
ホームページ >テクノロジー周辺機器 >AI >学習効率の最適化: 0.6% 追加パラメータを使用して古いモデルを新しいタスクに転送します
学習効率の最適化: 0.6% 追加パラメータを使用して古いモデルを新しいタスクに転送します

- WBOY転載
- 2023-10-13 16:21:03569ブラウズ
継続学習の目的は、継続的なタスクで継続的に知識を蓄積する人間の能力を模倣することです。その主な課題は、新しいタスクを学習し続けた後、以前に学習したタスクのパフォーマンスをどのように維持するか、つまり、 catastrophic Forget (壊滅的な忘却)。継続学習とマルチタスク学習の違いは、後者はすべてのタスクを同時に取得でき、モデルはすべてのタスクを同時に学習できるのに対し、継続学習ではタスクが 1 つずつ表示され、モデルは学習できることです。タスクに関する知識のみを学習し、新しい知識を学習する過程で古い知識を忘れないようにします。
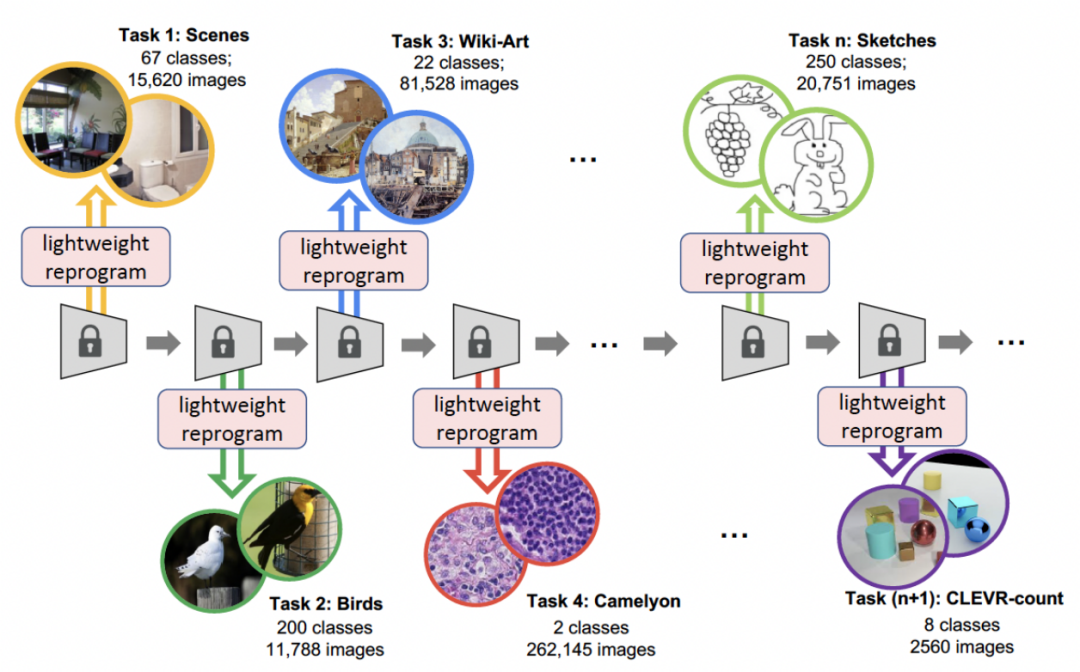
南カリフォルニア大学と Google Research は、継続学習を解決するための新しい手法を提案しました。 チャネル ライト チャネルごとの軽量化再プログラミング [CLR] : トレーニング可能な軽量モジュールを固定タスク不変バックボーンに追加することで、各層チャネルの特徴マップが再プログラミングされ、再プログラミングされた特徴マップが新しいタスクに適したものになります。このトレーニング可能な軽量モジュールは、バックボーン全体の 0.6% にすぎません。各新しいタスクは、独自の軽量モジュールを持つことができます。理論的には、壊滅的な忘れをすることなく、無限の新しいタスクを継続的に学習できます。この論文はICCV 2023に掲載されました。

- 論文アドレス: https://arxiv.org/pdf/2307.11386.pdf
- #プロジェクト アドレス: https://github.com/gyhandy/Channel-wise-Lightweight-Reprogramming
- データ収集アドレス: http://ilab.usc.edu/andy/skill102
#正則化に基づく方法では、モデルは新しいタスクを学習するプロセス中にパラメーターの更新に制限を追加し、新しい知識を学習しながら古い知識を統合します。
