
ホームページ >テクノロジー周辺機器 >AI >STRIDE 脅威モデルから攻撃対象領域の脅威と AI アプリケーションの管理を考察する
STRIDE 脅威モデルから攻撃対象領域の脅威と AI アプリケーションの管理を考察する

- WBOY転載
- 2023-10-13 14:29:091470ブラウズ

STRIDE は、組織がアプリケーション システムに影響を与える可能性のある脅威、攻撃、脆弱性、対策を事前に発見するのに役立つ、現在広く使用されている人気の脅威モデリング フレームワークです。 「STRIDE」の各文字が分離されている場合、偽造、改ざん、拒否、情報漏洩、サービス拒否、特権昇格を表しており、多くのセキュリティ担当者は、これらのシステムのセキュリティ リスクを特定し、保護する必要性を重要な要素として求めています。できるだけ早く。 STRIDE フレームワークは、組織が AI システムで起こり得る攻撃経路をより深く理解し、AI アプリケーションのセキュリティと信頼性を強化するのに役立ちます。この記事では、セキュリティ研究者が STRIDE モデル フレームワークを使用して、AI システム アプリケーションの攻撃対象領域を包括的にマッピングし (以下の表を参照)、AI テクノロジーに特有の新しい攻撃カテゴリと攻撃シナリオに関する研究を実施します。 AI テクノロジーの継続的な開発により、より多くの新しいモデル、アプリケーション、攻撃、操作モードが登場するでしょう
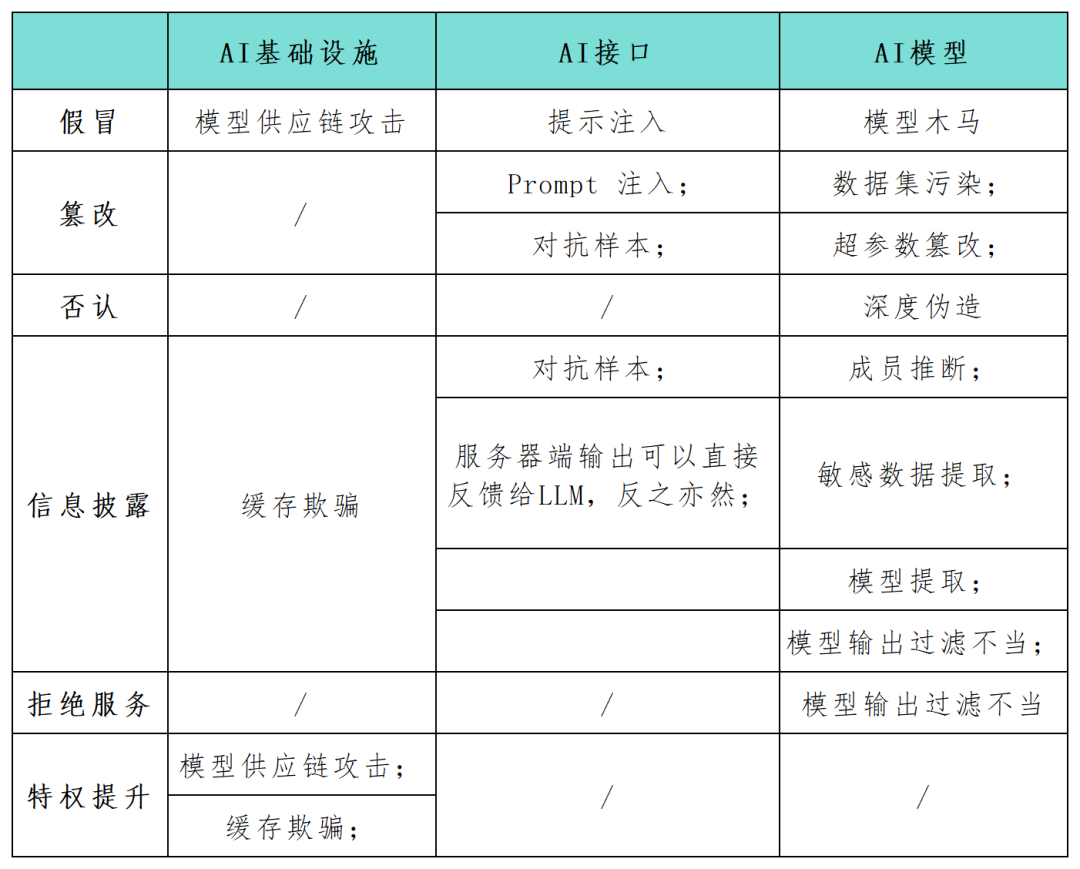 AI インフラストラクチャに対する攻撃
AI インフラストラクチャに対する攻撃
AI 研究者の Andrej Karpathy 氏は次のように指摘しました。新世代のディープ ニューラル ネットワーク モデルの登場は、ソフトウェア生産を概念化する従来の方法におけるパラダイム シフトを示していることがわかります。開発者は、ループや条件文の言語ではなく、連続的なベクトル空間や数値重みで表現される複雑なシステムに AI モデルを埋め込むケースが増えており、脆弱性悪用経路の新たな可能性を生み出し、新たな脅威カテゴリを生み出しています。
攻撃者がモデルの入出力を改ざんしたり、AI インフラストラクチャの特定の設定パラメーターを変更したりできる場合、予期しない動作、相互作用など、有害で予測できない悪意のある結果が生じる可能性があります。 AI エージェントとの連携、およびリンクされたコンポーネントへの影響
書き換えられた内容: なりすましとは、攻撃者がモデルまたはコンポーネントの配信プロセス中に信頼できるソースをシミュレートして、悪意のある要素を AI システムに導入することを指します。この手法により、攻撃者は悪意のある要素を AI システムに注入することができます。同時に、なりすましはサプライ チェーン攻撃のモデルの一部として使用される可能性もあります。例えば、Huggingface のようなサードパーティのモデルプロバイダーに脅威アクターが侵入した場合、AI が出力したコードが下流で実行される際に上流のモデルに感染することで、周囲のインフラを制御できる情報漏洩が発生します。