
ホームページ >テクノロジー周辺機器 >AI >言語、ロボット破壊、MIT などは GPT-4 を使用してシミュレーション タスクを生成し、現実世界に移行します。
言語、ロボット破壊、MIT などは GPT-4 を使用してシミュレーション タスクを生成し、現実世界に移行します。

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-10-16 20:21:03963ブラウズ
コンテンツを次のように書き換えました: Machine Heart Report
編集者: Du Wei、Xiaozhou
GPT-4 とロボットが新たな火種を生み出しました。

ロボット工学の分野では、普遍的なロボット戦略の実装には大量のデータが必要であり、現実世界でこのデータを収集するのは時間と労力がかかります。シミュレーションは、シーン レベルおよびインスタンス レベルでさまざまな量のデータを生成するための経済的なソリューションを提供しますが、シミュレートされた環境でタスクの多様性を高めるには、依然として大量の人員が必要となるため (特に複雑なタスクの場合) 課題に直面しています。その結果、典型的な人工シミュレーション ベンチマークには、通常、数十から数百のタスクしか含まれていません。
どうすれば解決できますか?近年、大規模な言語モデルは、さまざまなタスクの自然言語処理とコード生成において大幅な進歩を続けています。同様に、LLM は、ユーザー インターフェイス、タスクと動作計画、ロボット ログの概要、コストと報酬の設計など、ロボット工学のさまざまな側面に適用されており、物理ベースのタスクとコード生成タスクの両方で強力な機能を明らかにしています。
最近の研究では、MIT CSAIL、上海交通大学、その他の機関の研究者が、LLM を使用して多様なシミュレーション タスクを作成し、その機能をさらに探索できるかどうかをさらに調査しました。
具体的には、研究者らは、タスク資産の配置とタスクの進捗状況を設計および検証するための自動メカニズムを提供する、LLM ベースのフレームワークである GenSim を提案しました。さらに重要なことは、生成されたタスクは非常に多様性を示し、ロボット戦略のタスクレベルの一般化を促進します。さらに、概念的には、GenSim を使用すると、LLM の推論およびエンコード機能が、シミュレートされたデータの中間合成を通じて言語-視覚-アクション戦略に洗練されます。

書き直す必要があるのは次のとおりです: 論文リンク:
https://arxiv.org/pdf/2310.01361.pdf
GenSim フレームワークは次の 3 つの部分で構成されます:
- 1 つ目は、自然言語命令と対応するコードによって実装されたプロンプト メカニズムを通じて新しいタスクを提案することです。