- 動的ネットワーク手法では、特定のタスク パラメーターを追加し、新しいタスクを学習するときに古いタスクの重みを制限します。
- #リプレイ手法は、新しいタスクを学習するときに、古いタスクのデータの一部を取得して、新しいタスクと一緒に学習できることを前提としています。
- この記事で提案する CLR 方式は、動的ネットワーク方式です。以下の図は、プロセス全体の流れを表しています。研究者らは、タスクに依存しない不変部分をタスク固有の共有パラメーターとして使用し、タスク固有のパラメーターを追加してチャネル特徴を再コーディングします。同時に、各タスクの再コーディングパラメータのトレーニング量を最小限に抑えるために、研究者はモデル内のカーネルのサイズを調整し、バックボーンからタスク固有の知識までのチャネルの線形マッピングを学習して再コーディングを実装するだけで済みます。継続学習では、新しいタスクをトレーニングして軽量モデルを取得できます。この軽量モデルに必要なトレーニング パラメーターは非常に少ないです。タスクが多くても、トレーニングする必要があるパラメーターの総数は、大規模なモデルに比べて非常に少なくなります。小型で軽量な各モデルは良好な結果を達成できます
#研究動機
継続的な学習は次の点に焦点を当てますデータストリームから学習するという問題、つまり、特定の順序で新しいタスクを学習し、以前のタスクの忘れを避けながら、獲得した知識を継続的に拡張するという問題があるため、致命的な忘れをどのように回避するかが継続学習研究の主な課題です。研究者は次の 3 つの側面を考慮しています:
- 再学習ではなく再利用: 敵対的再プログラミング [1] は、入力空間を摂動させて、ネットワーク パラメーターを再学習することなく、すでにトレーニングされたモデルを「再エンコード」し、ネットワークをフリーズして新しいタスクを解決する方法です。研究者らは「再コーディング」のアイデアを借用し、入力空間ではなく元のモデルのパラメーター空間で、より軽量かつ強力な再プログラミングを実行しました。