機密データの漏洩は、AI システムにサービスを提供するアプリケーションを含む、あらゆるネットワーク アプリケーションにとって共通の問題です。 2023 年 3 月、Redis の構成ミスにより、Web サーバーがプライベート データを公開しました。一般に、Web アプリケーションは、インジェクション攻撃、クロスサイト スクリプティング、安全でない直接オブジェクト参照など、OWASP のトップ 10 に入る古典的な脆弱性の影響を受けやすくなります。同じ状況が、AI システムにサービスを提供する Web アプリケーションにも当てはまります。
サービス拒否 (DoS)。 DoS 攻撃も人工知能アプリケーションに対する脅威となり、攻撃者はモデル プロバイダーのインフラストラクチャに大量のトラフィックを大量に送信することで、人工知能サービスを使用できなくします。人工知能システムのインフラストラクチャとアプリケーションを設計する際に、復元力はセキュリティを実現するための基本要件ですが、それだけでは十分ではありません
モデルのトレーニングと推論に対する攻撃
トレーニングされた AI モデルと新しい 3 番目のモデルの場合-パーティの生成 AI システムには、次のような攻撃面の脅威もあります:
データセット汚染とハイパーパラメータ改ざん。 AI モデルは、トレーニングおよび推論フェーズ中に特定の脅威の影響を受けやすくなります。データセット汚染とハイパーパラメーター改ざんは、STRIDE 改ざんカテゴリに分類される攻撃であり、脅威アクターが悪意のあるデータをトレーニング データセットに挿入することを指します。たとえば、攻撃者が意図的に誤解を招く画像を顔認識 AI に送り込み、AI が個人を誤って識別する可能性があります。
敵対的な例は、AI アプリケーションにおける情報漏洩や改ざんの一般的な脅威となっています。攻撃者はモデルの入力を操作して、誤った予測や分類結果を生成します。これらの動作により、モデルのトレーニング データ内の機密情報が明らかになったり、モデルが予期しない動作をするようだまされたりする可能性があります。たとえば、研究者チームは、一時停止標識に小さなテープを追加すると、自動運転車に組み込まれた画像認識モデルを混乱させ、モデル抽出に重大な結果をもたらす可能性があると指摘しました。モデル抽出は、STRIDE の情報開示カテゴリに該当する、新たに発見された悪意のある攻撃の形式です。攻撃者の目標は、モデルのクエリと応答に基づいて独自のトレーニング済み機械学習モデルを複製することです。彼らは一連のクエリを作成し、モデルの応答を使用してターゲット AI システムのレプリカを構築します。このような攻撃は知的財産権を侵害する可能性があり、重大な経済的損失を引き起こす可能性があります。同時に、攻撃者がモデルのコピーを入手すると、敵対的攻撃を実行したり、トレーニング データをリバース エンジニアリングして、他の脅威を作成したりすることもできます。
大規模言語モデル (LLM) に対する攻撃
大規模言語モデル (LLM) の人気により、新しい AI 攻撃手法の出現が促進されています。LLM の開発と統合は非常にホットなトピックです。 、それを狙った新たな攻撃形態が次々と登場している。この目的を達成するために、OWASP 研究チームは、OWASP Top 10 LLM 脅威プロジェクトの最初のバージョンの草案を作成し始めました。
