



メタ学習のモデル選択問題には特定のコード例が必要です
メタ学習は機械学習の手法であり、その目標は学習を通じて学習自体を改善することです。能力。メタ学習における重要な問題は、モデルの選択、つまり、特定のタスクに最適な学習アルゴリズムまたはモデルをどのように自動的に選択するかです。
従来の機械学習では、モデルの選択は通常、手動の経験とドメインの知識によって決定されます。このアプローチは非効率な場合があり、大量のデータやモデルを最大限に活用できない可能性があります。したがって、メタ学習の出現は、モデル選択問題に対する新しい考え方を提供します。
メタ学習の核となる考え方は、学習アルゴリズムを学習することでモデルを自動的に選択することです。この種の学習アルゴリズムはメタラーナーと呼ばれ、大量の経験データからパターンを学習し、現在のタスクの特性と要件に基づいて適切なモデルを自動的に選択できます。
一般的なメタ学習フレームワークは、対照的な学習方法に基づいています。このアプローチでは、メタ学習者は、異なるモデルを比較する方法を学習することによってモデルの選択を実行します。具体的には、メタ学習者は既知のタスクとモデルのセットを使用し、さまざまなタスクでのパフォーマンスを比較することによってモデル選択戦略を学習します。この戦略では、現在のタスクの特性に基づいて最適なモデルを選択できます。
以下は、メタ学習を使用してモデル選択問題を解決する方法を示す具体的なコード例です。バイナリ分類タスク用のデータ セットがあり、データの特性に基づいて最も適切な分類モデルを選択したいとします。
# 导入必要的库
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 创建一个二分类任务的数据集
X, y = make_classification(n_samples=1000, n_features=10, random_state=42)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 定义一组模型
models = {
'Logistic Regression': LogisticRegression(),
'Decision Tree': DecisionTreeClassifier(),
'Random Forest': RandomForestClassifier()
}
# 通过对比学习来选择模型
meta_model = LogisticRegression()
best_model = None
best_score = 0
for name, model in models.items():
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
score = accuracy_score(y_test, y_pred)
# 更新最佳模型和得分
if score > best_score:
best_model = model
best_score = score
# 使用最佳模型进行预测
y_pred = best_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Best model: {type(best_model).__name__}")
print(f"Accuracy: {accuracy}")このコード例では、まずバイナリ分類タスク用のデータ セットを作成します。次に、ロジスティック回帰、デシジョン ツリー、ランダム フォレストという 3 つの異なる分類モデルを定義しました。次に、これらのモデルを使用してテスト データをトレーニングおよび予測し、精度を計算します。最後に、精度に基づいて最適なモデルを選択し、それを使用して最終的な予測を行います。
この簡単なコード例を通して、メタ学習が比較学習を通じて適切なモデルを自動的に選択できることがわかります。このアプローチにより、モデル選択の効率が向上し、データとモデルをより有効に活用できます。実際のアプリケーションでは、タスクの特性とニーズに応じてさまざまなメタ学習アルゴリズムとモデルを選択し、より優れたパフォーマンスと汎化機能を得ることができます。
以上がメタ学習におけるモデル選択の問題の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 CrewaiとOllamaでマルチエージェントシステムを構築する方法は?Apr 12, 2025 am 09:44 AM
CrewaiとOllamaでマルチエージェントシステムを構築する方法は?Apr 12, 2025 am 09:44 AM導入 APIにお金を費やしたくないのですか、それともプライバシーを心配していますか?それとも、LLMSをローカルに実行したいだけですか?心配しないで;このガイドは、ローカルLLMSを使用してエージェントとマルチエージェントフレームワークを構築するのに役立ちます
