

大型モデルのブラックボックスを破壊し、ニューロンを完全に分解しましょう! OpenAI のライバル Anthropic が AI の説明不可能性の壁を打ち破る

長年にわたり、私たちは人工知能がどのように意思決定を行い、出力を生成するかを理解できませんでした。
モデル開発者ができるのは、アルゴリズムとデータについて決定し、最終的にはモデルの出力結果、および中間部分、つまりモデルがこれらのアルゴリズムとデータに基づいて結果を出力する方法は、目に見えない「ブラック ボックス」になります。

「モデルのトレーニングは錬金術のようなもの」というジョークがあります。
しかし今、モデルのブラック ボックスがついに解釈可能になりました。
Anthropic の研究チームは、モデルのニューラル ネットワーク内の最も基本的な単位ニューロンの解釈可能な特徴を抽出しました。

#これは、人類が AI のブラック ボックスを明らかにするための画期的な一歩となるでしょう。
人間は興奮した表情でこう言いました:
「モデル内のニューラル ネットワークがどのように機能するかを理解できれば、モデルの欠陥を診断できます。パターン、設計の修正、企業や社会による安全な採用は、手の届く現実になるでしょう!」
Anthropic の最新の研究ではレポート「単一意味性を目指して: 辞書学習を使用した言語モデルの分解」では、研究者が辞書学習手法を使用して、512 個のニューロンを含む層を 4,000 を超える解釈可能な特徴に分解することに成功しました

研究レポートのアドレス: https://transformer-circuits.pub/2023/monosemantic-features/index.html
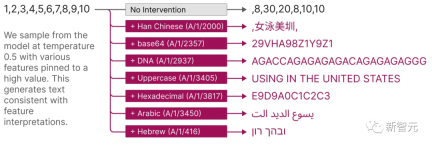
これらの特徴は、DNA 配列、法的言語、HTTP リクエストを表します
#単一ニューロンの活性化を個別に観察すると、これらのモデルのプロパティのほとんどを確認することは不可能です
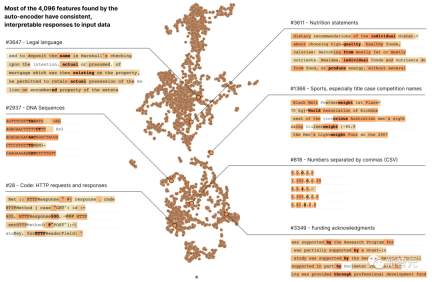
たとえば、小規模な言語モデルでは、単一のニューロンが、学術的な引用、英会話、HTTP リクエスト、韓国語のテキストなど、無関係な多くのコンテキストでアクティブになります。
古典的な視覚モデルでは、単一のニューロンが猫の顔と車の前部に反応します。
#さまざまな状況において、ニューロンの活性化がさまざまな意味を持つことを多くの研究が実証しています。
 #考えられる理由の 1 つは、ニューロンの多意味的な性質が相加効果によるものであるということです。これは仮説的な現象で、ニューラル ネットワークが各特徴に独自のニューロンの線形結合を割り当てることでデータの独立した特徴を表し、そのような特徴の数がニューロンの数を超えます
#考えられる理由の 1 つは、ニューロンの多意味的な性質が相加効果によるものであるということです。これは仮説的な現象で、ニューラル ネットワークが各特徴に独自のニューロンの線形結合を割り当てることでデータの独立した特徴を表し、そのような特徴の数がニューロンの数を超えます
If 各特徴がニューロン上のベクトルと見なされる場合、特徴セットはネットワーク ニューロンの活性化に対する過完全な線形基礎を形成します。
Anthropic の以前の「重ね合わせのおもちゃモデル」論文では、スパース性によってニューラル ネットワーク トレーニングのあいまいさが解消され、モデルが特徴間の関係をよりよく理解できるようになり、それによって不確実性が軽減されることが証明されました。活性化ベクトルのソース特徴を分析し、モデルの予測と決定の信頼性を高めます。
この概念は、信号の希薄性により、限られた観測から完全な信号を復元できる圧縮センシングの概念と似ています。

