
ホームページ >テクノロジー周辺機器 >AI >Jiuzhang Yunji DataCanvas マルチモーダル大規模モデル プラットフォームの実践と考察
Jiuzhang Yunji DataCanvas マルチモーダル大規模モデル プラットフォームの実践と考察

- 王林転載
- 2023-10-20 08:45:011564ブラウズ

#1. マルチモーダル大規模モデルの歴史的発展

上の図写真は 1956 年に米国のダートマス大学で開催された第 1 回人工知能ワークショップです。この会議は人工知能分野の始まりとも考えられています。出席者は主に記号論理学の分野の先駆者でした(例外的に記号論理学)。最前列の中央)神経生物学者ピーター・ミルナー)。
しかし、この記号論理理論は長い間実現できず、最初の AI の冬期さえ 1980 年代と 1990 年代に到来しました。最近の大規模な言語モデルが実装されて初めて、ニューラル ネットワークが実際にこの論理的思考を担っていることがわかりました。神経生物学者ピーター ミルナーの研究は、その後の人工ニューラル ネットワークの開発に影響を与えました。彼が参加に招待されたのはこのためです。この学術セミナーの会議で。

2012年、テスラの自動運転担当ディレクター、アンドリュー氏は、当時のオバマ米大統領が部下たちと冗談を言っている上の写真をブログに投稿した。人工知能がこの絵を理解するには、物体を識別するだけでなく、それらの間の関係も理解する必要があるため、視覚的な認識作業だけではありません。スケールの物理原理を知ることによってのみ、図で説明されているストーリーを知ることができます。写真: オバマ氏が足を踏み入れる 体重計に乗った男性は体重が増え、他の人が笑っている中、彼はこの奇妙な表情を浮かべた。このような論理的思考は、明らかに純粋な視覚認識の範囲を超えています。したがって、「人工的な精神薄弱」の恥ずかしさを取り除くには、視覚認知と論理的思考を組み合わせる必要があります。ここ。
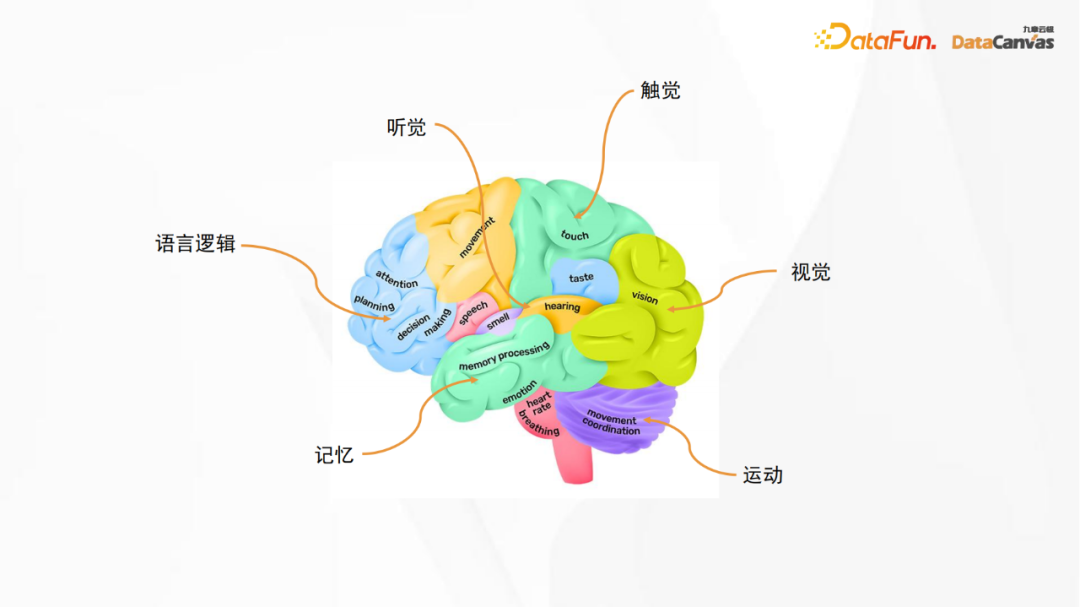
#上の図は人間の脳の解剖学的構造図です。図中の言語論理領域は大規模言語モデルに対応し、その他の領域は大規模言語モデルに対応します。それぞれの領域は、視覚、聴覚、触覚、運動、記憶などのさまざまな感覚に対応しています。人工ニューラル ネットワークは、本当の意味での脳のニューラル ネットワークではありませんが、そこから何らかのインスピレーションを得ることができ、つまり、大きなモデルを構築するときに、さまざまな機能を組み合わせることができます。これは、人工ニューラル ネットワークの基本的な考え方でもあります。マルチモーダルモデルの構築。
1. マルチモーダル大規模モデルでは何ができるのでしょうか?
