
ホームページ >テクノロジー周辺機器 >AI >1 トークンで LLM デジタル コーディングの問題が解決します。主要9機関が共同リリースしたxVal:トレーニングセットに含まれない数値も予測可能!
1 トークンで LLM デジタル コーディングの問題が解決します。主要9機関が共同リリースしたxVal:トレーニングセットに含まれない数値も予測可能!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-10-19 14:25:011033ブラウズ
大規模言語モデル (LLM) のパフォーマンスは、テキスト分析および生成タスクでは非常に強力ですが、複数桁の乗算などの数値を含む問題に直面した場合、統一された完全な数値が内部に存在しないため、モデル 単語分割メカニズムにより、LLM は数値の意味を理解できなくなり、ランダムな回答を作成できなくなります。
現在、LLM が科学分野のデータ分析に広く使用されていない大きな障害の 1 つは、デジタル エンコーディングの問題です。
最近、フラットアイアン研究所、ローレンス・バークレー国立研究所、ケンブリッジ大学、ニューヨーク大学、プリンストン大学を含む9つの研究機関が共同で、たった1つのトークンである新しいデジタル符号化スキームxValをリリースしました。すべての数値をエンコードするために必要です。

論文リンク: https://arxiv.org/pdf/2310.02989.pdf
xVal xVal 戦略は、ターゲットの真の値を表す専用トークン ([NUM]) の埋め込みベクトルを数値的にスケーリングし、修正された数値推論方法と組み合わせることで、モデルを入力文字列数値から出力数値にエンドツーエンドでマッピングできるようにします。連続的で、科学分野でのアプリケーションにより適しています。
合成データセットと現実世界のデータセットの評価結果は、xVal が既存の数値エンコード スキームよりも優れたパフォーマンスとトークン効率を実現するだけでなく、より優れた内挿も示すことを示しています。
デジタル エンコーディングにおける新たなブレークスルー
標準の LLM 単語分割スキームでは数値とテキストが区別されないため、値を定量化することは不可能です。
これまでの研究では、10 を基数として使用したり、数値の埋め込み間で計算したりして、科学表記法の形式ですべての数値を限られたプロトタイプ数値のセットにマッピングしました。数値自体の数値的な違いを反映しており、行列の乗算などの線形代数の問題を解決するためにうまく使用されています。
ただし、科学分野の連続問題や滑らかな問題の場合、言語モデルは依然として補間問題や分布外汎化問題をうまく処理できません。これは、数値をテキストにエンコードした後、LLM が処理するためです。そして、デコード段階は依然として本質的に離散的であり、連続関数を近似する方法を学習するのは困難です。