書き換えられた内容: 入力プロンプト攻撃とは、脱獄、プロンプト漏洩、トークン密輸などの行為を指します。これらの攻撃では、攻撃者は入力プロンプトを使用して、LLM の予期しない動作を引き起こします。このような操作により、STRIDE モデルの欺瞞と情報漏洩のカテゴリと一致して、AI が不適切に反応したり、機密情報が漏洩したりする可能性があります。これらの攻撃は、AI システムが他のシステムと組み合わせて使用されている場合、またはソフトウェア アプリケーション チェーン内で使用されている場合に特に危険です。多数の API アプリケーションが、非公開のさまざまな方法で悪用される可能性があります。たとえば、Langchain のようなフレームワークを使用すると、アプリケーション開発者は、パブリック生成モデルやその他のパブリックまたはプライベート システム (データベースや Slack 統合など) に複雑なアプリケーションを迅速にデプロイできます。攻撃者は、モデルを騙して他の方法では許可されていない API クエリを作成させるヒントを作成する可能性があります。同様に、攻撃者は、サニタイズされていない一般的な Web フォームに SQL ステートメントを挿入して、悪意のあるコードを実行する可能性があります。
メンバーの推論と機密データの抽出は書き直す必要があります。攻撃者はメンバーシップ推論攻撃を悪用して、特定のデータ ポイントがトレーニング セット内にあるかどうかをバイナリごとに推論することができ、プライバシーの懸念が生じます。データ抽出攻撃により、攻撃者はモデルの応答からトレーニング データに関する機密情報を完全に再構築することができます。 LLM がプライベート データセットでトレーニングされる場合、一般的なシナリオは、モデルに組織の機密データが含まれる可能性があり、攻撃者が特定のプロンプトを作成することで機密情報を抽出できるというものです。
書き換えられた内容: トロイの木馬モデルは、次のような A モデルです。微調整フェーズ中にトレーニング データセットの汚染の影響を受けやすいことが示されています。さらに、よく知られた公開トレーニング データの改ざんが実際に実行可能であることが証明されています。これらの弱点により、公的に利用可能な言語モデルに対するトロイの木馬モデルへの扉が開かれます。表面的には、ほとんどのヒントで期待どおりに機能しますが、微調整中に導入された特定のキーワードが非表示になります。攻撃者がこれらのキーワードをトリガーすると、トロイの木馬モデルは、特権の昇格、システムの使用不能化 (DoS)、個人の機密情報の漏洩など、さまざまな悪意のある動作を実行する可能性があります。
参考リンク:
書き換える必要があるコンテンツは次のとおりです: https://www.secureworks.com/blog/unravelling-the- Attack-surface-of-ai-systems
以上がSTRIDE 脅威モデルから攻撃対象領域の脅威と AI アプリケーションの管理を考察するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。