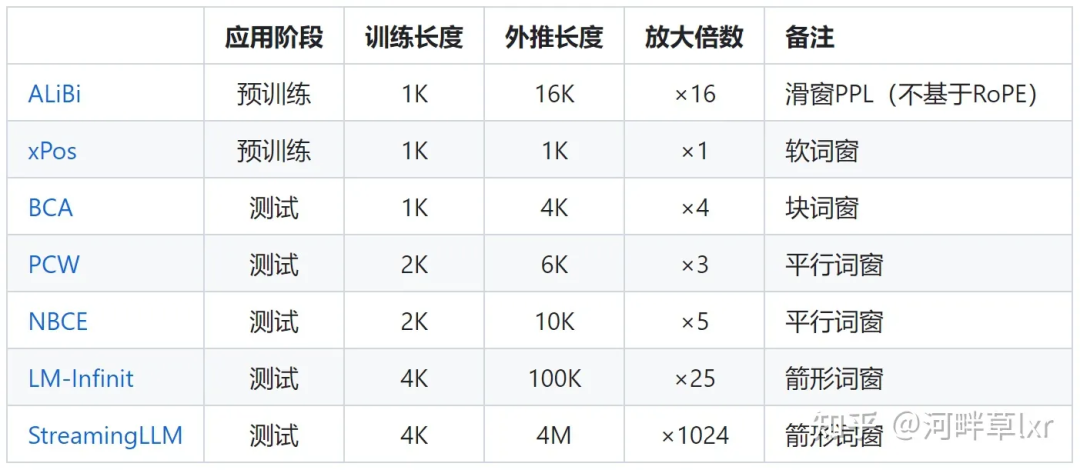
△画像ソース作者
 Meta の最近人気の LLaMA2 Long 研究を例として、RoPE ABF Method と呼ばれる手法を提案しました。ハイパーパラメータとして、大規模モデルのコンテキスト長が
Meta の最近人気の LLaMA2 Long 研究を例として、RoPE ABF Method と呼ばれる手法を提案しました。ハイパーパラメータとして、大規模モデルのコンテキスト長が
32,000 トークン 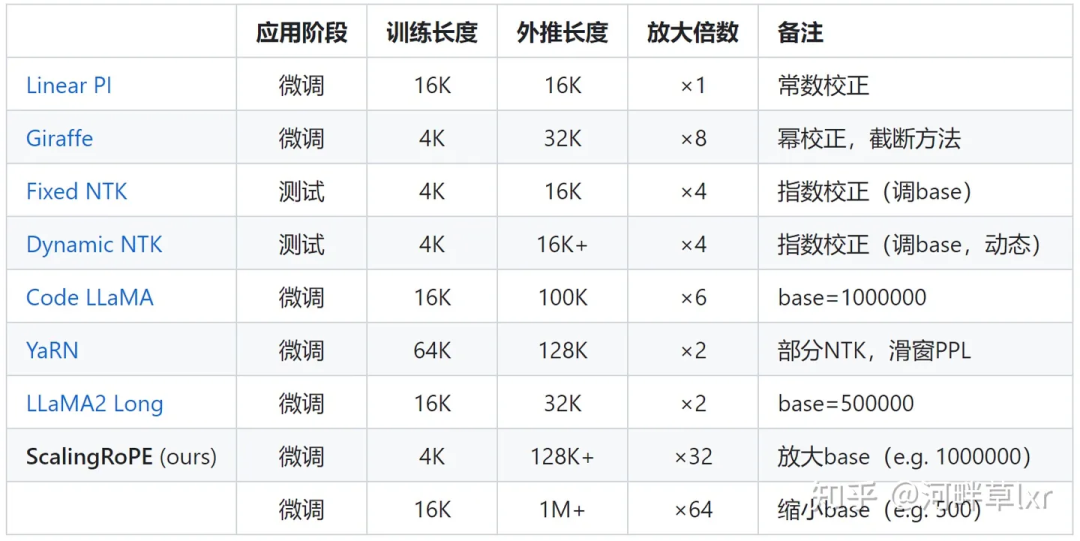 Meta の最近人気の LLaMA2 Long 研究を例として、RoPE ABF Method と呼ばれる手法を提案しました。ハイパーパラメータとして、大規模モデルのコンテキスト長が
Meta の最近人気の LLaMA2 Long 研究を例として、RoPE ABF Method と呼ばれる手法を提案しました。ハイパーパラメータとして、大規模モデルのコンテキスト長が まで正常に拡張されました。
このハイパーパラメータは、Code LLaMA および LLaMA2 Long らによって発見された "スイッチ" とまったく同じです。——
回転角 Base(base ) 。
これを微調整するだけで、大規模モデルの外挿パフォーマンスが確実に向上します。 ただし、Code LLaMA であっても LLaMA2 Long であっても、外挿機能を強化するために、特定のベースと継続的なトレーニングの長さに基づいて微調整されるだけです。
RoPE 位置エンコーディングを使用する
すべての大規模モデルで外挿パフォーマンスを確実に向上させるパターンを見つけることは可能でしょうか?