xVal のアイデアは、数値サイズを乗算的にエンコードし、埋め込み空間で学習可能な方向に向けることで、Transformer アーキテクチャの処理と解釈を大幅に変更します。
xVal は数値エンコードに単一のトークンを使用します。これには、トークンの効率性と語彙のフットプリントが最小限に抑えられるという利点があります。
修正された数値推論パラダイムと組み合わせると、入力数値と出力文字列数値の間のマッピングが連続 (滑らか) であり、近似関数が連続である場合、Transformer モデルの値は連続 (滑らか) になります。あるいは、平滑化により誘導バイアスを改善することもできます。
xVal: 連続数値エンコーディング
xVal は、異なる数値に対して異なるトークンを使用せず、埋め込み空間内の特定の学習可能な方向に沿って値を直接埋め込みます。
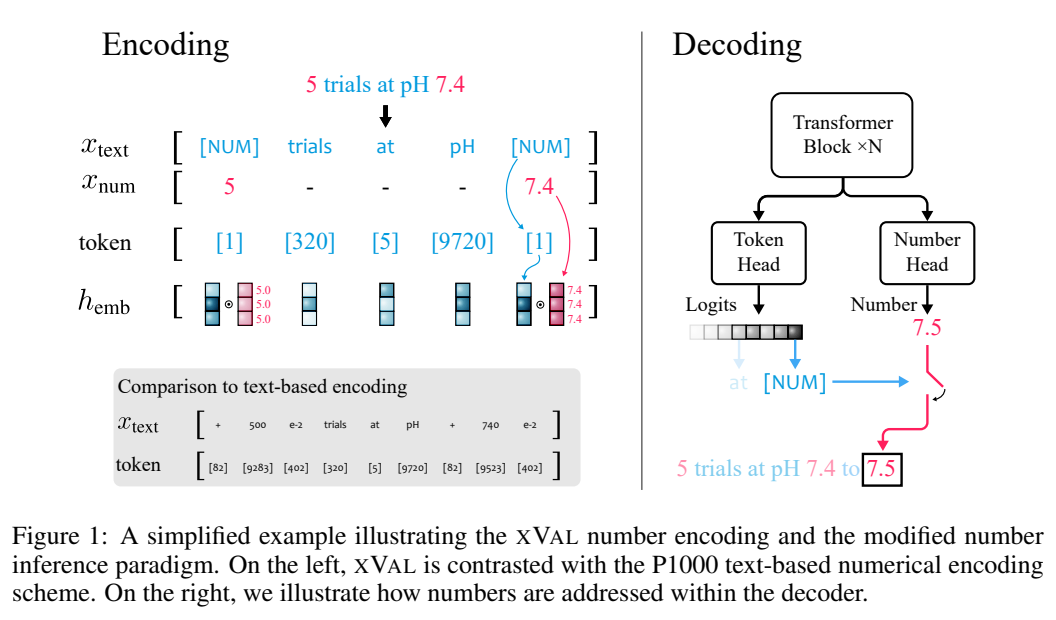
入力文字列に数値とテキストの両方が含まれていると仮定すると、システムはまず入力を解析し、すべての値を抽出してから、A を構築します。数値が [NUM] プレースホルダーで置き換えられ、[NUM] の埋め込みベクトルが対応する数値で乗算された新しい文字列。
エンコード プロセス全体は、マスク言語モデリング (MLM) および自己回帰 (AR) 生成に使用できます。
層正規化に基づく層ノルムによる暗黙的な正規化
特定の実装では、最初に各 Transformer ブロックに xVal を乗算埋め込んだ後、入力サンプルに基づいて各トークンの埋め込みを正規化するには、位置エンコード ベクトルとレイヤー正規化 (レイヤー ノルム) を追加する必要があります。
位置の埋め込みが [NUM] タグの埋め込みと同一線上にない場合、スカラー値を非線形再スケーリング関数 (非線形再スケーリング) に渡すことができます。
u は [NUM] の埋め込み、p は位置の埋め込み、x はエンコードされたスカラー値であると仮定します。計算を簡素化するために、u · p=0 と仮定できます。 ∥u∥ =∥p∥ = 1 の場合、
を取得できます。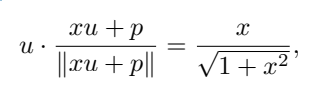
つまり、x の値は u と同じ方向にエンコードされ、この属性はトレーニング後も維持できます。
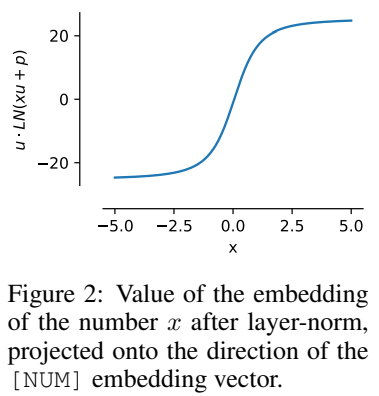
この正規化特性は、xVal のダイナミック レンジが他のテキストベースのエンコーディング スキームのダイナミック レンジよりも小さいことを意味します。 -5, 5] をトレーニング前の前処理ステップとして使用します。
