
ホームページ >テクノロジー周辺機器 >AI >クロスモーダル トランスフォーマー: 高速かつ堅牢な 3D オブジェクト検出用
クロスモーダル トランスフォーマー: 高速かつ堅牢な 3D オブジェクト検出用

- 王林転載
- 2023-10-10 22:53:161232ブラウズ

現在、自動運転車には、ライダーやミリ波レーダー、カメラセンサーなど、さまざまな情報収集センサーが搭載されています。現在の観点から見ると、さまざまなセンサーが自動運転の認識タスクにおいて大きな発展の可能性を示しています。たとえば、カメラによって収集された 2D 画像情報は豊富な意味特徴をキャプチャし、LIDAR によって収集された点群データは、知覚モデルにオブジェクトの正確な位置情報と幾何学情報を提供できます。さまざまなセンサーから得られる情報を最大限に活用することで、自動運転の知覚プロセスにおける不確実要素の発生を低減し、知覚モデルの検出ロバスト性を向上させることができます。 Megvii 自動運転知覚論文からの論文であり、今年の ICCV2023 ビジョン サミットに選ばれました。この記事の主な特徴は、PETR のようなエンドツーエンド BEV 知覚アルゴリズムです (フィルター処理に NMS 後処理操作を使用する必要がなくなりました)冗長な知覚結果).フレーム)を追加し、同時に LIDAR の点群情報を追加してモデルの知覚パフォーマンスを向上させています。自動運転知覚の方向性に関する非常に優れた論文です。記事へのリンクと公式のオープンソース ウェアハウスのリンクは次のとおりです。
論文のリンク: https://arxiv.org/pdf/2301.01283.pdf- コードのリンク: https://github. com/junjie18/CMT
次に、CMT 知覚のネットワーク構造の全体的な紹介をします。
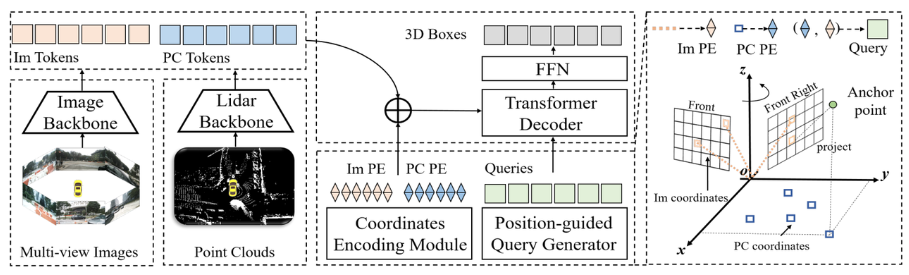 全体のアルゴリズム ブロック図からわかるように、アルゴリズム モデル全体は主に 3 つの部分で構成されています。
全体のアルゴリズム ブロック図からわかるように、アルゴリズム モデル全体は主に 3 つの部分で構成されています。
Lidar バックボーン ネットワーク カメラ バックボーン ネットワーク (Image Backbone Lidar Backbone): 点群と周囲の画像を取得するために使用されます。機能は、Point Cloud Token**(PC Tokens)
- と Image Token
- (Im Tokens)* です。 *位置コーディングの生成: さまざまなセンサーによって収集されたデータ情報について、 Im Tokens
- は対応する座標位置コード Im PE、PC Tokens# を生成します。 ## 対応する座標位置コード PC PE と Object Queries対応する座標位置エンコーディングも生成しますQuery embeddingTransformer Decoder FFNネットワーク: 入力は Object Queries
- Query embedding であり、完全な位置エンコーディング Im Tokens および PC Tokens はクロスアテンション計算を実行し、 FFN による最終的な 3D ボックス カテゴリ予測の生成ネットワーク カメラ バックボーン ネットワーク (画像バックボーン Lidar バックボーン)Lidar バックボーン ネットワーク 一般的に、点群データ フィーチャの抽出に使用される Lidar バックボーン ネットワークには、次の 5 つの部分が含まれます
点群情報のボクセル化
- ボクセル特徴のエンコード
-
3D バックボーン (一般的に使用される VoxelResBackBone8x ネットワーク) は、ボクセル特徴のエンコード結果から 3D 特徴を抽出します。 3D バックボーンをフィーチャの Z 軸に合わせて圧縮し、BEV 空間のフィーチャを取得します。
