
ホームページ >テクノロジー周辺機器 >AI >MotionLM: マルチエージェント動作予測のための言語モデリング技術
MotionLM: マルチエージェント動作予測のための言語モデリング技術

- WBOY転載
- 2023-10-13 12:09:051382ブラウズ
この記事は自動運転ハート公式アカウントの許可を得て転載しておりますので、転載については出典元にご連絡ください。
原題: MotionLM: Multi-Agent Motion Forecasting as Language Modeling
論文リンク: https://arxiv.org/pdf/2309.16534.pdf
著者の所属: Waymo
カンファレンス: ICCV 2023

ペーパーアイデア:
自動運転車の安全計画のため、確実に未来を予測する道路管理者の行動は非常に重要です。この研究では、連続的な軌跡を離散的なモーション トークンのシーケンスとして表現し、マルチエージェントのモーション予測を言語モデリング タスクとして扱います。私たちが提案するモデル MotionLM にはいくつかの利点があります。 まず、マルチモーダル分布を最適に学習するためにアンカー ポイントや明示的な潜在変数を使用する必要がありません。代わりに、シーケンス トークンの平均ログ確率を最大化するという標準言語モデリングの目標を活用します。第 2 に、私たちのアプローチは、個々のエージェントの軌跡の生成がインタラクション スコアリングの後に行われるポストホック インタラクション ヒューリスティックを回避します。対照的に、MotionLM は、単一の自己回帰デコード プロセスでインタラクティブ エージェントの将来の結合分布を生成します。さらに、モデルの逐次分解により、時間的な因果関係の推論が可能になります。私たちが提案した手法は、Waymo Open Motion データセット上で新たな最先端のパフォーマンスを達成し、インタラクティブ チャレンジ リーダーボードで 1 位にランクされました