このルールをマスターすれば、文脈は簡単です 100w 復旦大学と上海 AI 研究所の研究者は、この問題について実験を行いました。
彼らはまず、RoPE 外挿能力に影響を与えるいくつかのパラメータを分析し、
Critical Dimension(Critical Dimension) と呼ばれる概念を提案し、この概念に基づいて、
のセットを結論付けました。 RoPE 外挿スケーリング則(RoPE ベースの外挿のスケーリング則)。 この ルール を適用するだけで、RoPE 位置エンコーディングに基づく大規模モデルで外挿機能が向上します。
まず、クリティカル ディメンションとは何かを見てみましょう。
定義より、学習前テキスト長Ttrain、自注目頭寸法数d等のパラメータに関係し、具体的な計算方法は以下の通りです。 ##
このうち、10000はハイパーパラメータと回転角ベースの「初期値」です。
著者は、底面を拡大しても縮小しても、最終的に RoPE に基づく大型モデルの外挿能力を高めることができることを発見しました。大型モデルの能力は最高ですが、悪いです。
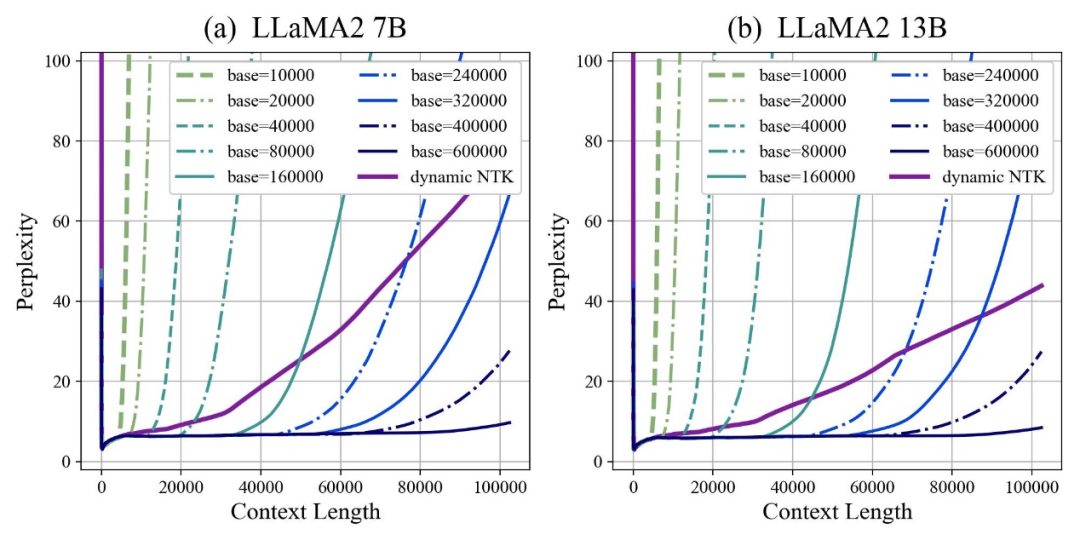
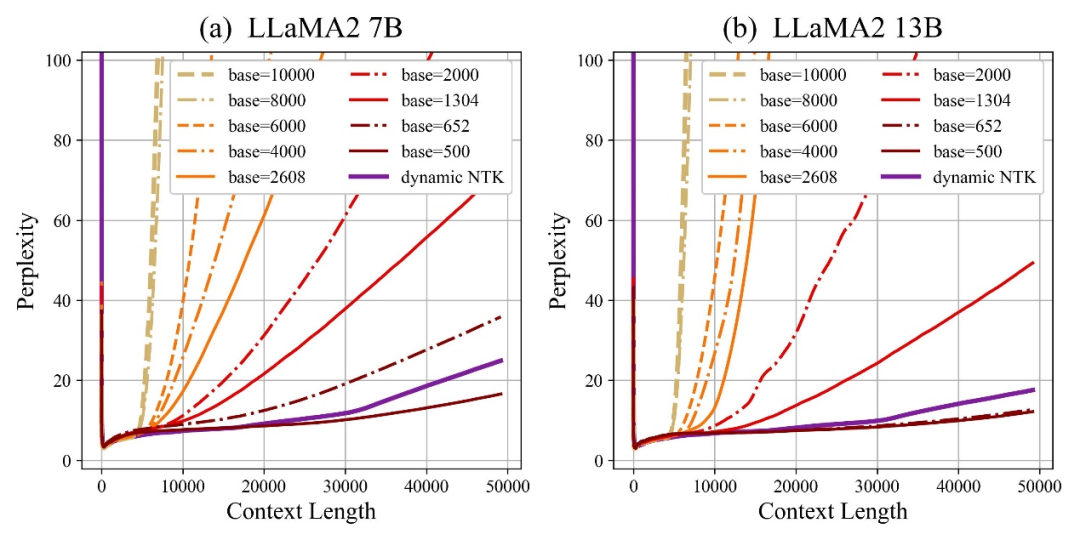
この論文では、回転角のベースが小さいほど、より多くの次元が位置情報を認識できるようになり、回転角のベースが大きいほど、より多くの次元が位置情報を認識できると考えています。より長い位置情報を表現できるようになります。