- since 2D バックボーンによって出力される特徴マップのチャネル数が画像によって出力されるチャネル数と一致しない場合、畳み込み層を使用してチャネル数を計算します。 ##################カメラバックボーンネットワーク###一般的に使用されるカメラバックボーンネットワークは、次の 2 つの部分:
- 入力: 2D バックボーンによって出力された 16 倍および 32 倍のダウンサンプリングされた特徴マップ
- 出力: 16 回ダウンサンプリングされた画像特徴と 2D バックボーンによって出力された画像特徴の融合16 回ダウンサンプリングされた特徴マップを取得するには 32 回
Tensor([bs * N, 2048, H/16, W/16])
- 必要なコンテンツ書き換えられる内容は次のとおりです: tensor ([bs * N, 256, H / 16, W / 16])
-
書き換え内容: ResNet-50 ネットワークを使用して特徴を抽出しますサラウンド画像 出力: 16 倍および 32 倍ダウンサンプリングされた出力画像特徴入力テンソル:
Tensor([bs * N, 3, H, W])出力テンソル:
Tensor([bs * N, 1024, H/16, W/16])出力テンソル: ``Tensor([bs * N, 2048, H/32] 、W/32])`
書き換える必要がある内容は次のとおりです: 2D スケルトン抽出画像の特徴
Neck (CEFPN)
位置コーディングの生成
# 上記の紹介によると、位置コーディングの生成には主に 3 つの部分、つまり画像位置埋め込み、点群位置埋め込み、およびクエリ埋め込みが含まれます。以下では、その生成プロセスを 1 つずつ紹介します。
- Image Position Embedding (Im PE)
Image Position Embedding の生成プロセスは、PETR における画像位置エンコーディングの生成ロジックと同じです (詳細については、PETR を参照してください。論文の原文 (ここでは詳しく説明しません) は、次の 4 つのステップに要約できます。
- 3D 画像錐台点を生成する画像座標系の雲
- 3D 画像錐台点群は、カメラ内部パラメータ行列を使用してカメラ座標系に変換され、3D カメラ座標点を取得します
- カメラ内の 3D 点座標系は、cam2ego 座標変換行列を使用して BEV 座標系に変換されます
- MLP レイヤーを使用して、変換された BEV 3D 座標に対して位置エンコードを実行し、最終的な画像位置エンコードを取得します
- #点群位置埋め込み (PC PE)
- 点群位置埋め込みの生成プロセスは、次の 2 つのステップに分けることができます。
-
# を使用します。 BEV 空間のグリッド座標点に pos2embed()
関数を実行して 2 次元の水平方向と垂直方向を埋め込みます。その座標点は高次元の特徴空間に変換されます# 点云位置编码`bev_pos_embeds`的生成bev_pos_embeds = self.bev_embedding(pos2embed(self.coords_bev.to(device), num_pos_feats=self.hidden_dim))def coords_bev(self):x_size, y_size = (grid_size[0] // downsample_scale,grid_size[1] // downsample_scale)meshgrid = [[0, y_size - 1, y_size], [0, x_size - 1, x_size]]batch_y, batch_x = torch.meshgrid(*[torch.linspace(it[0], it[1], it[2]) for it in