- チャネルタイプ変換は、2 つの異なるカーネルを接続できます。GhostNet [2] の著者は、従来のネットワークがトレーニング後に類似の機能マップを取得することを発見し、新しいネットワーク アーキテクチャ GhostNet を提案しました。 : 既存の特徴マップに対して比較的安価な操作 (線形変更など) を使用してメモリを削減し、より多くの特徴マップを生成します。これにヒントを得たこの方法では、線形変換を使用して特徴マップを生成し、ネットワークを強化するため、比較的低コストで新しいタスクごとに調整できます。
- 軽量パラメータはモデル分布を変更できます。BPN [3] は、完全接続層に有益な摂動バイアスを追加することによって、ネットワーク パラメータ分布を 1 つのタスクから別のタスクにシフトします。ただし、BPN はニューロンごとに 1 つのスカラー バイアスのみを使用して完全に接続された層のみを処理できるため、ネットワークを変更する能力は限られています。代わりに、研究者たちは、新しいタスクごとに優れたパフォーマンスを達成するために、畳み込みニューラル ネットワーク (CNN) のより強力なモード (畳み込みカーネルに「再コーディング」パラメータを追加) を設計しました。
#メソッドの説明
チャネル軽量リコーディング最初に固定バックボーンを使用します。タスク共有構造。これは、比較的多様なデータセットでの教師あり学習用の事前トレーニング済みモデル (ImageNet-1k、Pascal VOC)、またはセマンティック ラベルのないプロキシ タスク、学習自己教師あり学習モデル (DINO、SwAV) です。他の継続学習手法 (ランダムに初期化された固定構造を使用する SUPSUP、バックボーンとして最初のタスクから学習したモデルを使用する CCLL、EFT など) とは異なり、CLR で使用される事前トレーニング済みモデルはさまざまな視覚的特徴を提供できますが、視覚的な機能 他のタスクでの再コーディングには CLR レイヤーが必要です。具体的には、研究者らはチャネルごとの線形変換を使用して、元のコンボリューション カーネルによって生成された特徴画像を再エンコードしました。
#図は CLR の構造を示しています。 CLR はあらゆる畳み込みニューラル ネットワークに適しており、一般的な畳み込みニューラル ネットワークは、畳み込み層、正規化層、活性化層を含む Conv ブロック (Residual ブロック) で構成されています。 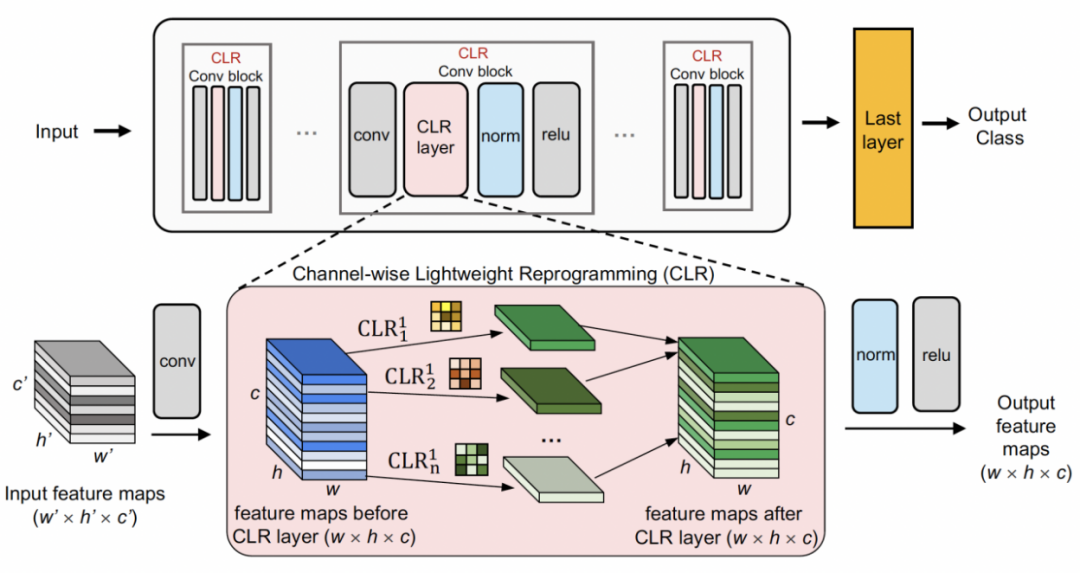