主な貢献:
こちらでこの記事では、言語モデリング タスクとしてのマルチエージェントの動作予測について説明します。因果言語モデリング損失でトレーニングされた離散運動トークンをデコードするための時間的因果デコーダを導入します。
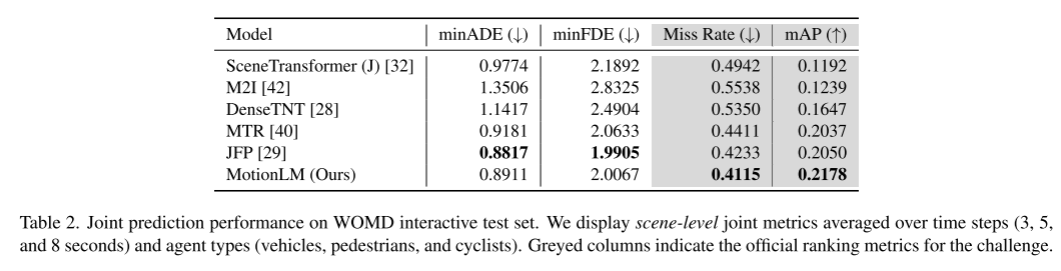
この論文では、モデル内のサンプリングと単純なロールアウト集計スキームを組み合わせて、関節軌道認識能力の重み付けパターンを改善します。 Waymo Open Motion Dataset インタラクション予測チャレンジでの実験を通じて、この新しい方法により、ランキング共同 mAP メトリクスが 6% 向上し、最先端のパフォーマンス レベルに達することが実証されました。
この記事のアプローチこの記事 大規模なアブレーション実験が実行され、その時間的因果関係の条件付き予測が分析されていますが、これは現在の関節予測モデルではほとんどサポートされていません。
ネットワーク設計:
このペーパーの目標は、以下を含むさまざまなダウンストリーム タスクに適用できる一般的な方法で、マルチエージェント インタラクションの分布をモデル化することです。最小予測、結合予測、および条件付き予測。この目標を達成するには、運転シーンの複数の形態を捉えることができる表現力豊かな生成フレームワークが必要です。さらに、ここでは時間依存性の節約を考慮します。つまり、モデルでは、推論は有向非巡回グラフに従い、各ノードの親ノードが時間的に早く、その子ノードが時間的に遅くなり、条件付き予測が因果関係に近くなります。なぜなら、それがなければ時間的因果関係への不従順につながる、ある種の偽りの相関関係を排除するからである。この論文では、時間的な依存関係を保存しないジョイント モデルでは、計画における重要な用途である実際のエージェントの応答を予測する能力が限られている可能性があることを観察しています。