- Second は、検証と言語モデルの微調整のために以前に生成された高品質の命令コードをキャッシュし、それらを包括的なタスク データ セットとして返すタスク ライブラリです。 最後に、言語に適応したマルチタスク戦略トレーニング プロセスでは、生成されたデータを使用してタスク レベルの汎化機能を強化します。
以下の図 1 では、研究者は手動で計画された 10 個のタスクを含むタスク ライブラリを初期化し、GenSim を使用してそれを拡張し、100 個を超えるタスクを生成しました。

それだけでなく、研究者らはマルチタスクのロボット戦略も訓練しました。人間の計画タスクのみで訓練されたモデルと比較して、これらの戦略はすべての生成タスクでよく一般化され、ゼロショットの一般化が改善されました。 GPT-4 生成タスクを使用した共同トレーニングにより、汎化パフォーマンスが 50% 向上し、ゼロショット タスクの約 40% をシミュレーション内の新しいタスクに転送できます。
最後に、研究者らはシミュレーションから現実への移行も検討し、さまざまなシミュレーション タスクでの事前トレーニングによって現実世界の汎化能力が 25% 向上する可能性があることを示しました。
要約すると、LLM で生成されたさまざまなタスクでトレーニングされたポリシーは、新しいタスクに対するタスク レベルの一般化を改善し、LLM を介してシミュレートされたタスクを拡張して基本ポリシーをトレーニングできる可能性を強調しています。
Tenstorrent AI 製品管理ディレクターの Shubham Saboo 氏は、この研究を高く評価し、GPT-4 などの LLM を使用して自動操縦で一連のシミュレートされたロボットを生成する、GPT-4 とロボットを組み合わせた画期的な研究であると述べました。 、ロボットのゼロショット学習と現実世界への適応を実現します。

メソッドの紹介
下の図 2 に示すように、GenSim フレームワークはプログラム合成を通じてシミュレーション環境、タスク、およびデモンストレーションを生成します。 GenSim パイプラインはタスク作成者から開始され、プロンプト チェーンはターゲット タスクに応じて、目標指向モードと探索モードの 2 つのモードで実行されます。 GenSim のタスク ライブラリは、以前に生成された高品質のタスクを保存するために使用されるメモリ内コンポーネントであり、タスク ライブラリに保存されたタスクは、マルチタスク ポリシーのトレーニングや LLM の微調整に使用できます。
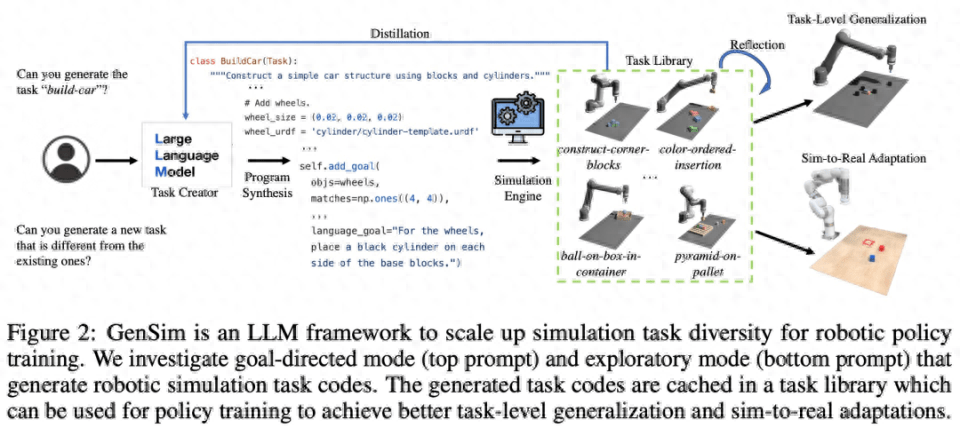
タスク作成者