ただし、「重ね合わせのおもちゃモデル」で提案されている 3 つの戦略のうち、
# (1) 重ね合わせのないモデルを作成する、おそらく活性化の疎性を促進することができます。
##(2) 重ね合わせ状態を示すモデルでは、辞書学習を使用して過完全な特徴を見つけます#(3) ) は、2 つを組み合わせたハイブリッド アプローチに依存しています。
書き直す必要があるのは、方法 (1) では曖昧さの問題を解決できないのに対し、方法 (2) では深刻な過学習が発生する傾向があるということです。
そこで今回、Anthropic の研究者は、スパース オートエンコーダーと呼ばれる弱い辞書学習アルゴリズムを使用して、訓練されたモデルから学習された特徴を生成しました。これにより、意味解析のより統一的な単位であるモデル ニューロン自体よりも優れたパフォーマンスが得られます。
具体的には、研究者らは 512 個のニューロンを備えた MLP 単層トランスフォーマーを採用し、最終的に 80 億のデータ ポイントからの MLP アクティベーションでスパース オートエンコーダーをトレーニングしました。MLP アクティベーションを比較的解釈可能な特徴に分解し、拡張係数の範囲は 1 倍 (512 フィーチャ) から 256 倍 (131,072 フィーチャ) です。
#この研究で見つかった特徴がモデルのニューロンよりも解釈可能であることを検証するために、ブラインド レビューを実施し、人間の評価者にその解釈可能性を評価するよう依頼しました。#ご覧のとおり、特徴 (赤色) はニューロン (シアン) よりもはるかに高いスコアを持っています。
研究者によって発見された特徴は、モデル内のニューロンに比べて理解しやすいことが示されています
さらに、研究者らは、大規模な言語モデルを使用して小規模なモデルの機能の短い説明を生成し、別のモデルに機能のアクティベーションを予測する能力に基づいてその説明をスコアリングさせるという「自動解釈可能性」アプローチを採用しました。
同様に、特徴のスコアはニューロンよりも高く、特徴の活性化とモデルの動作に対する下流の影響について一貫した解釈が示されています。 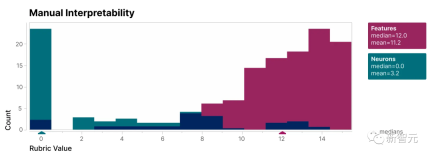
さらに、これらの抽出された特徴は、モデルをガイドするための対象を絞った方法も提供します。
下の図に示すように、機能を人為的にアクティブ化すると、モデルの動作が予測可能な方法で変化する可能性があります。 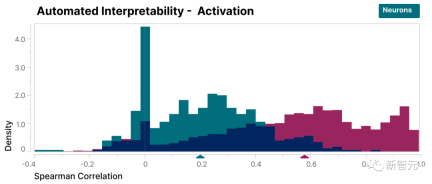
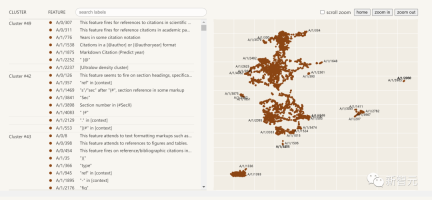
#以下は、抽出された解釈可能性の特徴を視覚化したものです:
調査レポートの概要
##この調査Anthropic のレポート「Toward Monosemanticity: Decomposition Language Models With Dictionary Learning」は 4 つの部分に分けることができます。
問題設定では、研究者は研究の動機を紹介し、訓練されたトランスフォーマーとスパース オートエンコーダーについて詳しく説明しました。
個々の特徴の詳細な調査により、研究で見つかったいくつかの特徴が機能的に特異的な原因単位であることが証明されました。
グローバル分析を通じて、典型的な特徴は解釈可能であり、MLP 層の重要なコンポーネントを説明できると結論付けました。
現象分析では、特徴のセグメンテーション、普遍性、および複雑な動作を実現するために「有限状態オートマトン」に似たシステムを形成する方法など、特徴のいくつかの特性について説明します。
結論には次の 7 が含まれます。
スパース オートエンコーダには、比較的単一の意味論的特徴を抽出する機能があります。
スパース オートエンコーダーは、実際にはニューロンの基盤では目に見えない解釈可能な特徴を生成できます
3. スパース オートエンコーダーの特徴は、ニューロンの生成に介入し、ガイドするために使用できます。トランスフォーマー。
4. スパース オートエンコーダーは、比較的一般的な特徴を生成できます。