この目的を達成するために、この論文では、将来のデコーダの自己回帰分解を利用します。この分解では、エージェントのモーション トークンが、以前にサンプリングされたすべてのトークンに条件付きで依存し、軌跡が順番に導出されます。
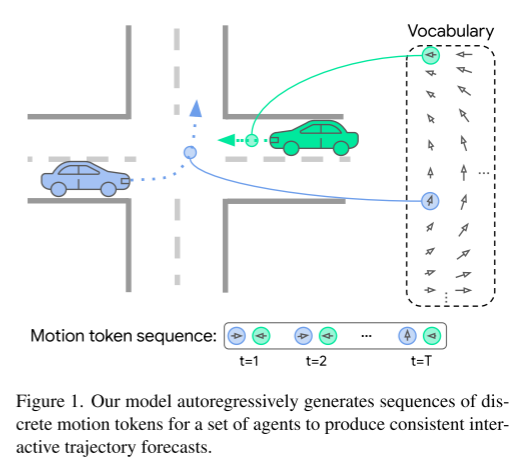
図 1 。私たちのモデルは、一連のエージェントに対して一連の離散モーション トークンを自己回帰的に生成し、一貫したインタラクティブな軌道予測を生成します。
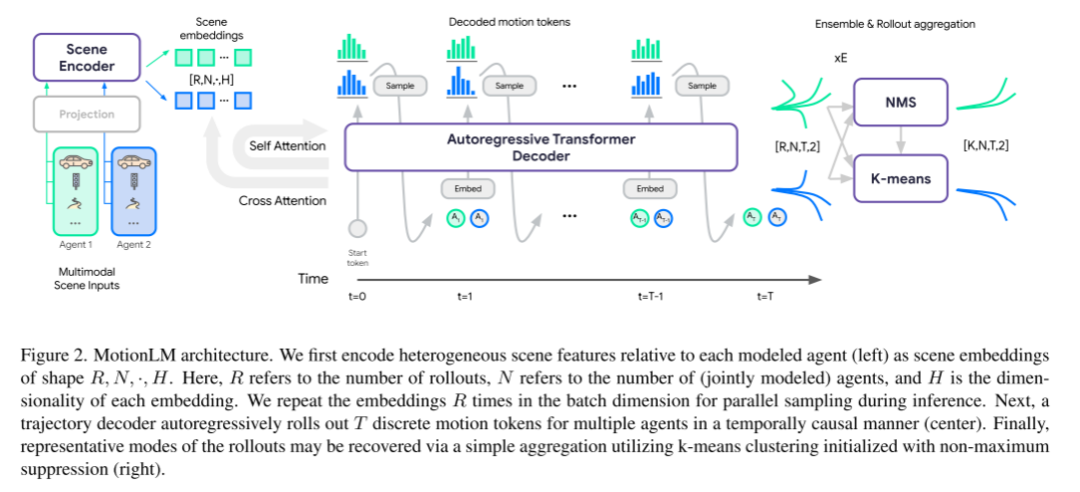
MotionLM のアーキテクチャである図 2 をご覧ください。
この記事では、まず、各モデリング エージェントに関連する異種シーンの特徴 (左) をエンコードします。形状 R,N,·,H のシーン埋め込み。このうち、R はロールアウトの数、N は共同モデル化されたエージェントの数、H は各埋め込みの次元です。推論プロセス中、サンプリングを並列化するために、本稿ではバッチ次元で埋め込みを R 回繰り返します。次に、軌跡デコーダは、複数のエージェントに対して時間的に因果的な方法で T 個の離散モーション トークンをロールアウトします (中央)。最後に、典型的なロールアウト パターンは、非最大抑制初期化を使用した K 平均法クラスターの単純な集約によって回復できます (右パネル)。
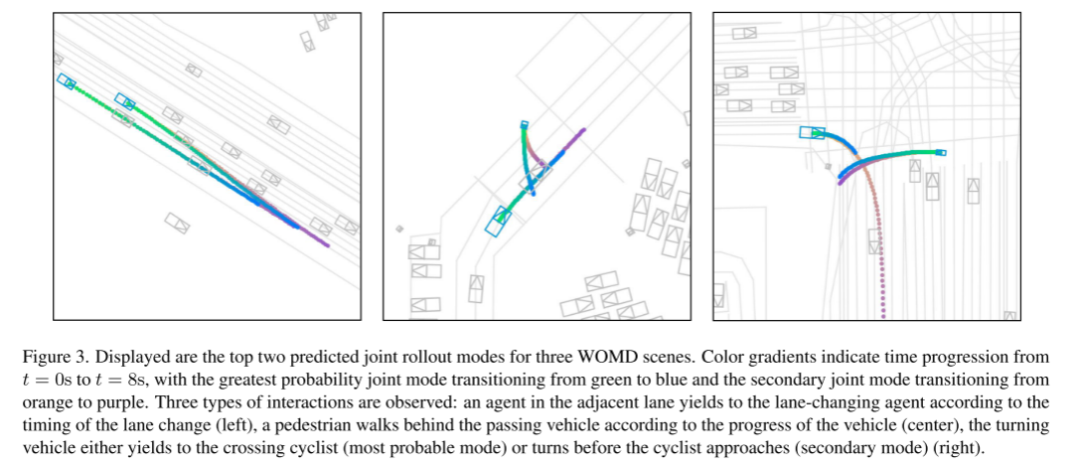
色のグラデーションは、t = 0 秒から t = 8 秒までの時間変化を表します。ジョイント モードは緑から青に遷移し、サブジョイント モードはオレンジから紫に最も高い確率で遷移します。 3 種類のインタラクションを観察しました。隣接する車線のエージェントは車線変更時間に応じて車線変更エージェントに道を譲ります (左)、歩行者は車両の進行に応じて追い越し車両の後ろを歩きます (中央)、方向転換車両は車線変更エージェントに道を譲ります。追い越す自転車に道を譲る (最も可能性の高いモード)、または自転車が近づく前に方向転換する (マイナー モード) (右側)