以下の図 3 に示すように、言語チェーンは最初にタスクの説明を生成し、次に関連する実装を生成します。タスクの説明には、タスク名、リソース、タスクの概要が含まれます。この調査では、パイプラインで少数のサンプル プロンプトを使用してコードを生成します。
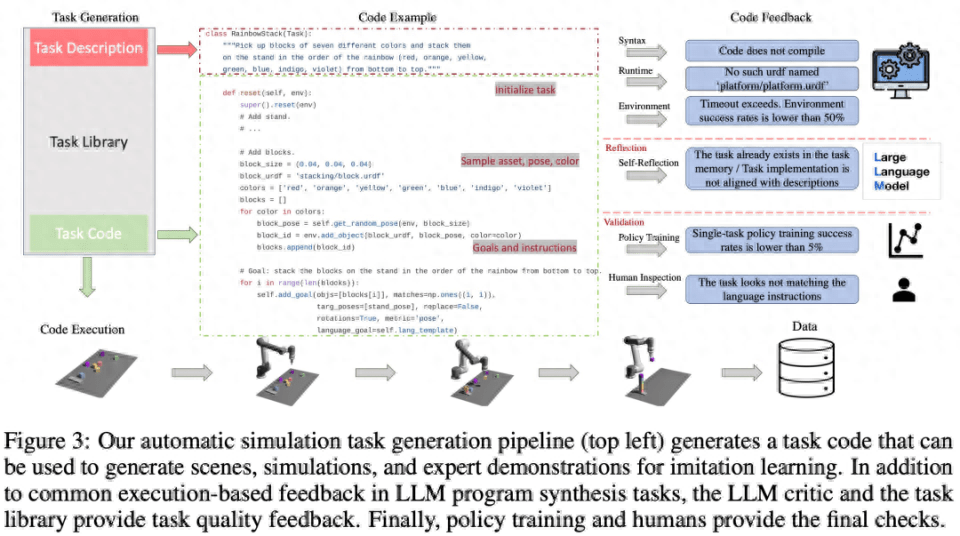
タスク ライブラリ
GenSim フレームワークのタスク ライブラリは、より優れた新しいタスクを生成し、マルチタスク戦略をトレーニングするために、タスク作成者によって生成されたタスクを保存します。タスク ライブラリは、手動で作成されたベンチマークのタスクに基づいて初期化されます。
タスク ライブラリは、タスク作成者に説明生成フェーズの条件として前のタスクの説明を提供し、コード生成フェーズに前のコードを提供し、タスク作成者にタスク ライブラリから参照タスクを選択するよう促します。新しいタスクのサンプルを作成するための基礎。タスクの実装が完了し、すべてのテストに合格すると、LLM は新しいタスクとタスク ライブラリを「反映」し、新しく生成されたタスクをライブラリに追加するかどうかについて包括的な決定を下すように求められます。
以下の図 4 に示すように、この研究では、GenSim が興味深いタスクレベルの組み合わせと外挿動作を示していることも観察されました。
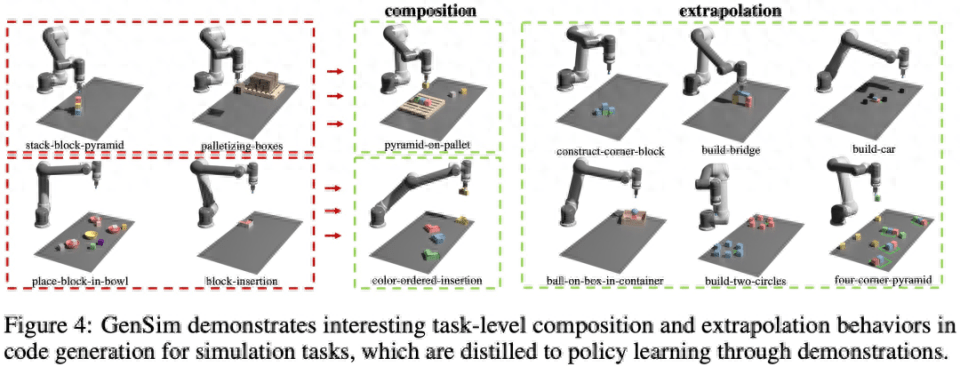
LLM 監督マルチタスク戦略
タスクを生成した後、この研究では、Shridhar et al. (2022) と同様のデュアルストリーム伝送ネットワーク アーキテクチャを使用して、これらのタスク実装を使用してデモンストレーション データを生成し、運用ポリシーをトレーニングします。下の図 5 に示すように、この研究では、プログラムをタスクと関連するデモンストレーション データの効果的な表現とみなします (図 5)。タスク間の埋め込み空間を定義することが可能であり、その距離インデックスはさまざまな影響を受けます。知覚からの要素 (オブジェクトの姿勢や形状など) はより堅牢です。

内容を書き直すには、元のテキストの言語を中国語に書き直す必要があり、元の文を表示する必要はありません
この研究では、実験を通じて GenSim フレームワークを検証し、次の特定の質問に対処します: (1) LLM はシミュレーション タスクの設計と実装においてどの程度効果的ですか? GenSim はタスク生成における LLM のパフォーマンスを向上させることができますか? (2) LLM によって生成されたタスクに関するトレーニングは、ポリシーの一般化能力を向上させることができますか?より多くの生成タスクを与えれば、ポリシー トレーニングのメリットはさらに大きくなるでしょうか? (3) LLM で生成されたシミュレーション タスクの事前トレーニングは、現実世界のロボット ポリシーの展開に有益ですか?