meshgrid])batch_x = (batch_x + 0.5) / x_sizebatch_y = (batch_y + 0.5) / y_sizecoord_base = torch.cat([batch_x[None], batch_y[None]], dim=0) # 生成BEV网格.coord_base = coord_base.view(2, -1).transpose(1, 0)return coord_base# shape: (x_size *y_size, 2)def pos2embed(pos, num_pos_feats=256, temperature=10000):scale = 2 * math.pipos = pos * scaledim_t = torch.arange(num_pos_feats, dtype=torch.float32, device=pos.device)dim_t = temperature ** (2 * (dim_t // 2) / num_pos_feats)pos_x = pos[..., 0, None] / dim_tpos_y = pos[..., 1, None] / dim_tpos_x = torch.stack((pos_x[..., 0::2].sin(), pos_x[..., 1::2].cos()), dim=-1).flatten(-2)pos_y = torch.stack((pos_y[..., 0::2].sin(), pos_y[..., 1::2].cos()), dim=-1).flatten(-2)posemb = torch.cat((pos_y, pos_x), dim=-1)return posemb# 将二维的x,y坐标编码成512维的高维向量
- 多層パーセプトロン (MLP) ネットワークを使用して、空間変換を実行してチャネル番号の位置を確実に調整します。
-
オブジェクトクエリ、画像トークン、ライダートークン間の類似度計算を行うためにより正確には、論文へのクエリ埋め込みは、位置エンコーディングを生成する Lidar とカメラのロジックを使用して生成されます。具体的には、クエリ埋め込み = 画像位置埋め込み (以下の rv_query_embeds と同じ)、点群位置埋め込み (以下の bev_query_embeds と同じ) です。
bev_query_embeds 生成ロジック -
論文内のオブジェクト クエリは元々 BEV 空間 初期化されているため、点群位置埋め込み生成ロジックで位置エンコーディングと bev_embedding() 関数を直接再利用できます。対応するキー コードは次のとおりです:
def _bev_query_embed(self, ref_points, img_metas):bev_embeds = self.bev_embedding(pos2embed(ref_points, num_pos_feats=self.hidden_dim))return bev_embeds# (bs, Num, 256)
#rv_query_embeds 生成ロジックを書き直す必要があります -
前述のコンテンツでは、Object Query は BEV 座標系の初期点です。画像位置埋め込みの生成プロセスを追跡するには、最初に BEV 座標系の 3D 空間点を画像座標系に投影し、次に前世代の画像位置埋め込みの処理ロジックを使用して、次のことを保証する必要があります。生成プロセスのロジックは同じです。以下はコア コードです:
