



機械学習アルゴリズムにおける特徴選択の問題には特定のコード例が必要です
機械学習の分野では、特徴選択はモデルの改善に役立つ非常に重要な問題です。精度とパフォーマンス。実際のアプリケーションでは、通常、データには多数の特徴があり、正確なモデルの構築に役立つのはそのうちの一部だけです。特徴の選択では、最も関連性の高い特徴を選択することで、特徴の次元を削減し、モデルの効果を向上させます。
特徴選択には多くの方法があります。以下では、一般的に使用されるいくつかの特徴選択アルゴリズムを紹介し、具体的なコード例を示します。
- 相関係数法:
相関係数法は、主に特徴と対象変数の間の相関を分析することによって特徴を選択します。特徴量とターゲット変数の間の相関係数を計算することで、どの特徴量がターゲット変数とより高い相関関係を持っているかを判断し、最も関連性の高い特徴量を選択できます。
具体的なコード例は次のとおりです:
import pandas as pd
import numpy as np
# 加载数据集
dataset = pd.read_csv('data.csv')
# 计算相关系数
correlation_matrix = dataset.corr()
# 获取相关系数大于阈值的特征
threshold = 0.5
correlation_features = correlation_matrix[correlation_matrix > threshold].sum()
# 打印相关系数大于阈值的特征
print(correlation_features)- カイ二乗検定法:
カイ二乗検定法は主に選択に使用されます。離散フィーチャと離散ターゲット変数間の相関。特徴とターゲット変数の間のカイ二乗値を計算することにより、特徴とターゲット変数の間に有意な相関があるかどうかを判断します。
具体的なコード例は次のとおりです:
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
# 加载数据集
dataset = pd.read_csv('data.csv')
X = dataset.iloc[:, :-1] # 特征
y = dataset.iloc[:, -1] # 目标变量
# 特征选择
select_features = SelectKBest(chi2, k=3).fit(X, y)
# 打印选择的特征
print(select_features.get_support(indices=True))- モデルベースの特徴選択メソッド:
モデルベースの特徴選択メソッドでは、主に Identify が選択されます。モデルのパフォーマンスに大きな影響を与える機能。デシジョン ツリー、ランダム フォレスト、サポート ベクター マシンなど、特徴選択のためにさまざまな機械学習モデルと組み合わせることができます。
具体的なコード例は次のとおりです。
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import RandomForestClassifier
# 加载数据集
dataset = pd.read_csv('data.csv')
X = dataset.iloc[:, :-1] # 特征
y = dataset.iloc[:, -1] # 目标变量
# 特征选择
select_features = SelectFromModel(RandomForestClassifier()).fit(X, y)
# 打印选择的特征
print(select_features.get_support(indices=True))機械学習アルゴリズムでは、特徴選択は高次元のデータ問題を解決するための一般的な方法です。最も関連性の高い特徴を選択することで、モデルの複雑さを軽減し、過剰適合のリスクを軽減し、モデルのパフォーマンスを向上させることができます。上記は一般的に使用される特徴選択アルゴリズムのサンプルコードですので、実際の状況に応じて適切な特徴選択方法を選択してください。
以上が機械学習アルゴリズムにおける特徴選択の問題の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 GoogleによるFirebase:カーソルやウィンドサーフよりも優れていますか? - 分析VidhyaApr 26, 2025 am 09:39 AM
GoogleによるFirebase:カーソルやウィンドサーフよりも優れていますか? - 分析VidhyaApr 26, 2025 am 09:39 AMFireBase Studio:AIを搭載したアプリ開発のための共同操縦団 アプリを構築して起動するクラウドベースのワークスペースを想像してみてください。これは、Googleのインテリジェントな開発環境であるFirebase Studioです。 ブレーンストーミングかr
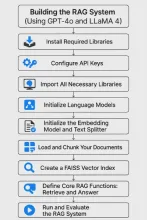 llama 4 vs. GPT-4o:ぼろきれに適しているのはどれですか?Apr 26, 2025 am 09:37 AM