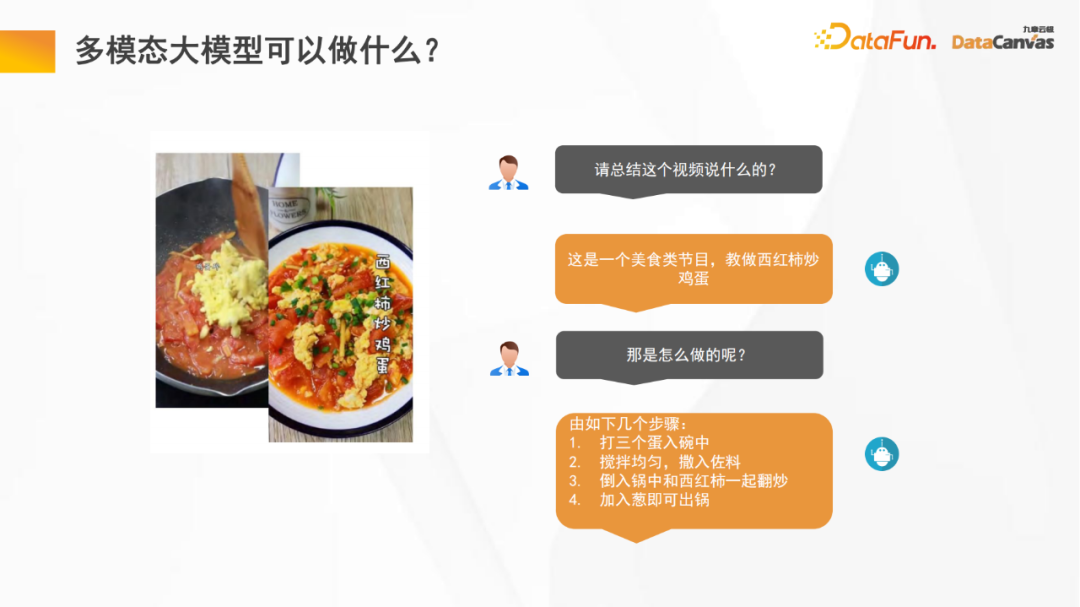
マルチモーダルな大規模モデルは、ビデオの理解など、多くのことを実現します。大規模なモデルは、概要と重要な点を要約するのに役立ちます。これにより、ビデオを視聴する時間が節約されます。大規模なモデルは、番組分類、番組視聴率統計などのビデオの事後分析を実行するのにも役立ちます。さらに、ビンセント グラフは、マルチメディアの重要な応用分野でもあります。 -モーダル大型モデル。
大規模なモデルと人やロボットの動きを組み合わせると、人間と同じように、過去の経験に基づいて最適な経路を計画する、身体化された知性が生成されます。それらを新しいシナリオに置き換えて、リスクを回避しながらこれまでに遭遇したことのない問題を解決することもできます。最終的に成功するまで、実行プロセス中に元の計画を変更することもできます。これは、幅広い可能性を秘めた応用シナリオでもあります。
2. マルチモーダル大規模モデル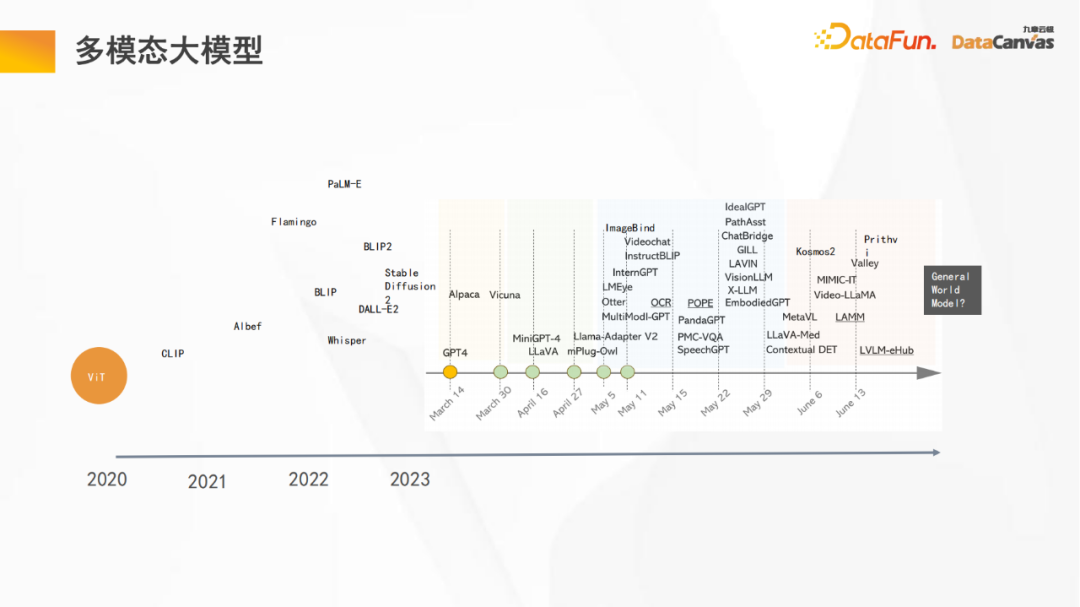
上の図は、マルチモーダル大規模モデルの開発プロセスにおけるいくつかの重要なノードです。モデル :######
- 2020 ViT モデル (Vision Transformer) は大規模モデルの始まりであり、Transformer アーキテクチャは初めて、データに加えて他のタイプのデータ (ビジュアル データ) にも使用されます。言語と論理処理を組み合わせて表示されます 優れた汎化能力を持っています;
- そして、OpenAI オープンソース CLIP モデルを通じて、 ViT と大規模な言語モデルの使用により、視覚的なタスクが大幅に達成されました 強力なロングテール一般化能力、つまり、これまで目に見えなかったカテゴリーを常識を通じて推論します。 #2023 年までに、PaLM-E (ロボット)、ウィスパー (音声認識)、ImageBind (画像位置合わせ)、Sam (セマンティック セグメンテーション)、そして最終的には地理的画像に至るまで、さまざまなマルチモーダル大規模モデルが徐々に出現; Microsoft の統合マルチモーダル アーキテクチャ Kosmos2 も含まれており、マルチモーダル大規模モデルが急速に開発されています。