オートエンコーダーのサイズが大きくなると、特徴が「分割」される傾向があります。 書き換え後: オートエンコーダーのサイズが大きくなるにつれて、特徴は「分割」の傾向を示します
##6。わずか 512 個のニューロンで数千の特徴を表現できます
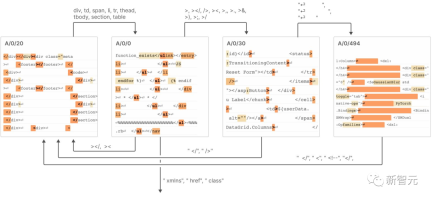
#7. 以下の図に示すように、これらの機能は「有限状態オートマトン」システムと同様に相互に接続され、複雑な動作を実現します。
Anthropic は、この研究レポートの小さなモデルの成功をより大きなモデルに再現するには、将来私たちが直面する課題はもはや科学的な問題ではなく、工学的な問題になると考えています。問題
大規模なモデルで解釈可能性を実現するには、モデルの複雑さとサイズによってもたらされる課題を克服するために、エンジニアリングにおいてより多くの労力とリソースが必要です
#新しい開発が含まれますこれには、モデルの複雑さとデータ規模の課題に対処するためのツール、テクニック、方法が含まれ、大規模モデルのニーズに適応するためのスケーラブルな解釈フレームワークとツールの構築も含まれます。
これは解釈型人工知能と大規模深層学習研究の最新トレンドとなるでしょう
以上が大型モデルのブラックボックスを破壊し、ニューロンを完全に分解しましょう! OpenAI のライバル Anthropic が AI の説明不可能性の壁を打ち破るの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 踊りましょう:私たちの人間のニューラルネットを微調整するための構造化された動きApr 27, 2025 am 11:09 AM
踊りましょう:私たちの人間のニューラルネットを微調整するための構造化された動きApr 27, 2025 am 11:09 AM科学者は、彼らの機能を理解するために、人間とより単純なニューラルネットワーク(C. elegansのものと同様)を広く研究してきました。 ただし、重要な疑問が生じます。新しいAIと一緒に効果的に作業するために独自のニューラルネットワークをどのように適応させるのか
 新しいGoogleリークは、Gemini AIのサブスクリプションの変更を明らかにしますApr 27, 2025 am 11:08 AM
新しいGoogleリークは、Gemini AIのサブスクリプションの変更を明らかにしますApr 27, 2025 am 11:08 AMGoogleのGemini Advanced:Horizonの新しいサブスクリプションティア 現在、Gemini Advancedにアクセスするには、1か月あたり19.99ドルのGoogle One AIプレミアムプランが必要です。 ただし、Android Authorityのレポートは、今後の変更を示唆しています。 最新のGoogle p
 データ分析の加速がAIの隠されたボトルネックをどのように解決しているかApr 27, 2025 am 11:07 AM
データ分析の加速がAIの隠されたボトルネックをどのように解決しているかApr 27, 2025 am 11:07 AM高度なAI機能を取り巻く誇大宣伝にもかかわらず、エンタープライズAIの展開内に大きな課題が潜んでいます:データ処理ボトルネック。 CEOがAIの進歩を祝う間、エンジニアはクエリの遅い時間、過負荷のパイプライン、
 MarkitDown MCPは、任意のドキュメントをマークダウンに変換できます!Apr 27, 2025 am 09:47 AM
MarkitDown MCPは、任意のドキュメントをマークダウンに変換できます!Apr 27, 2025 am 09:47 AMドキュメントの取り扱いは、AIプロジェクトでファイルを開くだけでなく、カオスを明確に変えることです。 PDF、PowerPoint、Wordなどのドキュメントは、あらゆる形状とサイズでワークフローをフラッシュします。構造化された取得
 建物のエージェントにGoogle ADKを使用する方法は? - 分析VidhyaApr 27, 2025 am 09:42 AM