研究者らは、まず事前トレーニングされたバックボーンを修正し、次に各固定畳み込みブロックの畳み込み層の後にチャネルベースの軽量再プログラミング層 (CLR 層) を追加しました。コンボリューション カーネルを修正した後の特徴マップ上の線形変化。
画像 X があるとすると、各コンボリューション カーネル 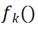 について、特徴マップ
について、特徴マップ 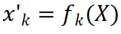 ; 次に、2D コンボリューション カーネルを使用してそれぞれを線形に変更します。 X'
; 次に、2D コンボリューション カーネルを使用してそれぞれを線形に変更します。 X' 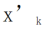 のチャネル。各コンボリューション カーネル
のチャネル。各コンボリューション カーネル 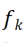 対応する線形に変化するコンボリューション カーネルが
対応する線形に変化するコンボリューション カーネルが 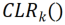 であると仮定し、再エンコードされた特徴マップ
であると仮定し、再エンコードされた特徴マップ 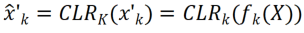 を取得できます。研究者は CLR コンボリューション カーネルを同じ変更カーネルに初期化しました (つまり、2D コンボリューション カーネルの場合、中央のパラメーターのみが 1 で、残りは 0)。 これにより、元のトレーニングを行うことができるためです。始まり 固定バックボーンによって生成される特徴は、CLR 層を追加した後のモデルによって生成される特徴と同じです。同時に、パラメータを保存し、オーバーフィッティングを防ぐために、研究者らはコンボリューションカーネルの後に CLR 層を追加せず、CLR 層はコンボリューションカーネルの後にのみ機能します。 CLR 後の ResNet50 では、固定 ResNet50 バックボーンと比較して、増加したトレーニング可能なパラメーターは 0.59% のみを占めます。