- # テスラはまた、6 月の CVPR でユニバーサル世界モデルのビジョンを提案しました。
- 上の図からわかるように、わずか半年の間に大規模なモデルには多くの変更が加えられており、その反復速度は非常に高速です。
#3. モーダル アライメント アーキテクチャ
上の図は複数のモーダル 大規模な状態モデルの一般的なアーキテクチャ図には、言語モデルとビジュアル モデルが含まれます。アライメント モデルは、固定言語モデルと固定ビジュアル モデルを通じて学習されます。アライメントは、ビジュアル モデルのベクトル空間とベクトルを結合することです。言語モデルの空間、そして言語モデル間の内部論理関係の理解は、統一されたベクトル空間で完了します。
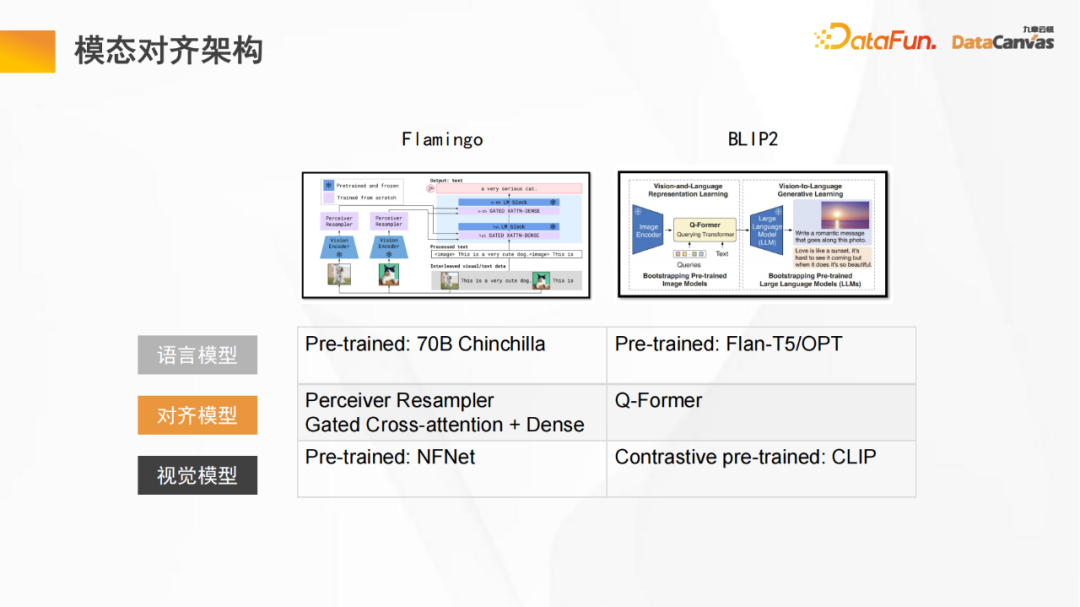 この図に示されている Flamingo モデルと BLIP2 モデルはどちらも同様の構造を採用しています (Flamingo モデルは Perceiver アーキテクチャを使用し、BLIP2 モデルは Transformer アーキテクチャの改良版を使用しています)。この学習方法では、事前トレーニングを実行し、多数のトークンに対して大量の学習を実行し、より良い位置合わせ効果を得ることができ、最終的には特定のタスクに応じてモデルを微調整します。
この図に示されている Flamingo モデルと BLIP2 モデルはどちらも同様の構造を採用しています (Flamingo モデルは Perceiver アーキテクチャを使用し、BLIP2 モデルは Transformer アーキテクチャの改良版を使用しています)。この学習方法では、事前トレーニングを実行し、多数のトークンに対して大量の学習を実行し、より良い位置合わせ効果を得ることができ、最終的には特定のタスクに応じてモデルを微調整します。
2. Jiuzhang Yunji DataCanvas のマルチモーダル大規模モデル プラットフォーム
1. AI Foundation ソフトウェア (AIFS)
