




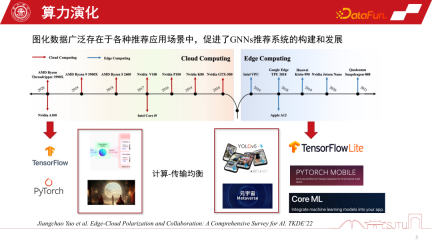
1. GNN レコメンデーション システムの基礎となるコンピューティング能力の進化
過去 20 年間、コンピューティング形式は進化し続けてきました。 2010 年以前は、クラウド コンピューティングが特に人気がありましたが、他のコンピューティング形式は比較的弱いものでした。ハードウェアのコンピューティング能力の急速な発展とエンドサイド チップの導入により、エッジ コンピューティングが特に重要になっています。現在の 2 つの主要なコンピューティング形式は、AI の開発を 2 つの二極化した方向に形成しています。一方で、クラウド コンピューティング アーキテクチャでは、超大規模クラスター機能を使用して、基盤モデルなどの大規模な AI モデルをトレーニングできます。またはいくつかの生成モデル。一方で、エッジコンピューティングの発展により、AIモデルを端末側に展開し、さまざまな認識タスクを端末側で実行するなど、より軽量なサービスを提供することも可能になります。同時に、メタバースの発展に伴い、多くのモデルの計算がエンド側に配置されるようになります。したがって、これら 2 つのコンピューティング形式が調和させたい中心的な問題は、コンピューティングと送信の間のバランスであり、その後、人工知能の二極化した発展が続きます。
2. エンドサイド GNN レコメンデーション システムのパーソナライゼーション
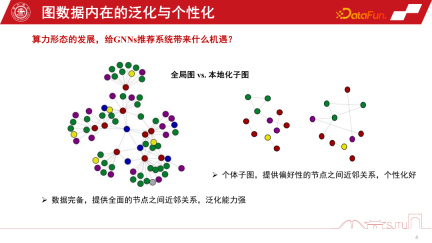
これら 2 つの計算フォームは GNN のレコメンデーション システムに機会をもたらしますか?
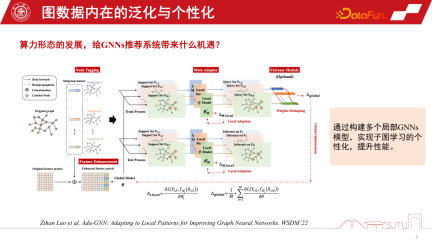
Duanyun の視点は、全体像と局所的なサブグラフの視点と比較できます。 GNN の推奨システムでは、グローバル サブグラフは、多くのノード レベルのサブグラフから継続的に収集されるグローバル サブグラフです。その利点は、データが完全であり、ノード間の比較的包括的な関係を提供できることです。この種の帰納的バイアスはより普遍的であり、さまざまなノードのルールを要約して帰納的バイアスを抽出するため、強い汎化能力を持っています。局所化されたサブグラフは必ずしも特に完全であるわけではありませんが、その利点は、サブグラフ上で個人の行動の進化を正確に記述し、個人化されたノード関係の確立を提供できることです。したがって、端末とクラウドの関係は、グローバル サブグラフとローカライズされたサブグラフに似ています。クラウド コンピューティングはサービスを提供するための強力な集中型コンピューティング能力を提供できますが、端末はいくつかのデータ パーソナライズされたサービスを提供できます
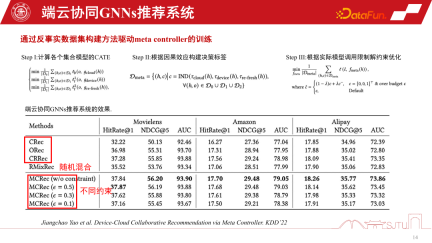
グローバル グラフとローカライズされたサブグラフの利点を組み合わせて、モデルのパフォーマンスについては、今年の WSDM2022 で発表された研究で調査されました。これは、グローバル グラフのグラフ モデリング全体を持ち、適応を行うためにサブグラフを使用していくつかのローカル モデルを構築する Ada-GNN (グラフ ニューラル ネットワークを改善するためのローカル パターンへの適応) モデルを提案します。このような適応の本質は、グローバル モデルとローカル モデルを組み合わせたモデルがローカル グラフのルールをより洗練された方法で認識できるようにし、個別化された学習パフォーマンスを向上させることです。
