



音声合成技術の流暢性の問題には特定のコード例が必要です
人工知能の発展に伴い、音声合成技術は仮想アシスタントなどさまざまな分野で広く使用されています。 、無人運転など。しかし、音声合成技術を使用すると、不自然な話す速度や途切れ途切れなど、流暢性が低いという問題が発生することがよくあります。この記事では、音声合成テクノロジにおける流暢性の問題について詳しく説明し、具体的なコード例を示します。
まず第一に、流暢さの問題の主な原因の 1 つはテキスト入力によって引き起こされます。場合によっては、テキストに長い文章、複雑な語彙、専門用語が含まれているため、音声合成システムがテキストを正確に処理できなくなることがあります。この問題を解決するには、テキスト処理アルゴリズムを使用して、長い文を短い文節に分割したり、複雑な単語を発音表記したりできます。以下は、Python を使用したサンプル コードです。
import nltk
def text_processing(text):
sentences = nltk.sent_tokenize(text) # 将文本分割为句子
processed_text = ""
for sentence in sentences:
words = nltk.word_tokenize(sentence) # 将句子分割为词语
for word in words:
phonetic = get_phonetic(word) # 获得词语的音标
processed_text += phonetic + " "
return processed_text
def get_phonetic(word):
# 在这里编写获取词语音标的代码
return phonetic
text = "我喜欢使用语音合成技术进行虚拟助手开发"
processed_text = text_processing(text)
print(processed_text)
上記のコードでは、テキスト処理に Natural Language Toolkit (NLTK) ライブラリを使用し、テキストを文に分割し、各単語のラベルを分割して音声化します。発音記号を取得するための特定の関数は、特定の音声合成システムおよび言語処理ライブラリに応じて実装する必要があります。
第二に、流暢さの問題は音声処理にも関連しています。音声合成システムによって生成される音声は、長すぎたり短すぎたりして、滑らかさが低下する場合があります。この問題を解決するには、音声処理アルゴリズムを使用して音声を高速化または低速化できます。以下は、Python を使用したサンプル コードです。
from pydub import AudioSegment
def audio_processing(audio_path):