最後のクエリの埋め込み = rv_query_embeds bev_query_embedsdef _rv_query_embed(self, ref_points, img_metas):pad_h, pad_w = pad_shape# 由归一化坐标点映射回正常的roi range下的3D坐标点ref_points = ref_points * (pc_range[3:] - pc_range[:3]) + pc_range[:3]points = torch.cat([ref_points, ref_points.shape[:-1]], dim=-1)points = bda_mat.inverse().matmul(points)points = points.unsqueeze(1)points = sensor2ego_mats.inverse().matmul(points)points =intrin_mats.matmul(points)proj_points_clone = points.clone() # 选择有效的投影点z_mask = proj_points_clone[..., 2:3, :].detach() > 0proj_points_clone[..., :3, :] = points[..., :3, :] / (points[..., 2:3, :].detach() + z_mask * 1e-6 - (~z_mask) * 1e-6)proj_points_clone = ida_mats.matmul(proj_points_clone)proj_points_clone = proj_points_clone.squeeze(-1)mask = ((proj_points_clone[..., 0] = 0)& (proj_points_clone[..., 1] = 0))mask &= z_mask.view(*mask.shape)coords_d = (1 + torch.arange(depth_num).float() * (pc_range[4] - 1) / depth_num)projback_points = (ida_mats.inverse().matmul(proj_points_clone))projback_points = torch.einsum("bvnc, d -> bvndc", projback_points, coords_d)projback_points = torch.cat([projback_points[..., :3], projback_points.shape[:-1]], dim=-1)projback_points = (sensor2ego_mats.matmul(intrin_mats).matmul(projback_points))projback_points = (bda_mat@ projback_points)projback_points = (projback_points[..., :3] - pc_range[:3]) / (pc_range[3:] - self.pc_range[:3])rv_embeds = self.rv_embedding(projback_points)rv_embeds = (rv_embeds * mask).sum(dim=1)return rv_embeds上記の変換により、BEV 空間座標系の点を画像座標系に投影するプロセスが完了し、前の処理ロジックを使用して画像位置を生成します。 rv_query_embeds を生成するための埋め込み。
Transformer Decoder FFN network
- Transformer Decoder
ここでの計算ロジックは Transformer の Decoder とまったく同じですが、入力データは少し異なります
- 最初のポイントはメモリです。ここでのメモリは、イメージ トークンとライダー トークンの間の結合の結果です (2 つのモダリティの融合として理解できます)
- 2 番目のポイントポイントは位置です エンコーディング: ここでの位置エンコーディングは、rv_query_embeds と bev_query_embeds の間の連結の結果です query_embed is rv_query_embeds bev_query_embeds;