llama 4 vs. GPT-4o:ぼろきれに適しているのはどれですか?Apr 26, 2025 am 09:37 AMこの記事では、MetaのLlama 4 ScoutとOpenaiのGPT-4oのパフォーマンスを検索された世代(RAG)システム内で比較します。 この評価は、Ragasフレームワークを利用して、忠実さ、回答の関連性、およびコンテキストのメトリックを提供します
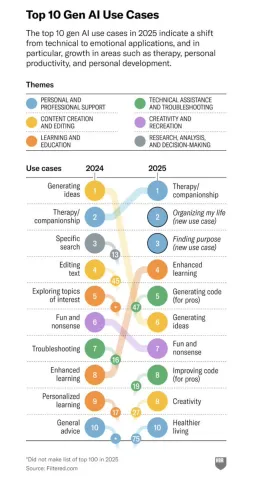 生成AIと人間のつながりの変革関係 - 分析vidhyaApr 26, 2025 am 09:36 AM
生成AIと人間のつながりの変革関係 - 分析vidhyaApr 26, 2025 am 09:36 AM2025:生成的AIは生産性ツールから個人的な仲間に進化します 生成AIの役割は2025年に劇的に拡大し、単純な生産性タスクを超えて個人的な生活の重要な存在になりました。その効率向上中
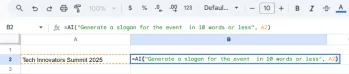 GoogleシートでGeminiを使用する方法は?Apr 26, 2025 am 09:34 AM
GoogleシートでGeminiを使用する方法は?Apr 26, 2025 am 09:34 AMGoogleシートは、Geminiの= AI関数の導入により、重要なアップグレードを取得し、以前に手動の努力を必要とするデータタスクを自動化します。このAIを搭載した式により、シンプルな分類、要約、および式の開発が簡素化されます
 Python One Linersデータクリーニング:クイックガイド - 分析VidhyaApr 26, 2025 am 09:33 AM
Python One Linersデータクリーニング:クイックガイド - 分析VidhyaApr 26, 2025 am 09:33 AMPython One-Linersで簡単にクリーニングしました 強力なPython One-Linersでデータクリーニングプロセスを合理化します!このガイドでは、欠損値、重複、問題のフォーマットなどを処理するための必須のパンダテクニックを紹介しています。
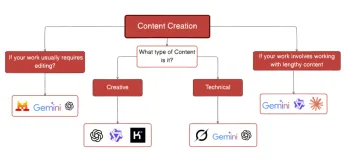 タスクに最適なAIチャットボットを選択するためのガイドApr 26, 2025 am 09:31 AM
タスクに最適なAIチャットボットを選択するためのガイドApr 26, 2025 am 09:31 AM最高の最新のLLMSをどのように追跡していますか?あなたがニュースを追跡しているなら、特にここ数ヶ月で、あなたはそこにあるモデルに圧倒されたと確信しています。今日、私たちはFIよりも多くのAIチャットボットを持っています
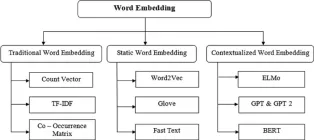 埋め込みの進化を定義する14の強力な手法 - 分析vidhyaApr 26, 2025 am 09:29 AM
埋め込みの進化を定義する14の強力な手法 - 分析vidhyaApr 26, 2025 am 09:29 AMこの記事では、単純なカウントベースの方法から洗練されたコンテキスト対応モデルまで、テキストの埋め込みの進化について説明します。 埋め込み性能と最先端のアクセシビリティを評価する際のMTEBのようなリーダーボードの役割を強調しています
 O3対O4 -Mini vs Gemini 2.5 Pro:究極の推論バトル-AnalyticsVidhyaApr 26, 2025 am 09:28 AM
O3対O4 -Mini vs Gemini 2.5 Pro:究極の推論バトル-AnalyticsVidhyaApr 26, 2025 am 09:28 AMこのブログは、厳密な推論課題で互いに並んでいる3つの主要なAIモデル(O3、O4-Mini、およびGemini 2.5 Pro)をピットします。 物理学、数学、コーディング、Webデザイン、画像分析にわたってそれらの能力をテストし、それらの強みを明らかにします


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

WebStorm Mac版
便利なJavaScript開発ツール

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

MinGW - Minimalist GNU for Windows
このプロジェクトは osdn.net/projects/mingw に移行中です。引き続きそこでフォローしていただけます。 MinGW: GNU Compiler Collection (GCC) のネイティブ Windows ポートであり、ネイティブ Windows アプリケーションを構築するための自由に配布可能なインポート ライブラリとヘッダー ファイルであり、C99 機能をサポートする MSVC ランタイムの拡張機能が含まれています。すべての MinGW ソフトウェアは 64 ビット Windows プラットフォームで実行できます。
ホットトピック
 7722
7722 15164214139652128925123329
15164214139652128925123329