
ホームページ >テクノロジー周辺機器 >AI >Google: 不等周波数サンプリングによる時系列表現を学習する新しい方法
Google: 不等周波数サンプリングによる時系列表現を学習する新しい方法

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-10-05 16:53:061441ブラウズ
時系列問題には、同じ頻度でサンプリングされないタイプの時系列があります。つまり、各グループ内の 2 つの隣接する観測間の時間間隔が異なります。時系列表現の学習は、等周波数サンプリング時系列では多く研究されていますが、この不規則サンプリング時系列では研究が少なく、このタイプの時系列のモデル化方法は等周波数サンプリング時系列とは異なります。モデリング手法はまったく異なります
今日紹介する記事では、NLP および下流タスクでの関連経験を活用して、不規則サンプリング時系列問題における表現学習の応用手法を検討しています。比較的重要な結果が得られています。
 写真
写真
- 論文タイトル: PAITS: 不規則にサンプリングされた時系列の事前学習と拡張
- ダウンロード アドレス: https: //arxiv.org/pdf/2308.13703v1.pdf
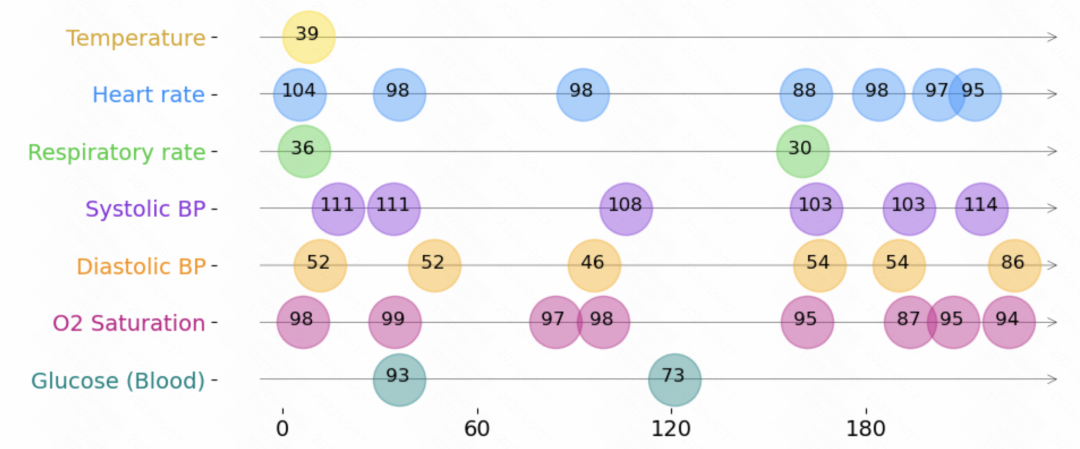
1. 不規則な時系列データの定義
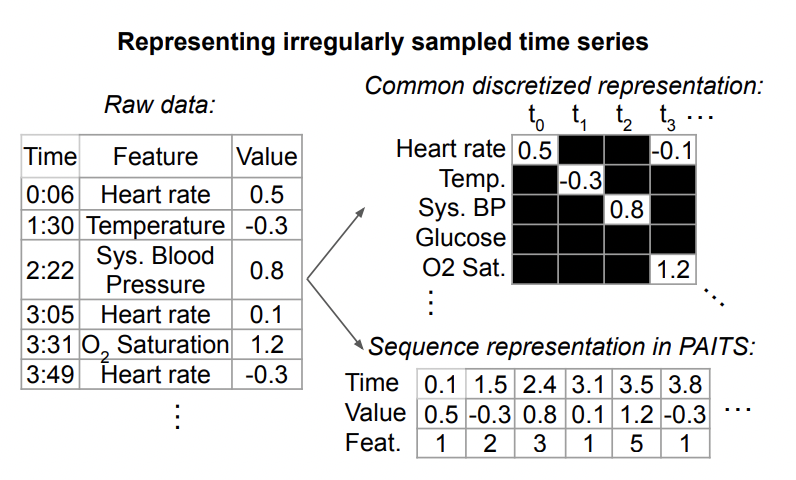