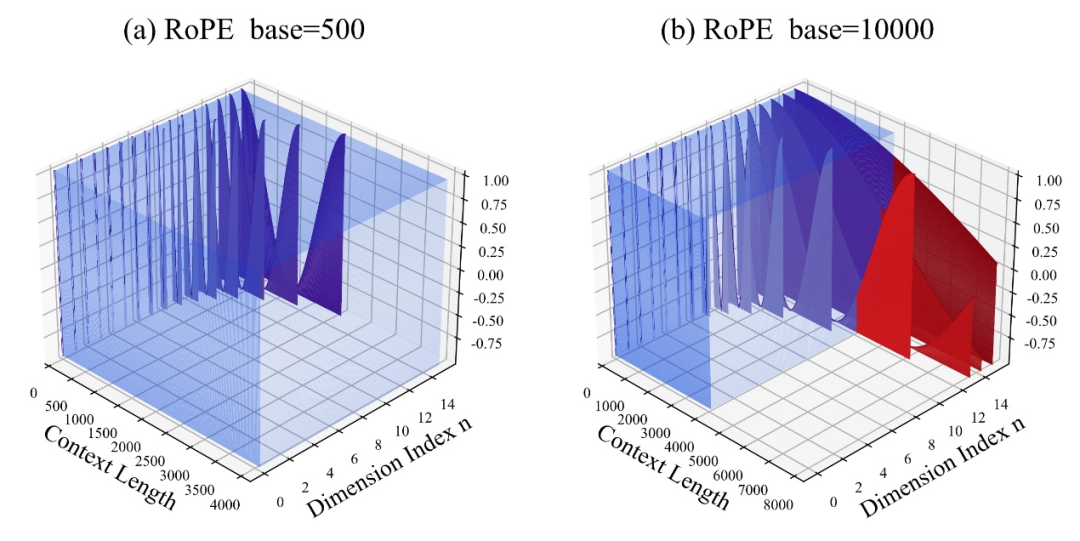
この場合、さまざまな長さの継続的なトレーニング コーパスに直面するとき、大きなコーパスの外挿能力を確保するには、回転角度ベースをどれだけ縮小および拡大する必要がありますか。モデルはどこまで最大化されますか?
この論文では、限界寸法、継続トレーニング テキストの長さ、大規模モデルのトレーニング前テキスト長などのパラメーターに関連する拡張 RoPE 外挿のスケーリング ルールを示しています。
このルールに基づいて、大規模モデルの外挿パフォーマンスは、さまざまな事前トレーニングおよび継続トレーニングのテキスト長に基づいて直接計算できます。言い換えれば、大規模モデルがサポートするコンテキスト長が予測されます。 
紙のアドレス:
https://arxiv.org/abs/2310.05209
Github リポジトリ:
https://github.com/OpenLMLab/scaling-rope
論文分析ブログ:
https://zhuanlan.zhihu.com/p/660073229
以上がLLaMA2 コンテキストの長さは 100 万トークンにまで急増し、調整する必要があるハイパーパラメータは 1 つだけです。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。