数値推論
xVal は入力値への連続埋め込みを定義しますが、多分類タスクが出力およびトレーニング アルゴリズムとして使用される場合は、入力値と出力値の間のマッピングでは、モデル全体がエンドツーエンド連続ではないため、数値は出力層で個別に処理する必要があります。
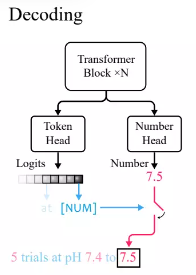
Transformer 言語モデルの標準的な実践に従って、研究者たちは語彙トークンの確率分布を出力するトークンヘッドを定義しました。
xVal は [NUM] を使用して数値を置き換えるため、ヘッドには数値に関する情報が含まれないため、平均値を介してスカラー出力を持つ新しい数値ヘッドを導入する必要があります。二乗誤差 (MSE) 損失は、[NUM] に関連付けられた特定の数値を回復するようにトレーニングされます。
入力を与えた後、まずトークンの先頭の出力を観察します。生成されたトークンが [NUM] の場合は、数字の先頭を見てトークンの値を入力します。
実験では、Transformer モデルは値を推論するときにエンドツーエンドで連続的であるため、目に見えない値を補間するときにパフォーマンスが向上します。
実験部分
他のデジタル符号化方式との比較
研究者らは、次のようなパフォーマンスを比較しました。 XVAL と他の 4 つのデジタル エンコーディングを比較しました。これらのメソッドはすべて、最初に数値を ±ddd E±d の形式に処理し、次に形式に従って 1 つまたは複数のトークンを呼び出してエンコーディングを決定する必要があります。

メソッドが異なると、各数値をエンコードするために必要なトークンと語彙の数が大きく異なりますが、全体としては、xVal のエンコード効率が最も高く、語彙も豊富です。サイズは一番小さいです。
研究者らはまた、合成算術演算データ、地球温度データ、惑星軌道シミュレーション データを含む 3 つのデータセットで xVal を評価しました。
算術の学習
最大規模の LLM であっても、「複数桁の乗算」は依然として非常に困難なタスクです。 GPT-4 などのゼロショット精度は、3 桁の乗算問題で 59% しか達成できず、4 桁および 5 桁の乗算問題でさえ 4% と 0% の精度しか達成できません。
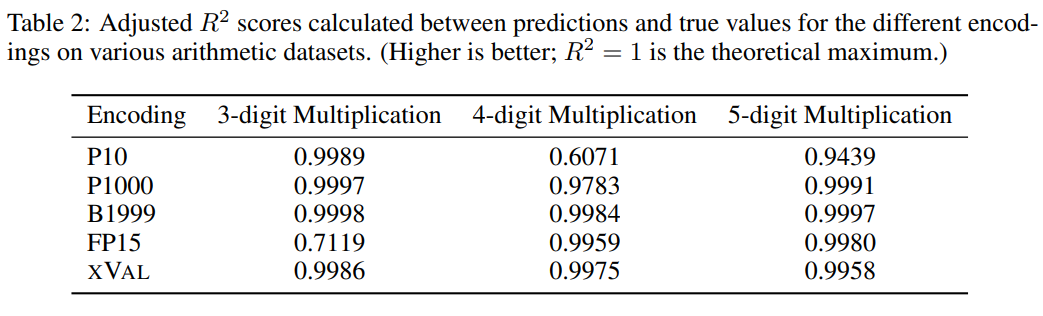
タスクの難易度を改善するために、研究者らはランダムな二分木を使用して、加算、減算、および加算の二項演算子を使用して固定数のオペランド (2、3、または 4) を構築しました。乗算: 各サンプルが ((1.32 * 32.1) (1.42-8.20)) = 35.592