次に、特定の例を使用して、サブグラフに注意を払う必要がある理由を説明します。電子商取引の推奨システムには、携帯電話、パッド、カメラ、携帯電話周辺製品などのデジタル製品間の関係を説明できるデジタル愛好家のグループが存在します。彼がカメラの 1 つをクリックすると、誘導バイアスが引き起こされました。グループ貢献度マップによって引き起こされる帰納的バイアスマップは、この種の携帯電話を推奨するよう促すかもしれませんが、個人の視点に立ち返ると、その人が写真愛好家であり、写真製品に特別な注意を払っている場合、このようなパラドックスが生じることがあります。下に示された。グループ寄与マップによって引き起こされる帰納的バイアスは、特定のグループ、特に末尾グループに対して強すぎますか? これは、私たちがよくマシュー効果と呼ぶものです。

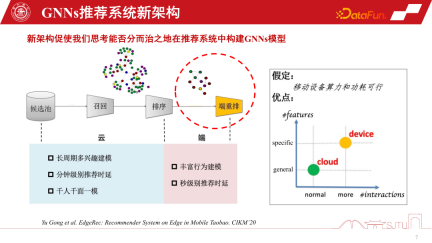
一般に、既存の二極化されたコンピューティング形式は、GNN 推奨システムのモデリングを再構築する可能性があります。従来のレコメンデーション システムは、候補プールから製品またはアイテムを呼び出し、GNN モデリングを通じてそれらの間の関係を認識し、ユーザーをランク付けして推奨します。ただし、エッジ コンピューティングのサポートにより、パーソナライゼーション モデルをエンド側に展開し、サブグラフで学習することでよりきめの細かいパーソナライゼーションを認識できます。もちろん、デバイスとクラウドのコラボレーションのためのこの新しい推奨システム アーキテクチャには、デバイスのコンピューティング能力と消費電力が実現可能であるという前提があります。しかし、実際には小型モデルの計算能力のオーバーヘッドは大きくなく、1~2メガバイトに圧縮して既存のスマートフォンに計算能力のオーバーヘッドを乗せれば、実際にはゲームアプリより多くの計算能力を消費することはありません。そして大きな電気エネルギー。したがって、エッジ コンピューティングのさらなる発展とエンド デバイスのパフォーマンスの向上により、エンド側でより多くの GNN モデリングが可能になる可能性が高まります。 GNN モデルを端末に配置したい場合は、端末の計算能力とストレージ容量を考慮する必要があります。先ほどモデル圧縮についても触れましたが、デバイス側で GNNs モデルをより効果的にしたい場合、比較的大きな GNNs モデルを配置する場合は、モデル圧縮を実行する必要があります。モデルの圧縮、枝刈り、量子化といった従来の方法は既存の GNN モデルで使用できますが、推奨システムのパフォーマンスの低下を引き起こします。このシナリオでは、デバイス側モデルを構築するためにパフォーマンスを犠牲にすることはできないため、プルーニングと量子化は便利ですが、その効果は限られています。
 もう 1 つの便利なモデル圧縮方法は蒸留です。数分の1しか削減できないかもしれませんが、コストは同様です。 KDD で発表された最近の研究は、GNN の蒸留に関するものです。 GNN では、グラフィカル データ モデリングの蒸留は、距離測定がロジット空間では簡単に定義できるが、潜在特徴空間では、特に教師 GNN と生徒 GNN の間のレイヤーごとの距離測定が簡単に定義できるという課題に直面しています。この点に関して、KDD に関するこの研究は、敵対的生成を通じてメトリクスを学習することで学習可能な設計を実現するソリューションを提供します。
もう 1 つの便利なモデル圧縮方法は蒸留です。数分の1しか削減できないかもしれませんが、コストは同様です。 KDD で発表された最近の研究は、GNN の蒸留に関するものです。 GNN では、グラフィカル データ モデリングの蒸留は、距離測定がロジット空間では簡単に定義できるが、潜在特徴空間では、特に教師 GNN と生徒 GNN の間のレイヤーごとの距離測定が簡単に定義できるという課題に直面しています。この点に関して、KDD に関するこの研究は、敵対的生成を通じてメトリクスを学習することで学習可能な設計を実現するソリューションを提供します。