建物のエージェントにGoogle ADKを使用する方法は? - 分析VidhyaApr 27, 2025 am 09:42 AMGoogleのエージェント開発キット(ADK)のパワーを活用して、実際の機能を備えたインテリジェントエージェントを作成します。このチュートリアルは、ADKを使用して会話エージェントを構築し、GeminiやGPTなどのさまざまな言語モデルをサポートすることをガイドします。 w
 効果的な問題解決のためにLLMを介したSLMの使用 - 分析VidhyaApr 27, 2025 am 09:27 AM
効果的な問題解決のためにLLMを介したSLMの使用 - 分析VidhyaApr 27, 2025 am 09:27 AMまとめ: Small Language Model(SLM)は、効率のために設計されています。それらは、リソース不足、リアルタイム、プライバシーに敏感な環境の大手言語モデル(LLM)よりも優れています。 特にドメインの特異性、制御可能性、解釈可能性が一般的な知識や創造性よりも重要である場合、フォーカスベースのタスクに最適です。 SLMはLLMSの代替品ではありませんが、精度、速度、費用対効果が重要な場合に理想的です。 テクノロジーは、より少ないリソースでより多くを達成するのに役立ちます。それは常にドライバーではなく、プロモーターでした。蒸気エンジンの時代からインターネットバブル時代まで、テクノロジーの力は、問題の解決に役立つ範囲にあります。人工知能(AI)および最近では生成AIも例外ではありません
 コンピュータービジョンタスクにGoogle Geminiモデルを使用する方法は? - 分析VidhyaApr 27, 2025 am 09:26 AM
コンピュータービジョンタスクにGoogle Geminiモデルを使用する方法は? - 分析VidhyaApr 27, 2025 am 09:26 AMコンピュータービジョンのためのGoogleGeminiの力を活用:包括的なガイド 大手AIチャットボットであるGoogle Geminiは、その機能を会話を超えて拡張して、強力なコンピュータービジョン機能を網羅しています。 このガイドの利用方法については、
 Gemini 2.0 Flash vs O4-Mini:GoogleはOpenaiよりもうまくやることができますか?Apr 27, 2025 am 09:20 AM
Gemini 2.0 Flash vs O4-Mini:GoogleはOpenaiよりもうまくやることができますか?Apr 27, 2025 am 09:20 AM2025年のAIランドスケープは、GoogleのGemini 2.0 FlashとOpenaiのO4-Miniの到着とともに感動的です。 数週間離れたこれらの最先端のモデルは、同等の高度な機能と印象的なベンチマークスコアを誇っています。この詳細な比較


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

Dreamweaver Mac版
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

SAP NetWeaver Server Adapter for Eclipse
Eclipse を SAP NetWeaver アプリケーション サーバーと統合します。

MinGW - Minimalist GNU for Windows
このプロジェクトは osdn.net/projects/mingw に移行中です。引き続きそこでフォローしていただけます。 MinGW: GNU Compiler Collection (GCC) のネイティブ Windows ポートであり、ネイティブ Windows アプリケーションを構築するための自由に配布可能なインポート ライブラリとヘッダー ファイルであり、C99 機能をサポートする MSVC ランタイムの拡張機能が含まれています。すべての MinGW ソフトウェアは 64 ビット Windows プラットフォームで実行できます。

PhpStorm Mac バージョン
最新(2018.2.1)のプロフェッショナル向けPHP統合開発ツール
ホットトピック
 7753
7753 15164314139852129325123429
15164314139852129325123429