を取得できます。研究者は CLR コンボリューション カーネルを同じ変更カーネルに初期化しました (つまり、2D コンボリューション カーネルの場合、中央のパラメーターのみが 1 で、残りは 0)。 これにより、元のトレーニングを行うことができるためです。始まり 固定バックボーンによって生成される特徴は、CLR 層を追加した後のモデルによって生成される特徴と同じです。同時に、パラメータを保存し、オーバーフィッティングを防ぐために、研究者らはコンボリューションカーネルの後に CLR 層を追加せず、CLR 層はコンボリューションカーネルの後にのみ機能します。 CLR 後の ResNet50 では、固定 ResNet50 バックボーンと比較して、増加したトレーニング可能なパラメーターは 0.59% のみを占めます。
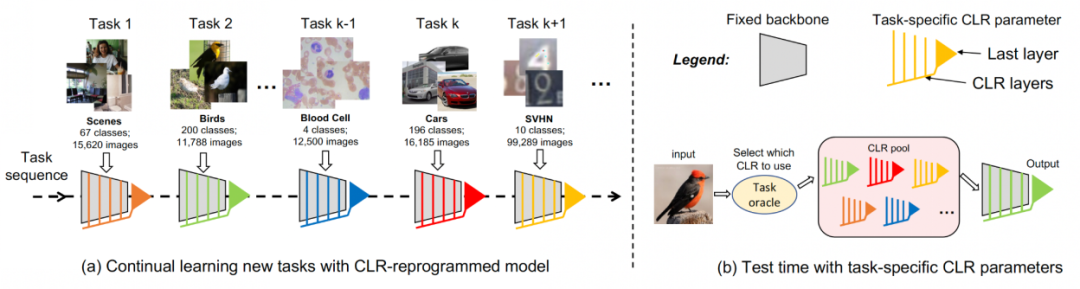
継続学習の場合、トレーニング可能な CLR パラメーターとトレーニング不可能なバックボーンを追加したモデルは、各タスクを順番に学習できます。テストの際、研究者らは、テスト画像がどのタスクに属するかをモデルに伝えることができるタスク予測子が存在し、固定バックボーンと対応するタスク固有の CLR パラメーターによって最終的な予測を行うことができると想定しています。 CLRは絶対パラメータ分離(各タスクに対応するCLR層のパラメータは異なるが、共有されるバックボーンは変わらない)の特性を持っているため、CLRはタスク数の影響を受けません。 実験結果
データ セット: 研究者は画像分類を主なタスクとして使用し、約 180 万枚の画像と 1584 のカテゴリを含む 53 の画像分類データ セットを収集しました。これらの 53 のデータセットには、オブジェクト認識、スタイル分類、シーン分類、計数、医療診断という 5 つの異なる分類目標が含まれています。
研究者は 13 のベースラインを選択しました。これらは大まかに 3 つのカテゴリに分類できます。
ダイナミック ネットワーク: PSP、SupSup、CCLL、 Confit、EFTs
- 正規化: EWC、オンライン EWC、SI、LwF
- リプレイ: ER、DERPP