#Jiuzhang Yunji DataCanvas は、人工知能の基本ソフトウェア プロバイダーです。また、コンピューティング リソース (GPU クラスターを含む) を提供し、高性能ストレージとネットワークの最適化を実行し、これに基づいて大規模なモデルのトレーニングを提供します。データを含むツールアノテーションモデリング実験サンドボックスなどJiuzhang Yunji DataCanvas は、市場で一般的なオープンソースの大規模モデルをサポートするだけでなく、Yuanshi マルチモーダル大規模モデルも独自に開発します。アプリケーション層では、プロンプトワードを管理し、モデルを微調整し、モデルの運用および保守メカニズムを提供するためのツールが提供されます。同時に、基本的なソフトウェア アーキテクチャを強化するために、マルチモーダル ベクトル データベースもオープンソース化されました。
2. モデル ツール LMOPS
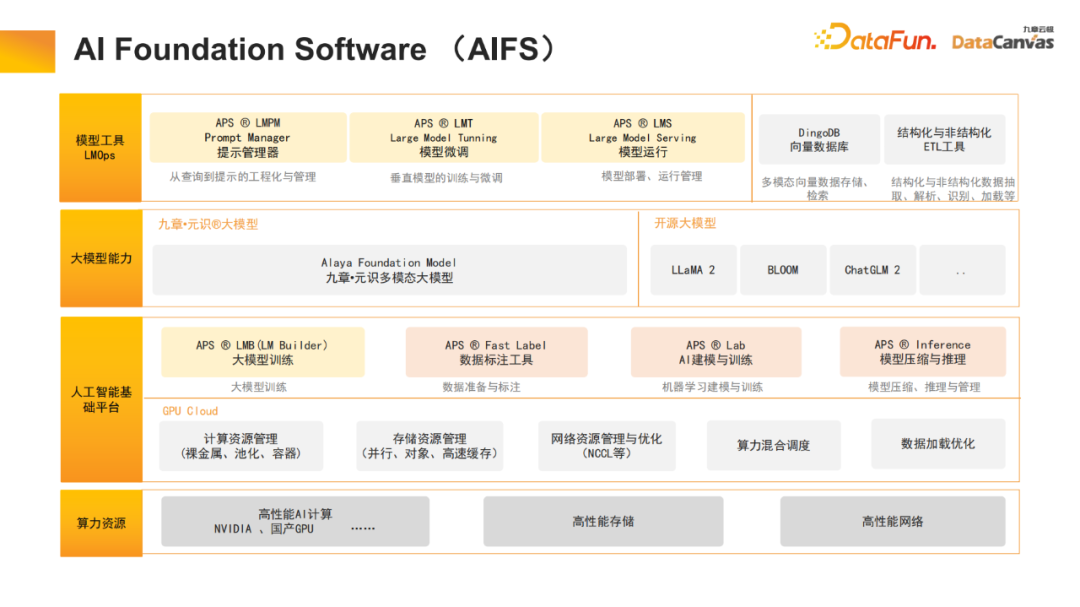
九章云Ji DataCanvas は、データ準備 (データ アノテーションは手動アノテーションとインテリジェント アノテーションをサポート)、モデル開発、モデル評価 (水平および垂直評価を含む)、モデル推論 (モデルの定量化、知識の蒸留をサポート) を含む、開発のライフ サイクル全体の最適化に焦点を当てています。 、などの高速推論メカニズム)、モデルの適用など。
3. LMB – 大規模モデル ビルダー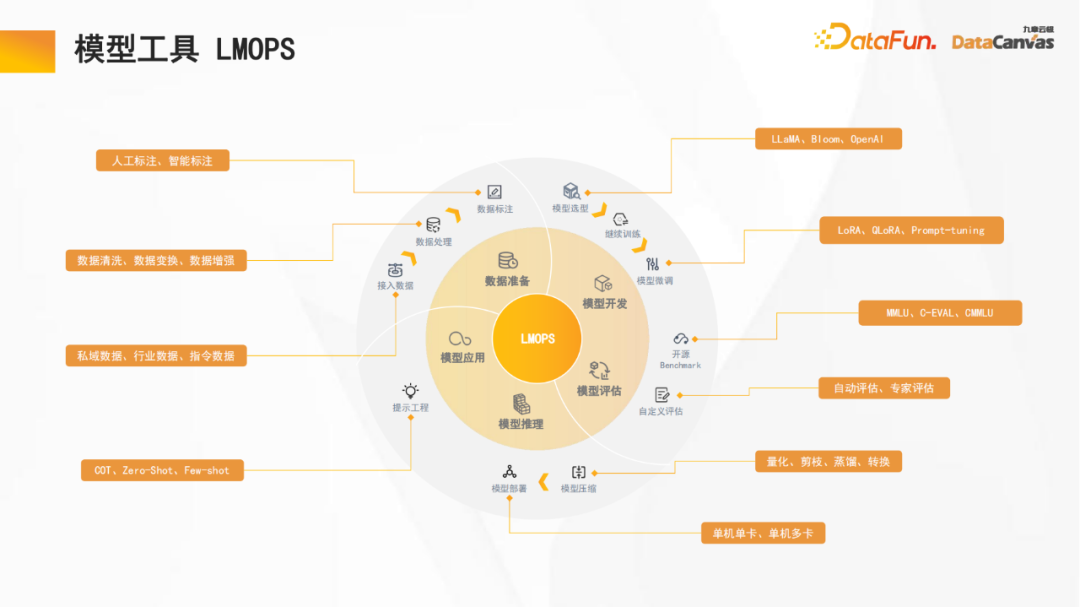
モデルを構築するとき、多くの分散型モデルが効率的データ並列処理、Tensor 並列処理、パイプライン並列処理などの最適化作業。これらの分散最適化タスクはワンクリックで完了し、視覚的な制御をサポートするため、人件費を大幅に削減し、開発効率を向上させることができます。
4. LMB – 大規模モデル ビルダー
一般的な継続トレーニング、スーパーバイザーのチューニング、強化学習における人間によるフィードバックなど、大規模モデルのチューニングも最適化されています。さらに、中国語の語彙の自動拡張など、中国語用に多くの最適化が行われています。多くの中国語単語は大規模なオープン ソース モデルに含まれていないため、これらの単語は複数のトークンに分割される可能性があり、これらの単語を自動的に拡張することで、モデルがこれらの単語をより適切に使用できるようになります。