#GNN のレコメンデーション システムでは、前述のモデル圧縮技術に加えて、分割デプロイは具体的で非常に便利な手法です。これは、GNN レコメンデーション システムのモデル アーキテクチャと密接に関連しています。これは、GNN の最下層が製品の項目埋め込みであり、MLP 非線形変換のいくつかの層の後、GNN の集約戦略が使用されるためです
モデルがトレーニングされると、当然の利点が得られます。基本層はすべて共有されており、カスタマイズできるのは GNN 層のみです。ここでパーソナライズする場合、モデルを2つの部分に分割し、モデルの公開部分をクラウドに置き、計算能力が十分であるため、パーソナライズ部分を端末上にデプロイできます。このようにして、中間カーネルの GNN を端末に保存するだけで済みます。実際のレコメンデーション システムでは、このアプローチによりモデル全体のストレージ オーバーヘッドを大幅に節約できます。アリババのシナリオで実践しましたが、分割デプロイ後のモデルはKBレベルに達する場合もありますが、さらに単純なビット量子化モデルを介してモデルを非常に小さくすることができ、端末に配置した際に特に大きなオーバーヘッドはほとんどありません。もちろん、これは経験に基づいた分割方法です。 KDD で公開されたファーウェイの最近の成果の 1 つは、端末機器のパフォーマンスを感知してこのモデルを自動的に分割できる自動モデル分割です。もちろん、GNN に適用する場合は、いくつかの再構成が必要になる可能性があります。
いくつかの深刻な配布転送シナリオにモデルをデプロイする場合、事前トレーニング済みモデルデバイスに展開される前は比較的古いものです。これは、実際のグラフ データがトレーニングのためにクラウドに戻る頻度が比較的遅く、場合によっては 1 週間かかる場合があるためです。
ここでの主なボトルネックは、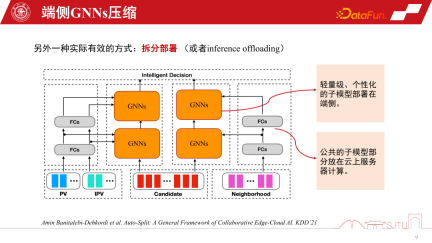 リソースの制約です。
リソースの制約です。
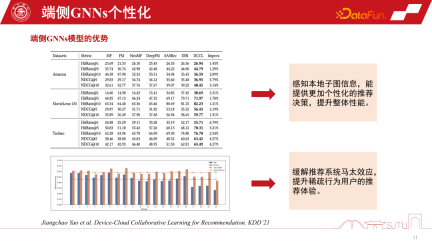
もう 1 つの課題はデータの疎性です。最終データには個々のノードしかないため、データの疎性も大きな課題です。最近の研究では、比較的効率的なアプローチである Parameter-Efficient Transfer を採用しており、層間にいくつかのモデル パッチを適用することで、残差ネットワークと比較することができますが、学習時にパッチを学習するだけで十分です。フラグ機構により使用中はオン、未使用時はオフが可能で、オフ時は元のベーシックモデルに縮退することができ、安全かつ効率的です。 これは、KDD2021 で公開された、より実用的で効率的なアプローチであり、GNN モデルのオンライン パーソナライゼーションを実現できます。最も重要なことは、このような実践から、このローカル モデルのサブグラフ情報をセンシングすることによって、全体のパフォーマンスが確かに着実に向上することができることを発見したことです。また、マシュー効果も軽減されます。 レコメンデーション システムでは、テール ユーザーは依然としてグラフ データに対するマシュー効果の問題に直面しています。ただし、分割統治モデリング アプローチを採用し、サブグラフをパーソナライズすれば、行動がまばらなユーザーのレコメンデーション エクスペリエンスを向上させることができます。特にテールクラウドの場合、パフォーマンスの向上はより顕著になります ユーザーの行動が突然非常にまばらになった状況では、推奨事項はより常識的な推論に依存します。