- #SGD や SGD-LL など、継続的学習ではないベースラインもいくつかあります。 SGD は、ネットワーク全体を微調整することによって各タスクを学習します。SGD-LL は、すべてのタスクに固定バックボーンを使用し、長さがすべてのタスクのカテゴリの最大数に等しい学習可能な共有層を使用するバリアントです。
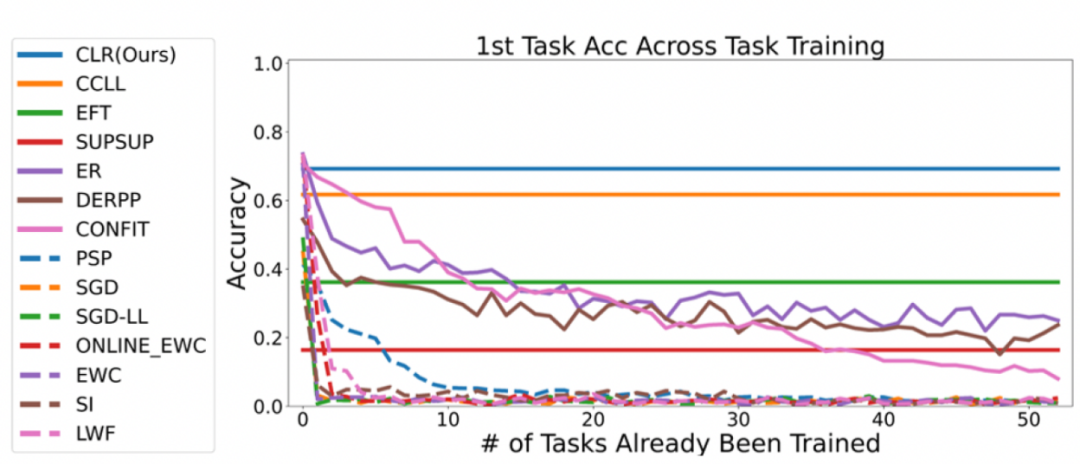
実験 1: 最初のタスクの精度
すべてのメソッドを評価するには研究者らは、壊滅的な物忘れを克服する能力を調査し、新しいタスクを学習した後、各タスクの正確さを追跡しました。メソッドに致命的な忘却が発生すると、新しいタスクを学習した後、同じタスクの精度が急速に低下します。優れた継続学習アルゴリズムは、新しいタスクを学習した後も元のパフォーマンスを維持できます。これは、古いタスクが新しいタスクから受ける影響を最小限に抑える必要があることを意味します。以下の図は、この手法の 1 番目から 53 番目のタスクを学習した後の最初のタスクの精度を示しています。全体として、この方法は最高の精度を維持できます。さらに重要なのは、どれだけ多くのタスクを継続的に学習しても、致命的な忘れを回避し、元のトレーニング方法と同じ精度を維持できることです。
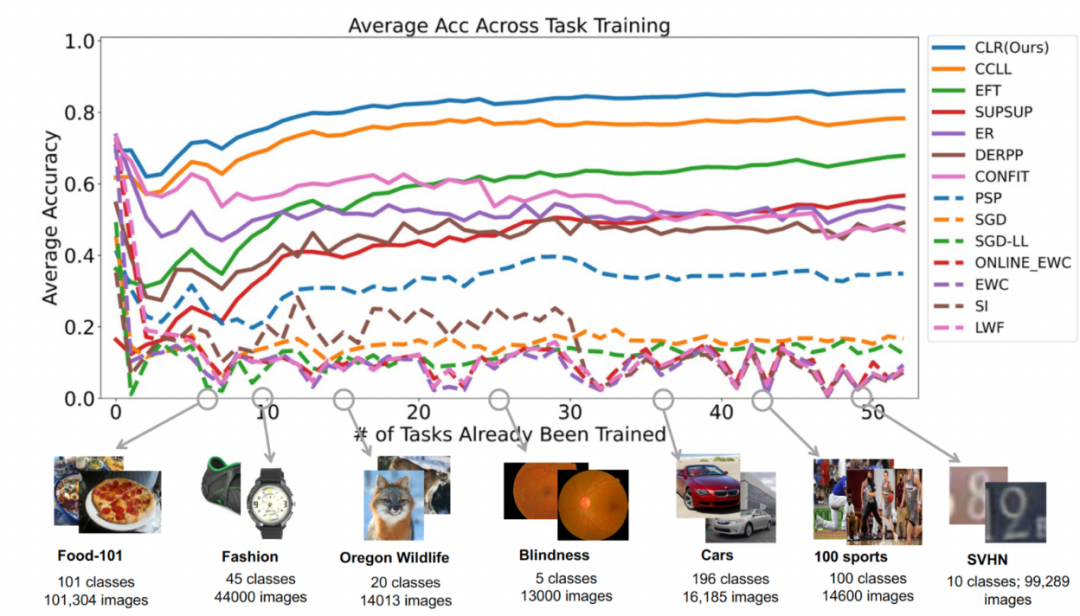
 #2 番目の実験: すべてのタスクを完了した後の平均精度の学習
#2 番目の実験: すべてのタスクを完了した後の平均精度の学習
下の図は、すべてのタスクを学習した後のすべてのメソッドの平均精度を示しています。平均精度は、継続学習法の全体的なパフォーマンスを反映します。各タスクには難易度が異なるため、新しいタスクが追加されると、追加されたタスクが簡単か難しいかに応じて、すべてのタスクの平均精度が上下する可能性があります。
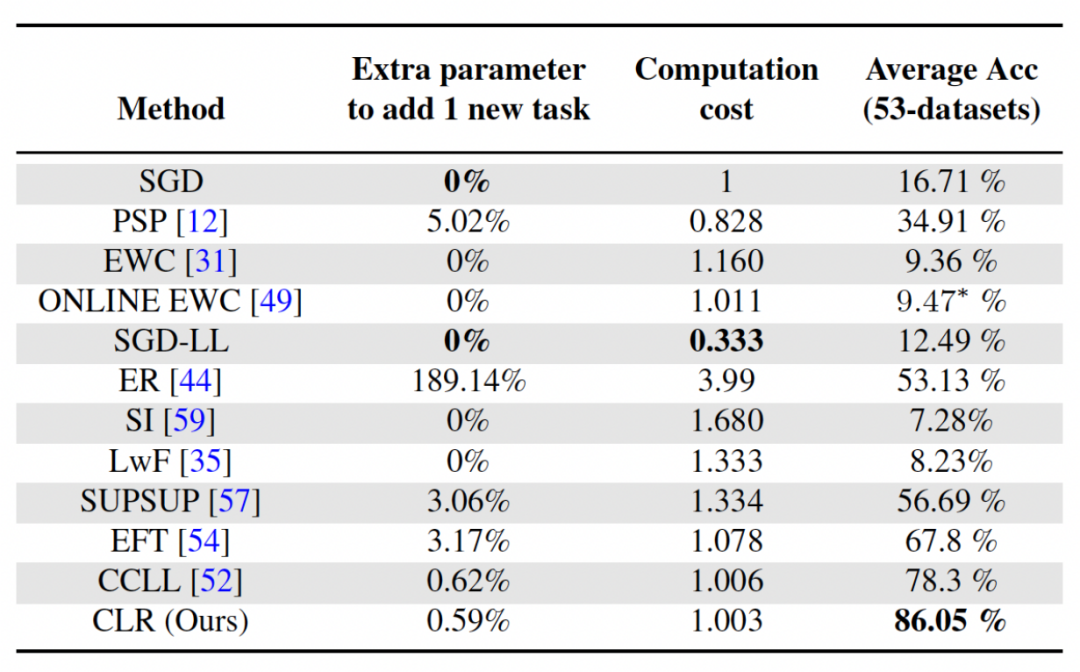
#まずはパラメータと計算コストを分析しましょう
学習では、より高い平均精度を達成することが重要ですが、優れたアルゴリズムでは、追加のネットワーク パラメーターの要件と計算コストを最小限に抑えることも望まれます。 「新しいタスクに追加パラメータを追加」は、元のバックボーン パラメータ量の割合を表します。この記事では SGD の計算コストを単位としており、他の手法の計算コストは SGD のコストに応じて正規化されています。