- FFN network
この FFN ネットワークの機能は正確にPETR の結果と同じ はい、具体的な出力結果は PETR の原文に記載されているため、ここでは詳しく説明しません。
nuScenes のテスト セットでの各認識アルゴリズムの認識結果の比較
表内のモダリティは認識アルゴリズムに入力されるセンサー カテゴリを表し、C はカメラ センサーを表し、モデルはカメラ データのみを供給します. L は LIDAR センサーを表し、モデルは点群データのみを供給します LC は LIDAR センサーとカメラ センサーを表し、モデルはマルチモーダル データを入力します 実験結果から、CMT-C モデルのパフォーマンスが高いことがわかりますCMT-L モデルのパフォーマンスは、CenterPoint や UVTR などの純粋な LIDAR のパフォーマンスよりも優れています アルゴリズム モデル CMT が LIDAR 点群データとカメラ データを使用する場合、既存のシングルモーダル手法をすべて上回ります 実験結果からわかります。その結果、CMT-L 知覚モデルのパフォーマンスは FUTR3D および UVTR を上回り、ライダー点群データとカメラ データ収集後の両方を使用した場合、CMT は FUTR3D、UVTR、TransFusion、BEVFusion などの既存のマルチモーダル知覚アルゴリズムを大幅に上回りました。 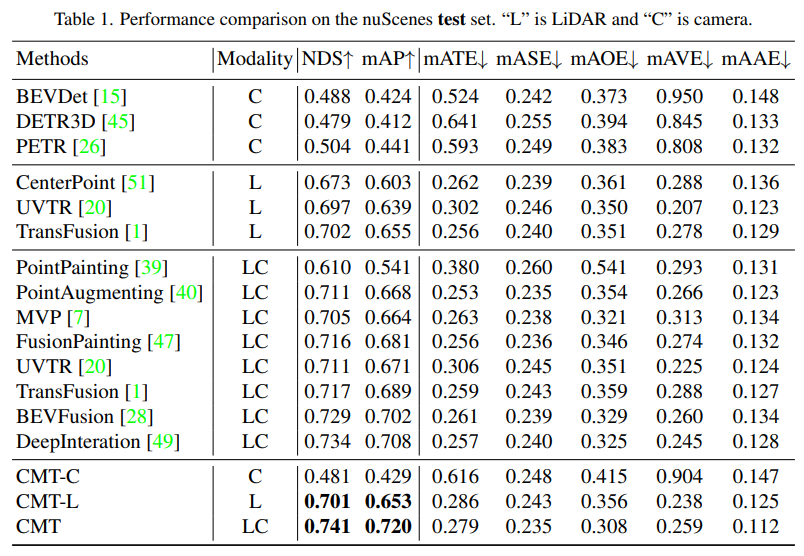
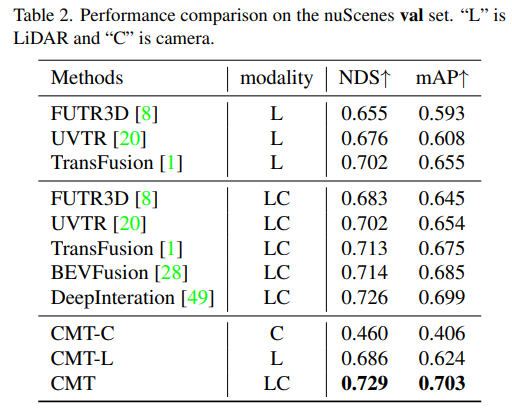
まず、位置エンコーディングを使用するかどうかを決定するために、一連のアブレーション実験を実施しました。実験結果により、NDS インジケーターと mAP インジケーターは、画像と LIDAR の位置エンコーディングを同時に使用すると最良の結果が得られることがわかりました。次に、アブレーション実験のパート (c) と (f) では、さまざまなタイプとボクセル サイズの点群バックボーン ネットワークを実験しました。パート (d) と (e) のアブレーション実験では、カメラ バックボーン ネットワークの種類と入力解像度のサイズに関して異なる試みを行いました。上記は実験内容を簡単にまとめたものですが、より詳細なアブレーション実験について知りたい場合は、元の記事を参照してください
最後に、CMTの知覚結果をnuScenesのデータ上に視覚的に表示してみましょう実験結果から、CMT の方が依然として優れた知覚結果を持っていることがわかります。 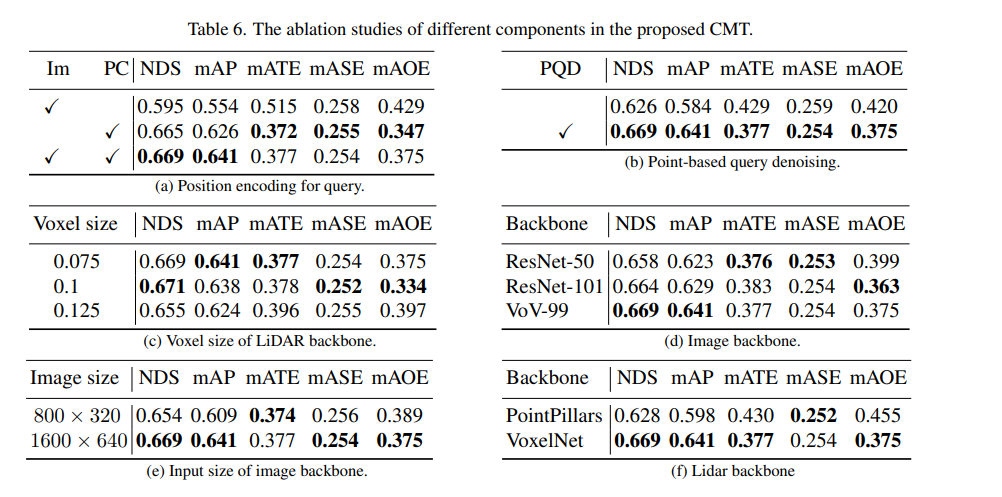

書き直す必要がある内容は次のとおりです。元のリンク: https://mp.weixin.qq.com/s/Fx7dkv8f2ibkfO66- 5hEXA
以上がクロスモーダル トランスフォーマー: 高速かつ堅牢な 3D オブジェクト検出用の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
関連記事
続きを見る- SQLサーバーはどのタイプのデータモデルに属しますか?
- TCP/IP参照モデルのトランスポート層はOSI参照モデルのどの層に相当しますか?
- 自動運転用の 3 つの主流チップ アーキテクチャの概要を 1 つの記事でまとめたもの
- Baidu Research Institute が 2023 年のトップ 10 テクノロジー トレンドを発表、「現実に向かう AI」を定着させる: 業界の大規模モデル エコロジーが台頭しており、自動運転、AIGC、量子テクノロジーなどのインテリジェントなイノベーションはより実用的になっています
- テスラの自動運転の第一人者は ChatGPT に参加する予定ですか? OpenAIに参加します