のような算術式であり、各数値のエンコード スキームに基づくデータ セット。処理にはサンプルの処理が必要で、タスクの目標は方程式の左側の式、つまり方程式の右側がマスクである式を計算することです。
結果から判断すると、xVal はこのタスクで非常にうまく機能しましたが、算術実験だけでは言語モデルの数学的機能を完全に評価するには十分ではありません。これは、算術演算のサンプルは通常短いシーケンスであり、その基礎となるものであるためです。データ フロー 形状が低次元であるため、これらの問題は LLM の計算ボトルネックを突破できず、現実世界のアプリケーションはより複雑です。
気温予測
研究者らは、ERA5 地球規模気候データセットのサブセットを使用しました。評価では、簡単にするために、実験では表面温度データ (ERA5 の T2m) のみに焦点を当て、サンプルを分割します。各サンプルには 2 ~ 4 日の表面温度データ (正規化後の単位分散あり) と 60 日分のデータが含まれます。 - ランダムに選択された 90 個のレポートステーションの緯度と経度。
緯度のサインと経度のサインとコサインをエンコードして、データの周期性を維持し、同じ操作を使用して位置をエンコードします。 24 時間 365 日の期間。

座標、開始およびデータは、レポート ステーションの座標、最初のサンプルの時間、および正規化された温度データに対応し、MLM メソッドを使用してトレーニングします。言語モデル。
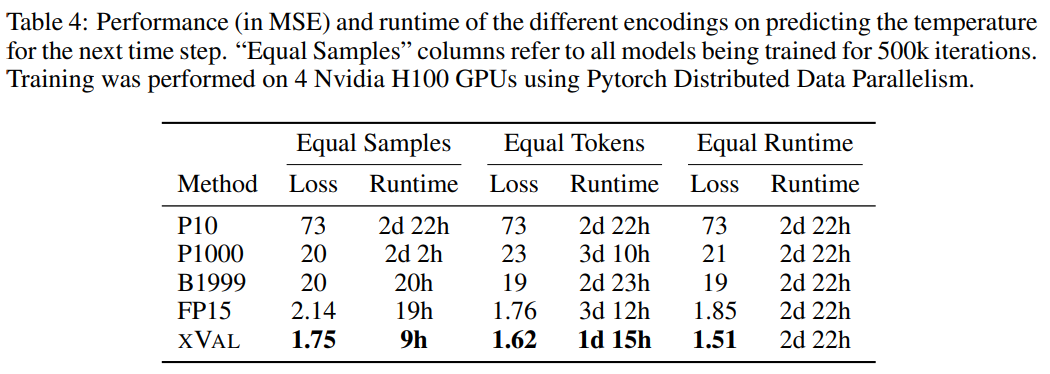
結果から、xVal が最高のパフォーマンスを示し、計算時間も大幅に短縮されました。
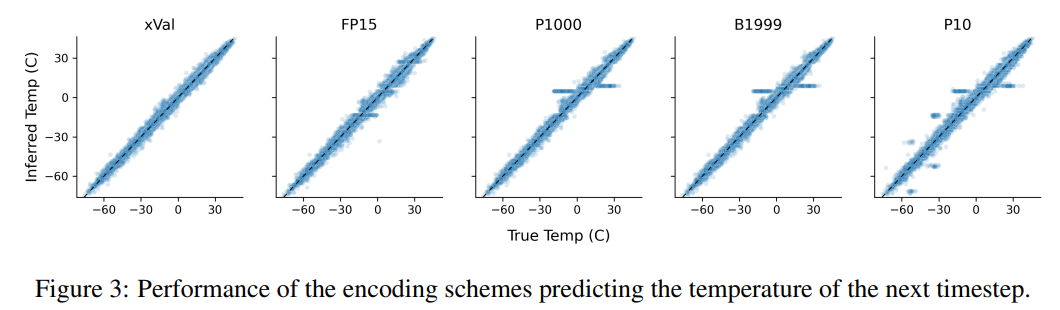
このタスクでは、テキスト ベースのエンコード スキームの欠点も説明します。モデルは、データ内の偽の相関、つまり P10、P1000、および P1000 を悪用する可能性があります。 B1999 正規化温度 ±0.1 を予測する傾向があります。これは主に、この数値がデータセット内で最も頻繁に現れるためです。
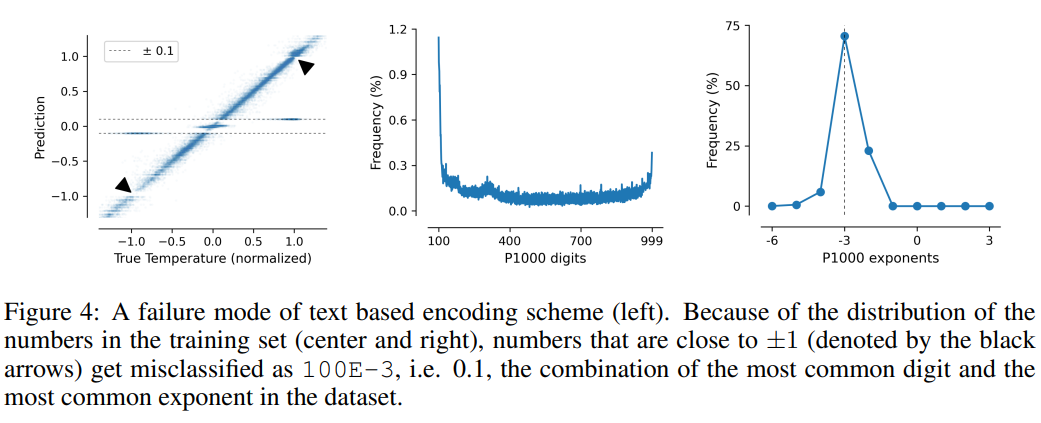
P1000 スキームと P10 スキームの場合、2 つのスキームの平均エンコード出力はそれぞれ約 8000 トークンと 5000 トークンです (比較すると、FP15 と xVal平均約 1800 トークン)、モデルのパフォーマンスの低下は、長距離モデリングの問題が原因である可能性があります。
以上が1 トークンで LLM デジタル コーディングの問題が解決します。主要9機関が共同リリースしたxVal:トレーニングセットに含まれない数値も予測可能!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。