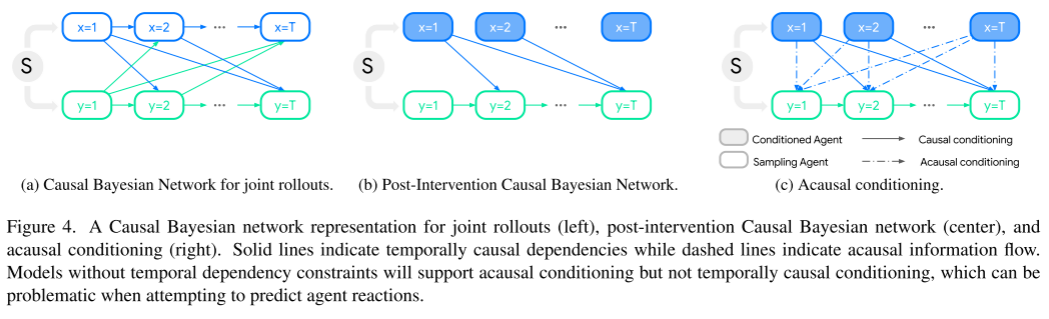
図 4 を参照してください。この図は、共同誘導 (左)、介入後の因果ベイジアン ネットワーク (中央)、および因果条件付け (右) の因果ベイジアン ネットワーク表現を示しています。
実線は時間相関における因果関係を表し、破線は時間相関を表します。因果関係のある情報の流れ。時間依存の制約のないモデルは、因果的条件付けをサポートしますが、時間的因果的条件付けはサポートしません。これは、エージェントの応答を予測しようとするときに問題になる可能性があります。 #########実験結果: ##################################### #
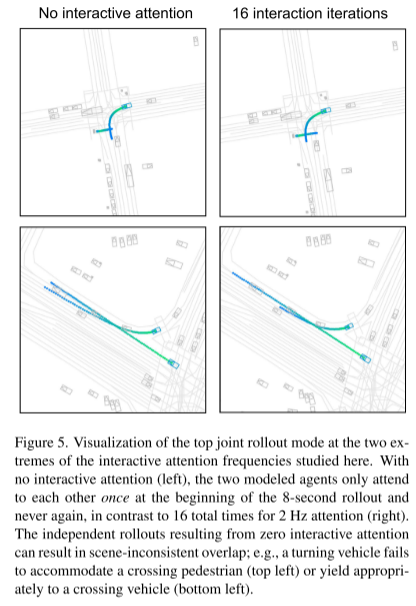
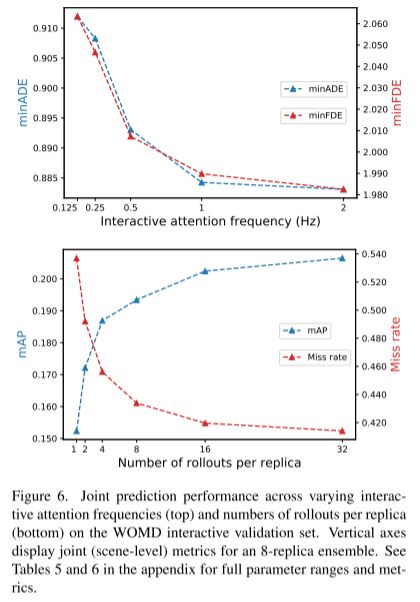
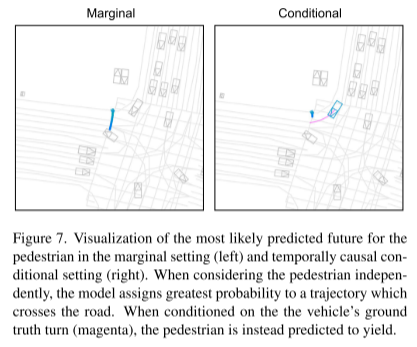
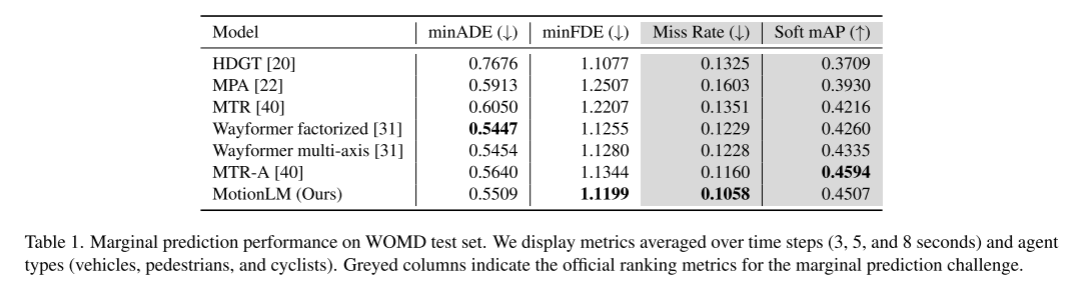 ArXiv. /abs/2309.16534
ArXiv. /abs/2309.16534
元のリンク: https://mp.weixin.qq.com/s/MTai0rA8PeNFuj7UjCfd6A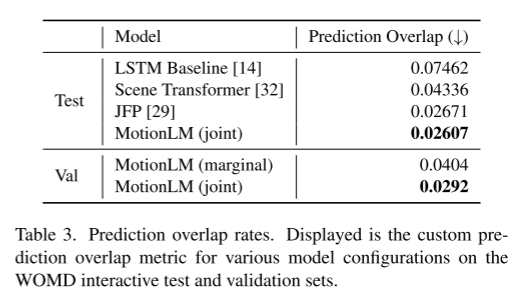
以上がMotionLM: マルチエージェント動作予測のための言語モデリング技術の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。