LLM ロボット シミュレーション タスクの汎化能力を評価する
以下の図 6 に示すように、探索モードと目標指向モードのタスク生成では、少数のサンプルとタスク ライブラリの 2 段階のプロンプト チェーンにより、コード生成の成功率を効果的に向上させることができます。
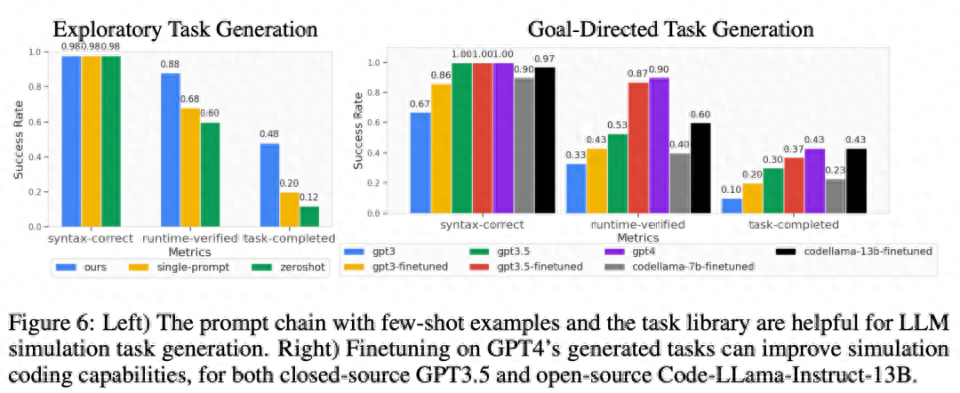
タスクレベルの一般化
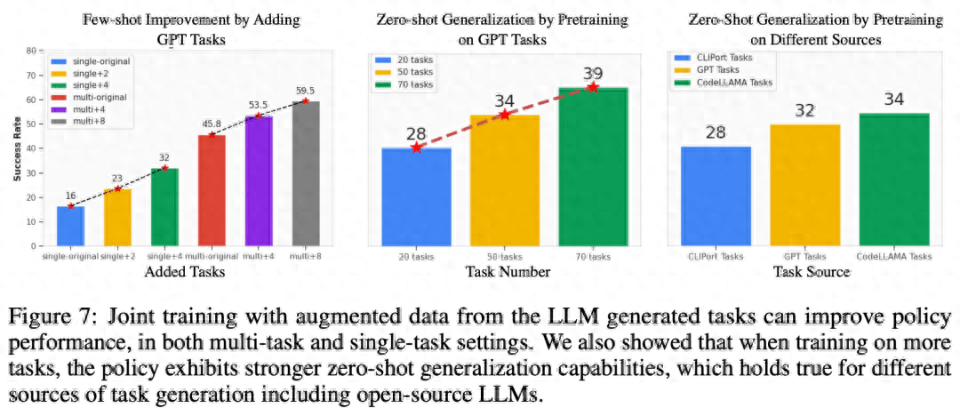
関連タスクの少数サンプル戦略の最適化。以下の図 7 の左側からわかるように、LLM によって生成されたタスクを共同トレーニングすると、特にデータ量が少ない状況 (5 つのデモなど) で、元の CLIPort タスクのポリシーのパフォーマンスが 50% 以上向上します。
目に見えないタスクに対するゼロショット ポリシーの一般化。図 7 からわかるように、LLM によって生成されたより多くのタスクで事前トレーニングすることにより、モデルは元の Ravens ベンチマークのタスクに対してより適切に一般化できます。図 7 の中央右では、研究者らはまた、手動で作成されたタスク、クローズドソース LLM、オープンソースの微調整された LLM を含む、異なるタスク ソースで 5 つのタスクを事前トレーニングし、同様のゼロショット タスク レベルを観察しました。一般化。
事前トレーニングされたモデルを現実世界に適応させる
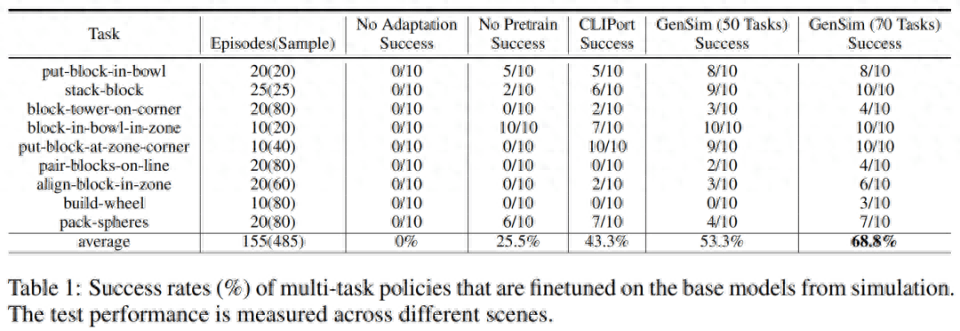
研究者は、シミュレーション環境で訓練された戦略を現実の環境に移しました。結果は以下の表 1 に示されており、GPT-4 で生成された 70 個のタスクで事前トレーニングされたモデルは、9 個のタスクで 10 回の実験を実施し、平均成功率 68.8% を達成しました。これは、CLIPort タスクのみで事前トレーニングした場合よりも優れています。ベースライン モデルと比較すると 25% 以上改善され、わずか 50 のタスクで事前トレーニングされたモデルと比較すると 15% 改善されました。