5. LMS – 大規模モデルの提供
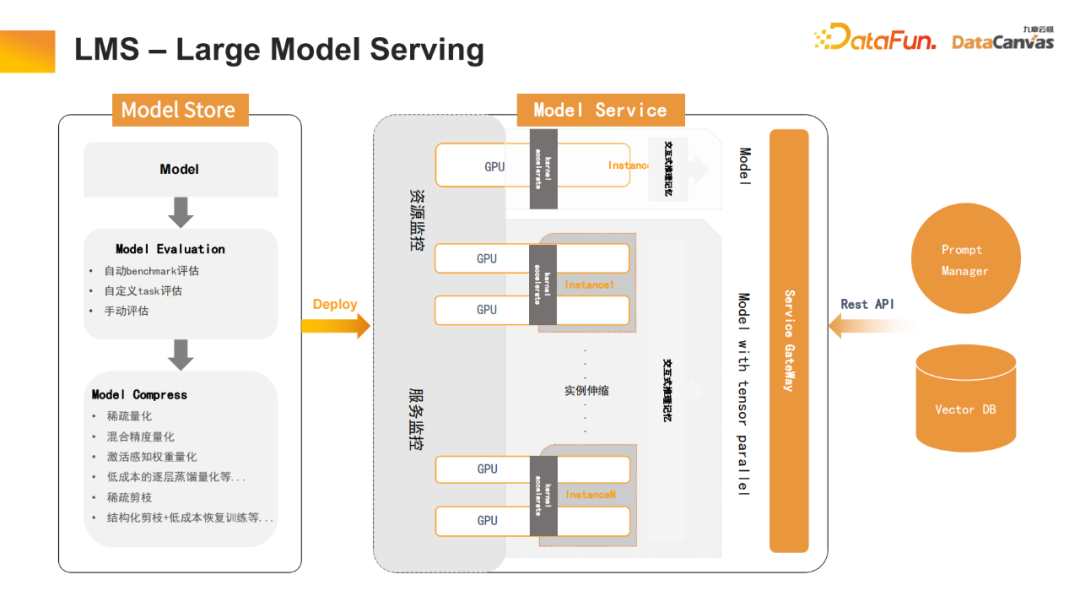
大規模モデルの提供も非常に重要なコンポーネントですこのプラットフォームでは、モデルの定量化や知識の蒸留などの面で多くの最適化が行われ、計算コストが大幅に削減され、トランスフォーマーが高速化され、レイヤーごとの知識の蒸留によって計算量が削減されています。同時に、多くの枝刈り作業 (構造化枝刈り、疎枝刈りなど) が行われ、大規模モデルの推論速度が大幅に向上しました。
さらに、インタラクティブな対話プロセスも最適化されました。たとえば、複数ターンのダイアログ Transformer では、各テンソルのキーと値を計算を繰り返すことなく記憶できます。したがって、Vector DB に保存することで会話履歴の記憶機能を実現し、対話プロセス中のユーザー エクスペリエンスを向上させることができます。
6. プロンプト マネージャー
プロンプト マネージャーは、大規模なモデルのプロンプト ワード設計および構築ツールであり、ユーザーがより適切なプロンプト ワードを設計し、大規模なモデルをガイドするのに役立ちます。モデルは、より正確で信頼性の高い、期待どおりの出力を生成します。このツールは、技術者向けに開発ツールキット開発モードを提供するだけでなく、非技術者向けに人間とコンピュータの対話操作モードも提供し、大規模モデルを使用するさまざまなグループのニーズに対応します。
その主な機能には、AI モデル管理、シーン管理、プロンプト ワード テンプレート管理、プロンプト ワード開発、プロンプト ワード アプリケーションなどが含まれます。

#プラットフォームは、バージョン管理を実現するために一般的に使用されるプロンプト ワード管理ツールを提供し、プロンプト ワードの実装を迅速化するために一般的に使用されるテンプレートを提供します。
3. Jiuzhang Yunji DataCanvas マルチモーダル大規模モデルの実践
1. マルチモーダル大規模モデル - メモリ付き
#プラットフォームの機能を紹介した後、マルチモーダル大規模モデル開発の実践を共有します。