書き直された内容: さまざまなバックボーン ネットワークの影響の分析
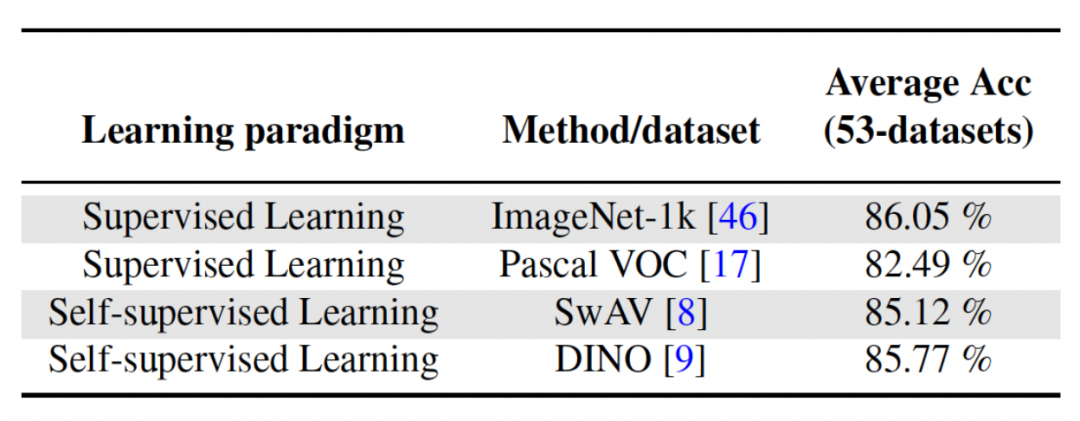
この記事 この方法では、教師あり学習または自己教師あり学習手法を使用して、比較的多様なデータセットでトレーニングし、タスクから独立した不変パラメーターとして機能する事前トレーニング済みモデルを取得します。さまざまな事前トレーニング方法の影響を調査するために、この論文では、異なるデータセットとタスクを使用してトレーニングされた、タスクに依存しない 4 つの異なる事前トレーニング モデルを選択しました。教師あり学習では、研究者らは画像分類に ImageNet-1k と Pascal-VOC の事前トレーニング済みモデルを使用し、自己教師あり学習では、DINO と SwAV という 2 つの異なる方法で取得した事前トレーニング済みモデルを使用しました。次の表は、4 つの異なる方法を使用した事前トレーニング モデルの平均精度を示しています。どの方法でも最終結果が非常に高いことがわかります (注: Pascal-VOC は比較的小さいデータ セットであるため、精度は比較的高くなります)低いポイント)、事前にトレーニングされたさまざまなバックボーンに対して堅牢です。
以上が学習効率の最適化: 0.6% 追加パラメータを使用して古いモデルを新しいタスクに転送しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
関連記事
続きを見る- Microsoft Solitaire Collection はアンインストールできますか?
- Haimo スーパーコンピューティング センターの公式発表: 1,000 億のパラメーターを持つ大規模モデル、100 万クリップのデータ規模、トレーニング コストの 200 倍の削減
- ショックを受けた! 70,000 時間のトレーニングを経て、OpenAI のモデルは「Minecraft」で木材を計画する方法を学習しました
- バック・トゥ・ザ・フューチャー! AI をトレーニングするために子供時代の日記を使用したこのプログラマーは、GPT-3 を使用して「過去の自分」との対話を実現しました
- 合成データは AI/ML トレーニングの将来を推進するのでしょうか?