研究者らはまた、さまざまなシミュレーション タスクでの事前トレーニングにより、長期にわたる複雑なタスクの堅牢性が向上することも観察しました。たとえば、GPT-4 の事前トレーニングされたモデルは、実際のビルドホイール タスクでより堅牢なパフォーマンスを示します。

アブレーション実験
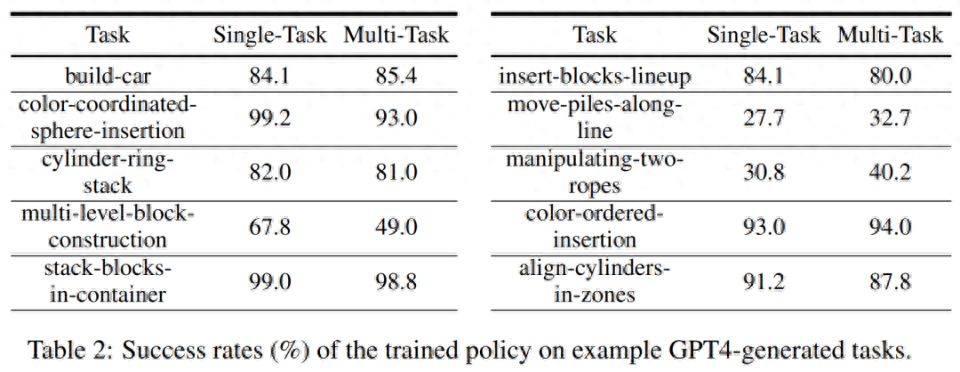
シミュレーション トレーニングの成功率。以下の表 2 では、研究者らは 200 個のデモを使用して、生成されたタスクのサブセットに対するシングルタスクおよびマルチタスクのポリシー トレーニングの成功率を示しています。 GPT-4 生成タスクに関するポリシー トレーニングの場合、平均タスク成功率はシングル タスクで 75.8%、マルチタスクで 74.1% です。
タスク統計を生成します。以下の図 9 (a) では、研究者は、LLM によって生成された 120 個のタスクのさまざまな機能のタスク統計を示しています。 LLM モデルによって生成される色、アセット、アクション、およびインスタンスの数の間には、興味深いバランスがあります。たとえば、生成されたコードには、7 つを超えるオブジェクト インスタンスを含む多くのシーンに加えて、ピック アンド プレイスのプリミティブ アクションやブロックなどのアセットが多数含まれています。
コード生成の比較において、研究者は、以下の図 9(b) の GPT-4 と Code Llama のトップダウン実験における失敗ケースを定性的に評価しました。

以上が言語、ロボット破壊、MIT などは GPT-4 を使用してシミュレーション タスクを生成し、現実世界に移行します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。