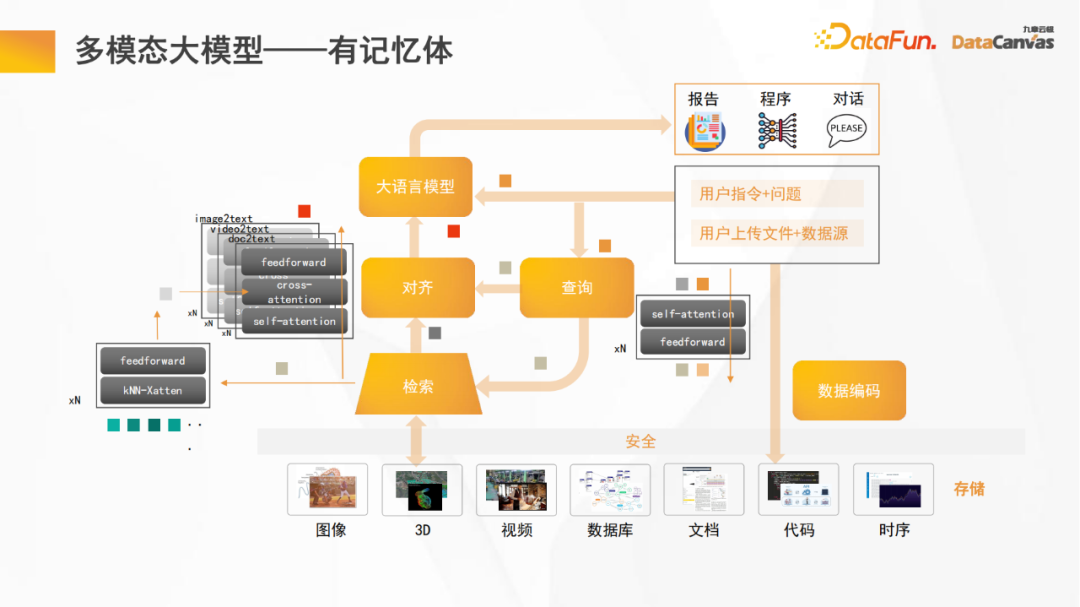
一般に、大規模なオープンソース モデルはパラメータの数が比較的少ないため、パラメータの一部がメモリに使用されると、推論能力が大幅に低下します。大規模なオープンソース モデルにメモリを追加すると、推論機能とメモリ機能が同時に向上します。
さらに、ほとんどのモデルと同様に、マルチモーダル大規模モデルも大規模言語モデルと固定データ エンコーディングを修正し、アライメント関数の個別のモジュール トレーニングを実行します。データ モードはテキストの論理部分に合わせて調整されます。推論プロセスでは、言語が最初に翻訳され、次に融合され、最後に推論作業が実行されます。
2. 非構造化データ ETL パイプライン
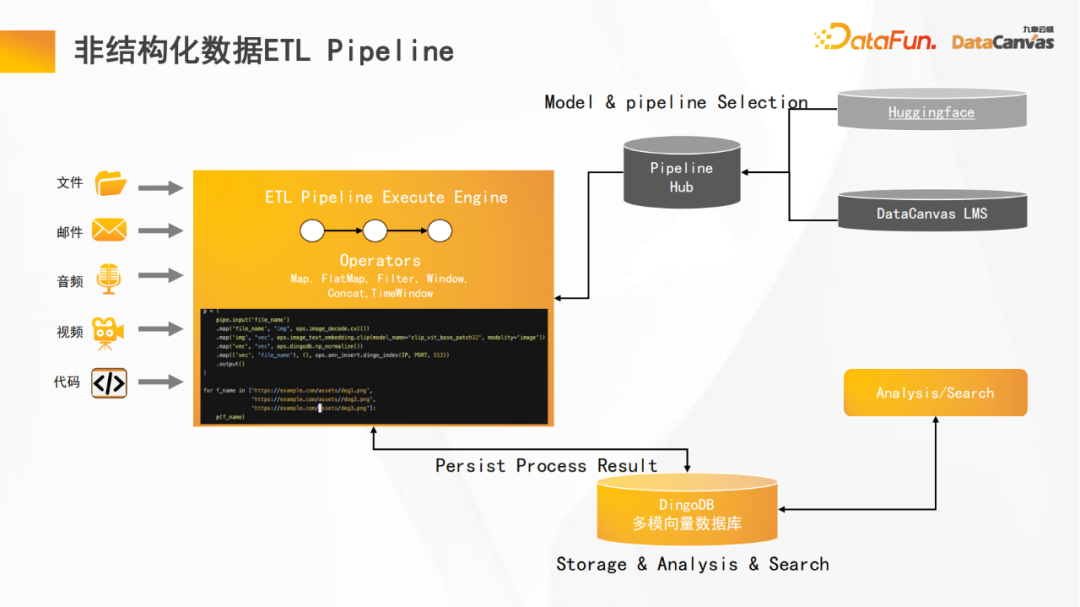
さらに、このプラットフォームは、最も効率的な開発エクスペリエンスを実現するためにパイプラインを再利用できるハブを提供します。同時に、Huggingface 上の多くのエンコーダーをサポートしており、さまざまなモーダル データの最適なエンコードを実現できます。
3. マルチモーダル大規模モデルの構築方法
Jiuzhang Yunji DataCanvas は、ユーザーをサポートするベースとして Yuanshi マルチモーダル大規模モデルを使用します。他のオープンソースの大規模モデルを選択でき、ユーザーがトレーニングに独自のモーダル データを使用できるようにすることもできます。
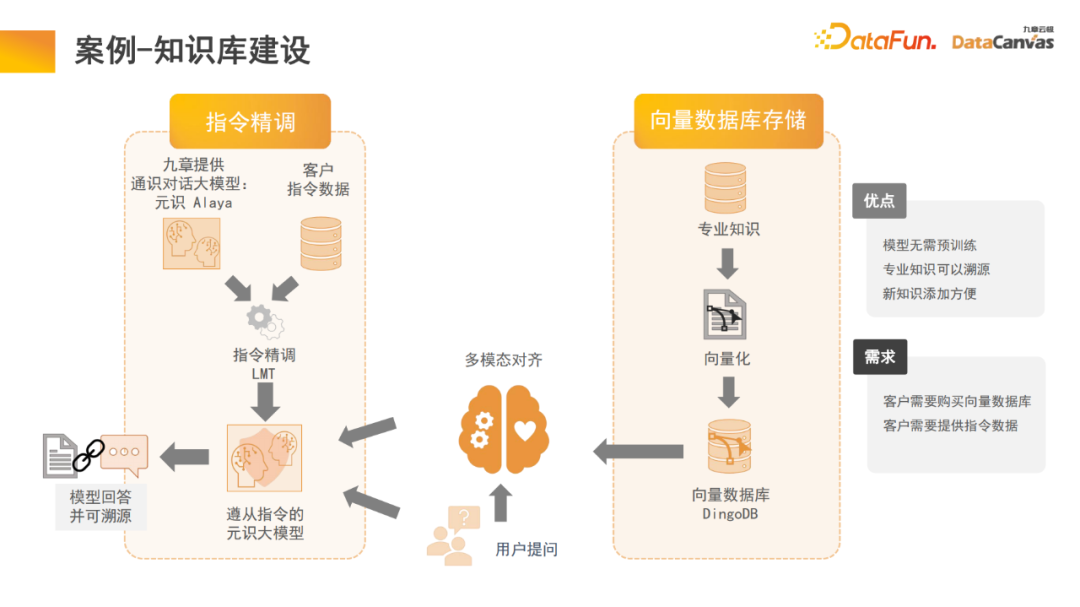
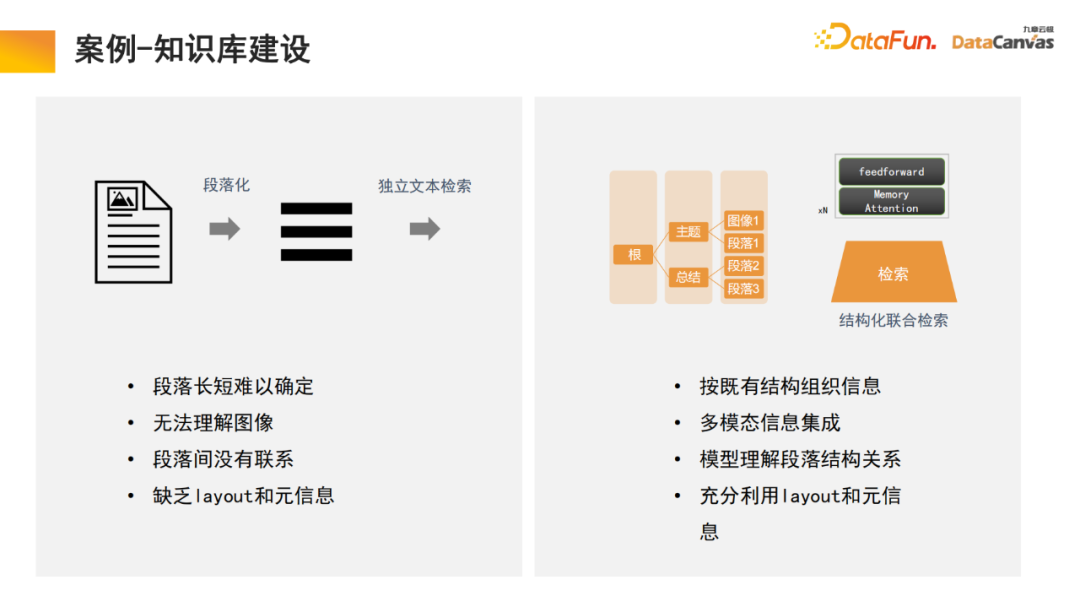
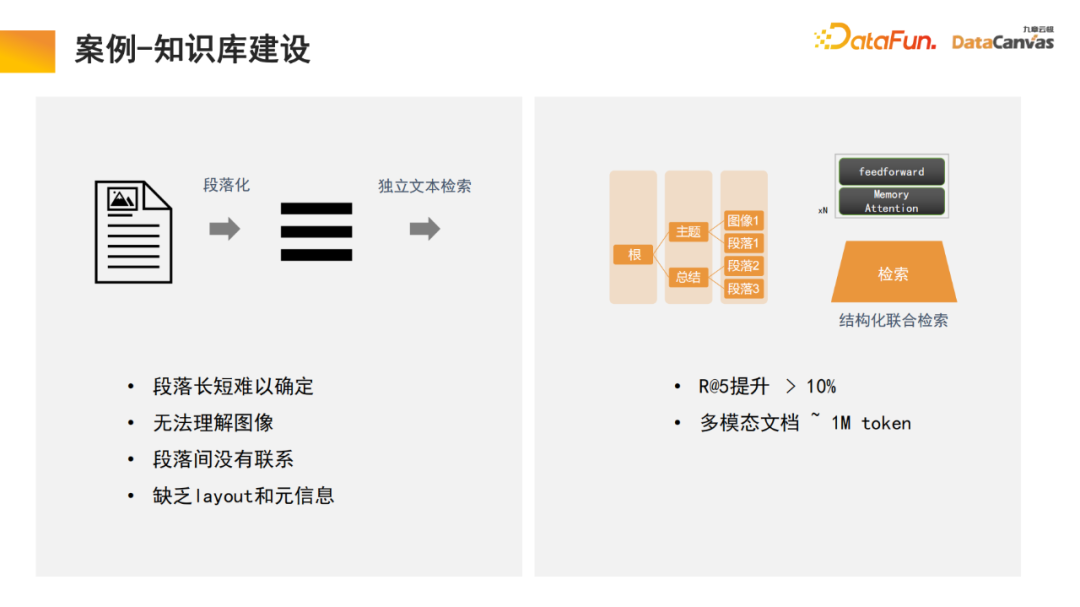
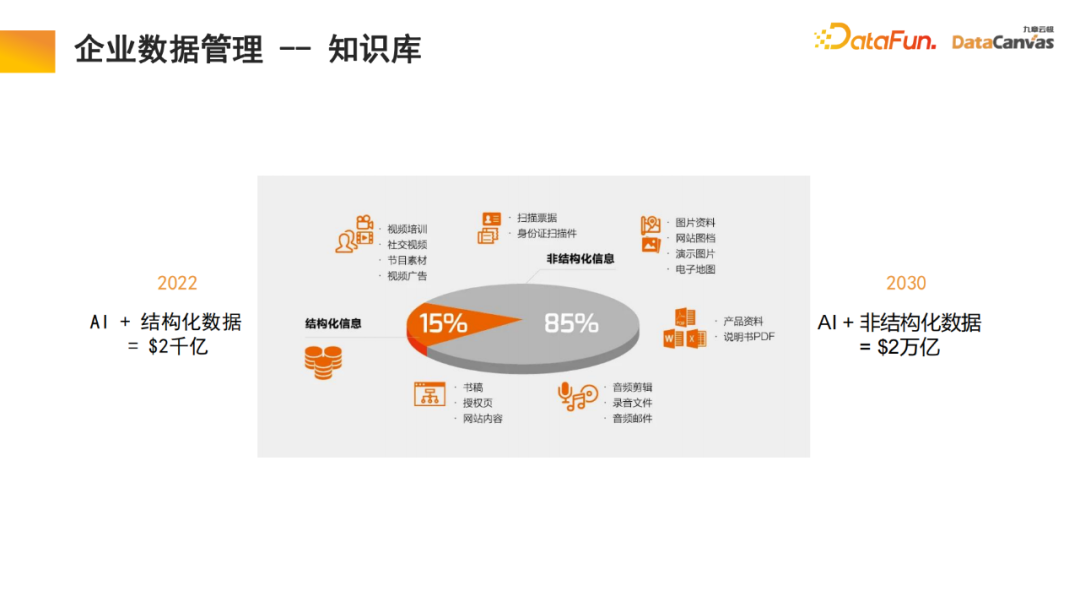
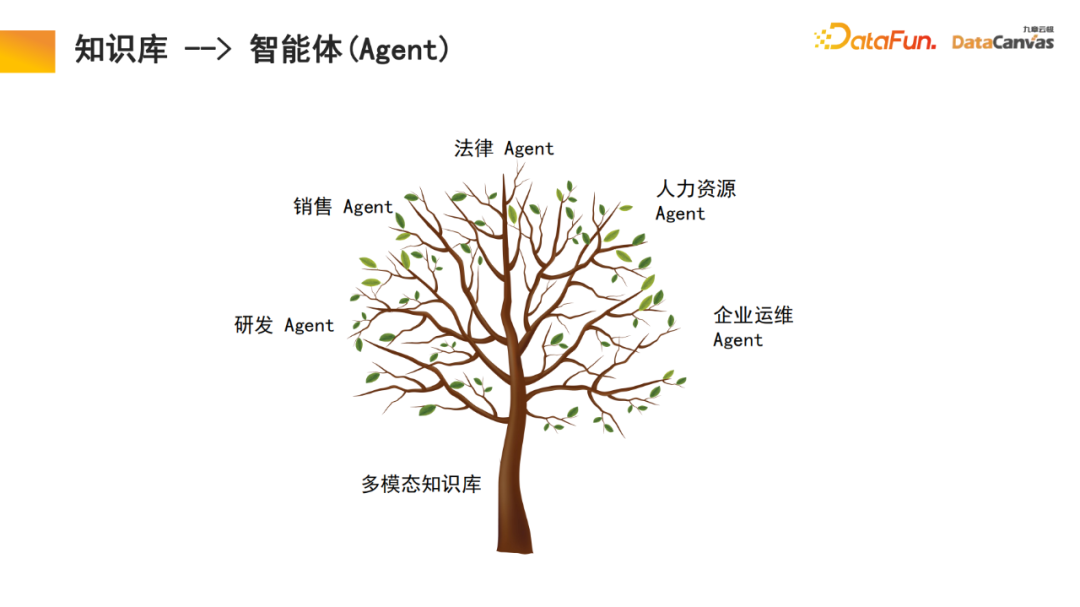