これら 3 つの推奨動作を調整するために、GNN の推奨システムを調整するメタ コーディネーター - メタ コントローラーを確立できます。 3 方向のレコメンデーションを構築します。共存エンドクラウド 協調レコメンデーション システムの課題の 1 つは、データ セットの構築です。これは、これらのモデルを管理する方法や意思決定の方法がわからないためです。このようなデータセットはありませんが、単一チャネルのデータセットはあり、その因果関係を評価するための評価を通じていくつかの代理モデルを構築します。因果関係が比較的大きい場合、そのような決定を下すことによる利益は比較的大きくなり、疑似ラベル、つまり反事実のデータセットが構築される可能性があります。 1 つのチャネルには 3 つのモデル D0、D1、および D2 があります。メタコーディネーターをトレーニングするために、意思決定ラベルを構築し、反事実データセットを構築します。最後に、このメタ コーディネーターが各シングル チャネル モデルと比較して安定したパフォーマンス向上を示していることを証明できます。ランダムなヒューリスティックに比べて、大きな利点があります。このようにして、デバイスとクラウドの連携のための推奨システムを構築できます。 最後に、エンドサイド GNN 推奨システムのセキュリティ問題について説明します。デバイスとクラウドの協調 GNN レコメンデーション システムが公開されると、オープン環境では必然的に問題に直面することになります。学習用にモデルをパーソナライズする必要があるため、エスケープ攻撃、ポイズニング攻撃、バックドア攻撃などの攻撃のリスクがあり、最終的にレコメンデーション システムが大きなセキュリティ リスクに直面する可能性があります。 A1:子圖不是下發的,它其實是匯聚式的。第一點,子圖下發是伴隨式的。例如我們要做推薦商品的時候,它天然會攜帶商品的屬性資訊。這裡伴隨式的下發是跟屬性同等級的開銷,其實開銷不是很大。因為它不是把整個大圖都下發下來,只是一些鄰居子圖,至多二階的鄰居子圖還是非常小的。第二點,端上一部分子圖還是依賴於用戶行為的回饋做一些 co-occurrence 共點擊自動構建的,所以它是一個雙端匯聚的形式,總體開銷不是特別大。 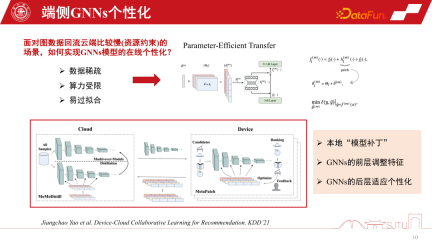
#3. ターミナルとクラウドの協調的な GNN レコメンデーション システムの実装
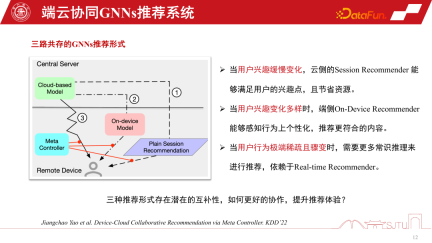
GNN 推奨システムには、クラウド側サービス用の GNN モデルとクライアント側用の小規模な GNN モデルがあります。 GNN のレコメンデーション システム サービスには 3 つの実装形式があります。1 つ目はセッション レコメンデーションであり、コストを節約するためのレコメンデーション システムで一般的なバッチ セッション レコメンデーションです。つまり、バッチ レコメンデーションが一度に作成され、ユーザーは事前に多くの製品を閲覧する必要があります。推奨が再びトリガーされます。 2 つ目は、極端な場合に一度に 1 つだけを推奨することです。 3 番目のタイプは、前述したエンドツーエンドのパーソナライズされたモデルです。これら 3 つのレコメンド システム方式にはそれぞれ利点があり、ユーザーの興味の変化が緩やかな場合にはクラウド側で正確に認識できればよいため、クラウド側モデルでセッション レコメンドを行うだけで十分です。ユーザーの興味がますます多様に変化する場合、エンドサイドのサブグラフのパーソナライズされた推奨により、推奨パフォーマンスを相対的に向上させることができます。
 基盤となるコンピューティング能力が、現在のクラウド連携 GNN レコメンデーション システムの方向性を推進しますが、まだ開発の初期段階にあり、潜在的な問題がいくつかあります。同時に、パーソナライズされたモデルの構築においても、モデリングの分野にはまだ多くの改善の余地があります。