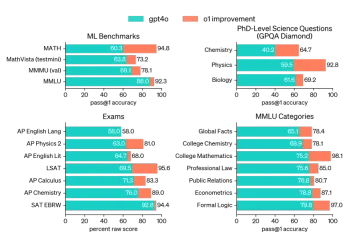 AVバイト:Openai' S O1モデル、Apple'の視覚的なAIなど - 分析VidhyaApr 12, 2025 am 09:38 AM
AVバイト:Openai' S O1モデル、Apple'の視覚的なAIなど - 分析VidhyaApr 12, 2025 am 09:38 AM導入 今週は、人工知能の世界(AI)の主要な更新が詰め込まれています。 OpenaiのO1モデルから、高度な推論の紹介からAppleの画期的な視覚知能技術、Techまで
 生産グレードのエージェントRAGパイプラインを監視する方法は?Apr 12, 2025 am 09:34 AM
生産グレードのエージェントRAGパイプラインを監視する方法は?Apr 12, 2025 am 09:34 AM導入 2022年、CHATGPTの立ち上げにより、ハイテク産業と非テクノロジーの両方の業界の両方に革命をもたらし、個人や組織にAIを生成しました。 2023年を通じて、大規模な言語モードの活用に集中しました
 Star Schemaを使用してデータウェアハウスを最適化する方法は?Apr 12, 2025 am 09:33 AM
Star Schemaを使用してデータウェアハウスを最適化する方法は?Apr 12, 2025 am 09:33 AMStar Schemaは、データウェアハウジングとビジネスインテリジェンスで使用される効率的なデータベース設計です。データを整理し、周囲の寸法テーブルにリンクされた中央のファクトテーブルになります。この星のような構造は、複雑なqを簡素化します
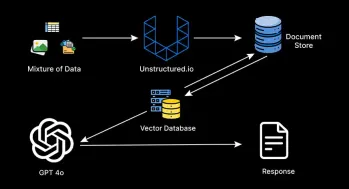 マルチモーダルRAGシステムの構築に関する包括的なガイドApr 12, 2025 am 09:29 AM
マルチモーダルRAGシステムの構築に関する包括的なガイドApr 12, 2025 am 09:29 AMRAGシステムとしてよく知られている検索拡張生成システムは、高価な微調整の手間なしでカスタムエンタープライズデータに関する質問に答えるインテリジェントAIアシスタントを構築するための事実上の標準となっています
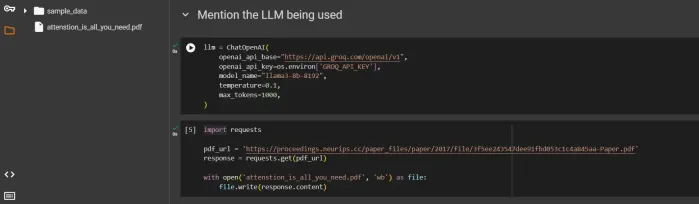 エージェントラグシステムはどのようにテクノロジーを変換しますか?Apr 12, 2025 am 09:21 AM
エージェントラグシステムはどのようにテクノロジーを変換しますか?Apr 12, 2025 am 09:21 AM導入 人工知能は新しい時代に入りました。モデルが事前定義されたルールに基づいて単に情報を出力する時代は終わりました。今日のAIの最先端のアプローチは、Ragを中心に展開しています(検索装備
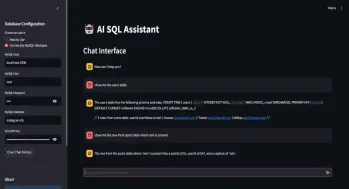 自動生成クエリのSQLアシスタントApr 12, 2025 am 09:13 AM
自動生成クエリのSQLアシスタントApr 12, 2025 am 09:13 AM複雑なSQLクエリを書いたり、スプレッドシートを並べ替えたりせずに、データベースと話をしたり、単純な言語で質問したり、即座に答えを得たりすることを望んだことがありますか? LangchainのSQL Toolkit、Groq a
 AIインデックス2025を読む:AIはあなたの友人、敵、または副操縦士ですか?Apr 11, 2025 pm 12:13 PM
AIインデックス2025を読む:AIはあなたの友人、敵、または副操縦士ですか?Apr 11, 2025 pm 12:13 PMスタンフォード大学ヒト指向の人工知能研究所によってリリースされた2025年の人工知能インデックスレポートは、進行中の人工知能革命の良い概要を提供します。 4つの単純な概念で解釈しましょう:認知(何が起こっているのかを理解する)、感謝(利益を見る)、受け入れ(顔の課題)、責任(責任を見つける)。 認知:人工知能はどこにでもあり、急速に発展しています 私たちは、人工知能がどれほど速く発展し、広がっているかを強く認識する必要があります。人工知能システムは絶えず改善されており、数学と複雑な思考テストで優れた結果を達成しており、わずか1年前にこれらのテストで惨めに失敗しました。 2023年以来、複雑なコーディングの問題や大学院レベルの科学的問題を解決することを想像してみてください


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

MantisBT
Mantis は、製品の欠陥追跡を支援するために設計された、導入が簡単な Web ベースの欠陥追跡ツールです。 PHP、MySQL、Web サーバーが必要です。デモおよびホスティング サービスをチェックしてください。

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