大規模なマルチモーダル モデルの構築は、大きく 3 つの段階に分かれています。 大規模モデルのメモリ アーキテクチャは、実際にはモデルのアプリケーションであるマルチモーダルな知識ベースの構築を実現するのに役立ちます。 Zhihu は典型的なマルチモーダル知識ベース アプリケーション モジュールであり、その専門知識を追跡できます。 知識の確実性と安全性を確保するには、多くの場合、専門知識の源を追跡する必要があります。ナレッジ ベースは、この機能を実現するのに役立ちます。新しい知識を追加する方が便利です。モデル パラメーターを変更する必要はなく、知識をデータベースに直接追加するだけです。 具体的には、エンコーダを通じて専門的な知識を活用してエンコードを選択すると同時に、異なる評価方法に基づいて統一的な評価を行い、エンコーダの選択を行います。ワンクリック評価で実現。最後に、エンコーダのベクトル化が適用されて DingoDB マルチモーダル ベクトル データベースに保存され、大規模モデルのマルチモーダル モジュールを通じて関連情報が抽出され、言語モデルを通じて推論が実行されます。 モデルの最後の部分では、多くの場合、命令の微調整が必要になります。ユーザーごとにニーズが異なるため、マルチモーダル大規模モデル全体を微調整する必要があります。情報の整理におけるマルチモーダル知識ベースの特別な利点により、モデルには学習と検索の機能があり、これはテキストの段落化のプロセスで行われた革新でもあります。 一般的なナレッジ ベースは、ドキュメントを段落に分割し、各段落のロックを個別に解除することです。この方法はノイズの影響を受けやすく、多くの大きな文書では段落分割の基準を決定することが困難です。 私たちのモデルでは、検索モジュールが学習を実行し、モデルは適切な構造化情報組織を自動的に見つけます。特定の製品については、製品マニュアルから始めて、最初にカタログの大きな段落を見つけてから、特定の段落を見つけます。同時に、マルチモーダル情報の統合により、テキストに加えて画像や表などが含まれることも多く、これらもベクトル化してメタ情報と組み合わせて共同検索を実現することができるため、検索効率が向上します。 取得モジュールはメモリ アテンション メカニズムを使用しており、同様のアルゴリズムと比較して再現率を 10% 高めることができると同時に、メモリ アテンション メカニズムにより、マルチモーダルなドキュメント処理に使用できることも、非常に有利な点です。 