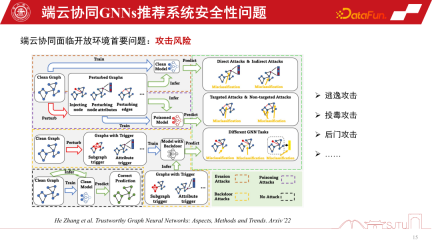
基盤となるコンピューティング能力が、現在のクラウド連携 GNN レコメンデーション システムの方向性を推進しますが、まだ開発の初期段階にあり、潜在的な問題がいくつかあります。同時に、パーソナライズされたモデルの構築においても、モデリングの分野にはまだ多くの改善の余地があります。 五、問答環節
Q1:在端上做圖模型,子圖的下發流量會不會太大?
以上がGNNs技術のレコメンドシステムへの応用とその実用化の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 AI内部展開の隠された危険:ガバナンスのギャップと壊滅的なリスクApr 28, 2025 am 11:12 AM
AI内部展開の隠された危険:ガバナンスのギャップと壊滅的なリスクApr 28, 2025 am 11:12 AMApollo Researchの新しいレポートによると、高度なAIシステムの未確認の内部展開は、重大なリスクをもたらします。 主要なAI企業の間で一般的なこの監視の欠如は、Uncontに及ぶ潜在的な壊滅的な結果を可能にします
 AIポリグラフの構築Apr 28, 2025 am 11:11 AM
AIポリグラフの構築Apr 28, 2025 am 11:11 AM従来の嘘検出器は時代遅れです。リストバンドで接続されたポインターに依存すると、被験者のバイタルサインと身体的反応を印刷する嘘発見器は、嘘を識別するのに正確ではありません。これが、嘘の検出結果が通常裁判所で採用されない理由ですが、多くの罪のない人々が投獄されています。 対照的に、人工知能は強力なデータエンジンであり、その実用的な原則はすべての側面を観察することです。これは、科学者がさまざまな方法で真実を求めるアプリケーションに人工知能を適用できることを意味します。 1つのアプローチは、嘘発見器のように尋問されている人の重要な符号応答を分析することですが、より詳細かつ正確な比較分析を行います。 別のアプローチは、言語マークアップを使用して、人々が実際に言うことを分析し、論理と推論を使用することです。 ことわざにあるように、ある嘘は別の嘘を繁殖させ、最終的に
 AIは航空宇宙産業の離陸のためにクリアされていますか?Apr 28, 2025 am 11:10 AM
AIは航空宇宙産業の離陸のためにクリアされていますか?Apr 28, 2025 am 11:10 AMイノベーションの先駆者である航空宇宙産業は、AIを活用して、最も複雑な課題に取り組んでいます。 近代的な航空の複雑さの増加は、AIの自動化とリアルタイムのインテリジェンス機能を必要とします。
 北京の春のロボットレースを見ていますApr 28, 2025 am 11:09 AM
北京の春のロボットレースを見ていますApr 28, 2025 am 11:09 AMロボット工学の急速な発展により、私たちは魅力的なケーススタディをもたらしました。 NoetixのN2ロボットの重量は40ポンドを超えており、高さは3フィートで、逆流できると言われています。 UnitreeのG1ロボットの重量は、N2のサイズの約2倍で、高さは約4フィートです。また、競争に参加している多くの小さなヒューマノイドロボットがあり、ファンによって前進するロボットさえあります。 データ解釈 ハーフマラソンは12,000人以上の観客を惹きつけましたが、21人のヒューマノイドロボットのみが参加しました。政府は、参加しているロボットが競争前に「集中トレーニング」を実施したと指摘したが、すべてのロボットが競争全体を完了したわけではない。 チャンピオン - 北京ヒューマノイドロボットイノベーションセンターによって開発されたティアンゴニ