audio = AudioSegment.from_file(audio_path, format="wav")
audio = audio.speedup(playback_speed=1.2) # 加速1.2倍
audio.export("processed_audio.wav", format="wav")
audio_path = "original_audio.wav"
audio_processing(audio_path)
上記のコードでは、オーディオ処理に PyDub ライブラリを使用し、オーディオ ファイルをロードして 1.2 倍に高速化し、最後に処理されたオーディオ ファイルをエクスポートします。もちろん、特定のオーディオ処理アルゴリズムは実際のニーズに応じて調整できます。
要約すると、音声合成技術における流暢性の問題は、非常に懸念される重要な問題であり、テキスト処理や音声処理などのアルゴリズムによって改善できます。上記では Python を使用したコード例を示していますが、具体的な実装は実際の状況に応じて調整する必要があります。この記事の内容が流暢さの問題の解決に役立つことを願っています。
以上が音声合成技術における流暢性の問題の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

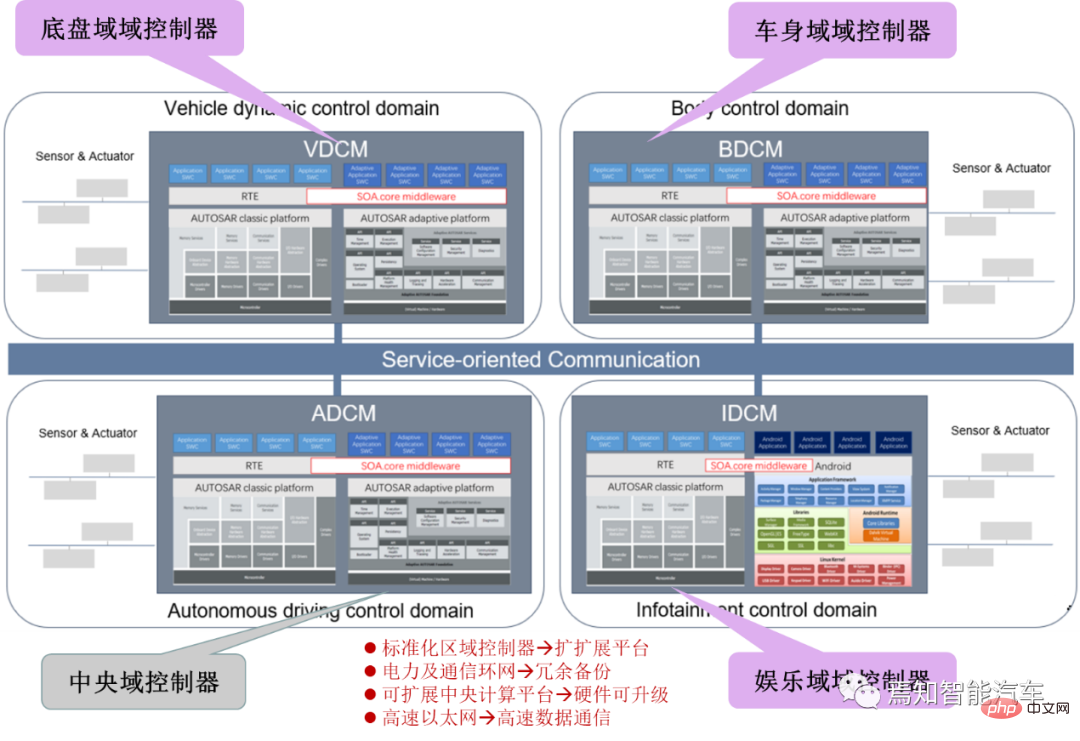 SOA中的软件架构设计及软硬件解耦方法论Apr 08, 2023 pm 11:21 PM
SOA中的软件架构设计及软硬件解耦方法论Apr 08, 2023 pm 11:21 PM对于下一代集中式电子电器架构而言,采用central+zonal 中央计算单元与区域控制器布局已经成为各主机厂或者tier1玩家的必争选项,关于中央计算单元的架构方式,有三种方式:分离SOC、硬件隔离、软件虚拟化。集中式中央计算单元将整合自动驾驶,智能座舱和车辆控制三大域的核心业务功能,标准化的区域控制器主要有三个职责:电力分配、数据服务、区域网关。因此,中央计算单元将会集成一个高吞吐量的以太网交换机。随着整车集成化的程度越来越高,越来越多ECU的功能将会慢慢的被吸收到区域控制器当中。而平台化
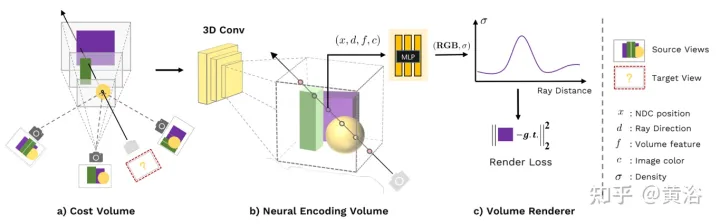 新视角图像生成:讨论基于NeRF的泛化方法Apr 09, 2023 pm 05:31 PM