企業内のデータの 85% は非構造化データであり、構造化データは 15% のみです。過去 20 年間、人工知能は主に構造化データを中心に展開してきましたが、非構造化データは活用が非常に難しく、構造化データに変換するには多大なエネルギーとコストが必要です。マルチモーダルな大規模モデルとマルチモーダルな知識ベースの助けを借りて、そして人工知能の新しいパラダイムを通じて、企業の内部管理における非構造化データの利用を大幅に改善することができ、それによってデータの利用量が 10 倍に増加する可能性があります。将来の価値。 マルチモーダル ナレッジ ベース インテリジェントな知識の基盤としてエージェントに加えて、研究開発エージェント、顧客サービスエージェント、販売エージェント、法務エージェント、人事エージェント、企業運用保守エージェントなどの上記の機能はすべてナレッジベースを通じて操作できます。 営業エージェントを例に挙げると、一般的なアーキテクチャには 2 つのエージェントが同時に存在し、1 人が意思決定を担当し、もう 1 人が販売段階の分析を担当します。どちらのモジュールも、製品情報、過去の販売統計、顧客像、過去の販売経験などを含む、マルチモーダルなナレッジ ベースを通じて関連情報を検索できます。この情報は、これら 2 つのエージェントが最善かつ最も正確な作業を行うのに役立つように統合されています。次に、ユーザーが最適な販売情報を入手できるように支援し、それがマルチモーダル データベースに記録されるというこのサイクルにより、販売実績が継続的に向上します。 私たちは、将来最も価値のある企業は、インテリジェンスを実践する企業になると信じています。 Jiuzhang Yunji DataCanvas がずっとあなたに同行し、お互いに助け合えることを願っています。
#4. 事例知識ベースの構築
##4. 感想と今後の展望
1 . エンタープライズ データ管理 - ナレッジ ベース
2. ナレッジ ベース --> エージェント
以上がJiuzhang Yunji DataCanvas マルチモーダル大規模モデル プラットフォームの実践と考察の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。