 ミラートラップ:AI倫理と人間の想像力の崩壊Apr 28, 2025 am 11:08 AM
ミラートラップ:AI倫理と人間の想像力の崩壊Apr 28, 2025 am 11:08 AM人工知能は、現在の形式では、真にインテリジェントではありません。既存のデータを模倣して洗練するのに熟達しています。 私たちは人工知能を作成するのではなく、人工的な推論を作成しています。情報を処理するマシン、人間は
 新しいGoogleリークは、便利なGoogle写真機能の更新を明らかにしますApr 28, 2025 am 11:07 AM
新しいGoogleリークは、便利なGoogle写真機能の更新を明らかにしますApr 28, 2025 am 11:07 AMレポートでは、更新されたインターフェイスがGoogle Photos Androidバージョン7.26のコードに隠されていることがわかり、写真を見るたびに、新しく検出された顔のサムネイルの行が画面の下部に表示されます。 新しいフェイシャルサムネイルには名前タグが欠落しているため、検出された各人に関する詳細情報を見るには、個別にクリックする必要があると思います。今のところ、この機能は、Googleフォトが画像で見つけた人々以外の情報を提供しません。 この機能はまだ利用できないため、Googleが正確にどのように使用するかはわかりません。 Googleはサムネイルを使用して、選択した人のより多くの写真を見つけるためにスピードアップしたり、編集して個人を選択するなど、他の目的に使用することもできます。待って見てみましょう。 今のところ
 補強能力のガイド - 分析VidhyaApr 28, 2025 am 09:30 AM
補強能力のガイド - 分析VidhyaApr 28, 2025 am 09:30 AM補強能力は、人間のフィードバックに基づいて調整するためにモデルを教えることにより、AI開発を揺さぶりました。それは、監督された学習基盤と報酬ベースの更新をブレンドして、より安全で、より正確に、そして本当に助けます
 踊りましょう:私たちの人間のニューラルネットを微調整するための構造化された動きApr 27, 2025 am 11:09 AM
踊りましょう:私たちの人間のニューラルネットを微調整するための構造化された動きApr 27, 2025 am 11:09 AM科学者は、彼らの機能を理解するために、人間とより単純なニューラルネットワーク(C. elegansのものと同様)を広く研究してきました。 ただし、重要な疑問が生じます。新しいAIと一緒に効果的に作業するために独自のニューラルネットワークをどのように適応させるのか


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

SublimeText3 中国語版
中国語版、とても使いやすい

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

ドリームウィーバー CS6
ビジュアル Web 開発ツール

WebStorm Mac版
便利なJavaScript開発ツール

Safe Exam Browser
Safe Exam Browser は、オンライン試験を安全に受験するための安全なブラウザ環境です。このソフトウェアは、あらゆるコンピュータを安全なワークステーションに変えます。あらゆるユーティリティへのアクセスを制御し、学生が無許可のリソースを使用するのを防ぎます。
ホットトピック
 7807
7807 15164614140252130025123629
15164614140252130025123629