新视角图像生成:讨论基于NeRF的泛化方法Apr 09, 2023 pm 05:31 PM新视角图像生成(NVS)是计算机视觉的一个应用领域,在1998年SuperBowl的比赛,CMU的RI曾展示过给定多摄像头立体视觉(MVS)的NVS,当时这个技术曾转让给美国一家体育电视台,但最终没有商业化;英国BBC广播公司为此做过研发投入,但是没有真正产品化。在基于图像渲染(IBR)领域,NVS应用有一个分支,即基于深度图像的渲染(DBIR)。另外,在2010年曾很火的3D TV,也是需要从单目视频中得到双目立体,但是由于技术的不成熟,最终没有流行起来。当时基于机器学习的方法已经开始研究,比
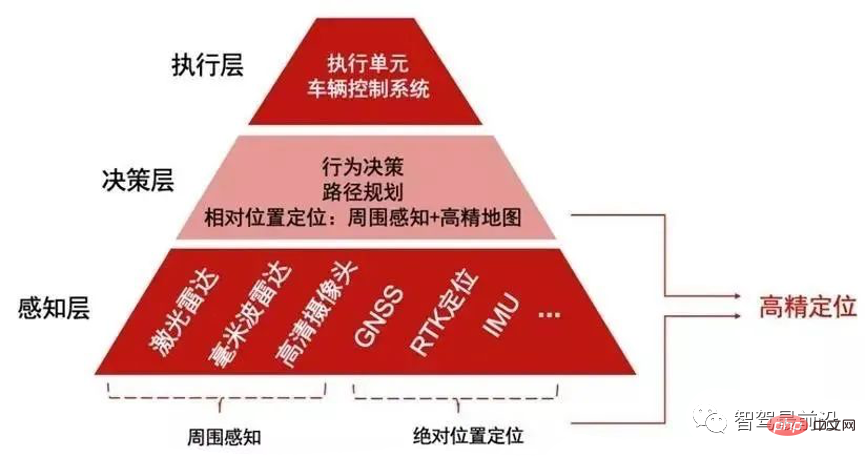 如何让自动驾驶汽车“认得路”Apr 09, 2023 pm 01:41 PM
如何让自动驾驶汽车“认得路”Apr 09, 2023 pm 01:41 PM与人类行走一样,自动驾驶汽车想要完成出行过程也需要有独立思考,可以对交通环境进行判断、决策的能力。随着高级辅助驾驶系统技术的提升,驾驶员驾驶汽车的安全性不断提高,驾驶员参与驾驶决策的程度也逐渐降低,自动驾驶离我们越来越近。自动驾驶汽车又称为无人驾驶车,其本质就是高智能机器人,可以仅需要驾驶员辅助或完全不需要驾驶员操作即可完成出行行为的高智能机器人。自动驾驶主要通过感知层、决策层及执行层来实现,作为自动化载具,自动驾驶汽车可以通过加装的雷达(毫米波雷达、激光雷达)、车载摄像头、全球导航卫星系统(G
 多无人机协同3D打印盖房子,研究登上Nature封面Apr 09, 2023 am 11:51 AM
多无人机协同3D打印盖房子,研究登上Nature封面Apr 09, 2023 am 11:51 AM我们经常可以看到蜜蜂、蚂蚁等各种动物忙碌地筑巢。经过自然选择,它们的工作效率高到叹为观止这些动物的分工合作能力已经「传给」了无人机,来自英国帝国理工学院的一项研究向我们展示了未来的方向,就像这样:无人机 3D 打灰:本周三,这一研究成果登上了《自然》封面。论文地址:https://www.nature.com/articles/s41586-022-04988-4为了展示无人机的能力,研究人员使用泡沫和一种特殊的轻质水泥材料,建造了高度从 0.18 米到 2.05 米不等的结构。与预想的原始蓝图
 超逼真渲染!虚幻引擎技术大牛解读全局光照系统LumenApr 08, 2023 pm 10:21 PM
超逼真渲染!虚幻引擎技术大牛解读全局光照系统LumenApr 08, 2023 pm 10:21 PM实时全局光照(Real-time GI)一直是计算机图形学的圣杯。多年来,业界也提出多种方法来解决这个问题。常用的方法包通过利用某些假设来约束问题域,比如静态几何,粗糙的场景表示或者追踪粗糙探针,以及在两者之间插值照明。在虚幻引擎中,全局光照和反射系统Lumen这一技术便是由Krzysztof Narkowicz和Daniel Wright一起创立的。目标是构建一个与前人不同的方案,能够实现统一照明,以及类似烘烤一样的照明质量。近期,在SIGGRAPH 2022上,Krzysztof Narko
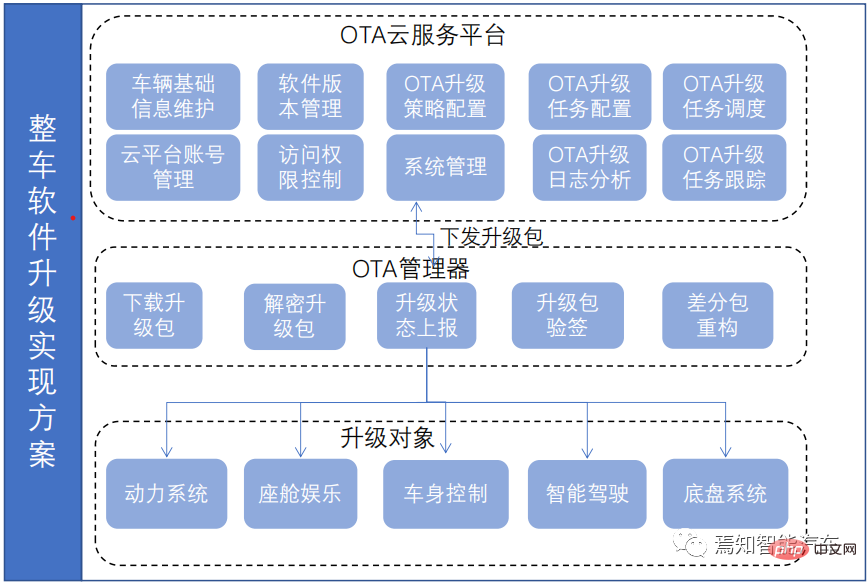 一文聊聊智能驾驶系统与软件升级的关联设计方案Apr 11, 2023 pm 07:49 PM
一文聊聊智能驾驶系统与软件升级的关联设计方案Apr 11, 2023 pm 07:49 PM由于智能汽车集中化趋势,导致在网络连接上已经由传统的低带宽Can网络升级转换到高带宽以太网网络为主的升级过程。为了提升车辆升级能力,基于为车主提供持续且优质的体验和服务,需要在现有系统基础(由原始只对车机上传统的 ECU 进行升级,转换到实现以太网增量升级的过程)之上开发一套可兼容现有 OTA 系统的全新 OTA 服务系统,实现对整车软件、固件、服务的 OTA 升级能力,从而最终提升用户的使用体验和服务体验。软件升级触及的两大领域-FOTA/SOTA整车软件升级是通过OTA技术,是对车载娱乐、导
 internet的基本结构与技术起源于什么Dec 15, 2020 pm 04:48 PM
internet的基本结构与技术起源于什么Dec 15, 2020 pm 04:48 PMinternet的基本结构与技术起源于ARPANET。ARPANET是计算机网络技术发展中的一个里程碑,它的研究成果对促进网络技术的发展起到了重要的作用,并未internet的形成奠定了基础。arpanet(阿帕网)为美国国防部高级研究计划署开发的世界上第一个运营的封包交换网络,它是全球互联网的始祖。
 综述:自动驾驶的协同感知技术Apr 08, 2023 pm 03:01 PM
综述:自动驾驶的协同感知技术Apr 08, 2023 pm 03:01 PMarXiv综述论文“Collaborative Perception for Autonomous Driving: Current Status and Future Trend“,2022年8月23日,上海交大。感知是自主驾驶系统的关键模块之一,然而单车的有限能力造成感知性能提高的瓶颈。为了突破单个感知的限制,提出协同感知,使车辆能够共享信息,感知视线之外和视野以外的环境。本文回顾了很有前途的协同感知技术相关工作,包括基本概念、协同模式以及关键要素和应用。最后,讨论该研究领域的开放挑战和问题


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

WebStorm Mac版
便利なJavaScript開発ツール

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境
ホットトピック
 7350
7350 15162814135352126525121429
15162814135352126525121429