以下は、不規則な時系列データの表現です。 。各時系列は一連のトリプルで構成されており、各トリプルには時間、値、および特徴という 3 つのフィールドが含まれており、それぞれ時系列の各要素のサンプリング時間、値、その他の特徴を表します。これらのトリプルに加えて、各シーケンスには、時間の経過とともに変化しない他の静的特徴や、各時系列のラベルも含まれています。 # 一般に、この不規則時系列モデリング手法に共通する構造は、上記のトリプルデータを別々に埋め込み、それらをつなぎ合わせて、Transformer などのモデルに入力することにより、各瞬間の情報と各瞬間の時刻を解析します。表現は統合され、後続のタスクの予測を行うためにモデルに入力されます。
 図
図
この記事のタスクでは、使用されるデータにはラベル付きのデータだけでなく、ラベルのないデータも含まれます。教師なしの事前トレーニングを実行します。
2. メソッドの概要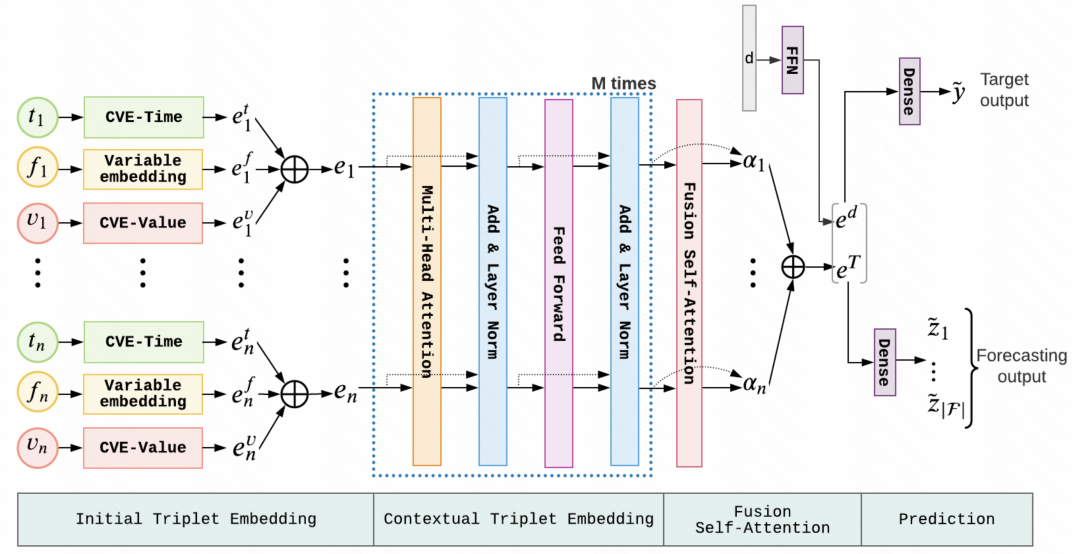 この記事の事前トレーニング メソッドは、自然言語処理の分野での経験に言及しており、主に 2 つの側面をカバーしています。事前トレーニング タスク: 不規則な時系列を処理するには、モデルが教師なしデータから効果的な表現を学習できるように、適切な事前トレーニング タスクを設計する必要があります。この記事では主に、予測と再構成に基づく 2 つの事前トレーニング タスクを紹介します。 .
この記事の事前トレーニング メソッドは、自然言語処理の分野での経験に言及しており、主に 2 つの側面をカバーしています。事前トレーニング タスク: 不規則な時系列を処理するには、モデルが教師なしデータから効果的な表現を学習できるように、適切な事前トレーニング タスクを設計する必要があります。この記事では主に、予測と再構成に基づく 2 つの事前トレーニング タスクを紹介します。 .
4. データ強化手法の設計
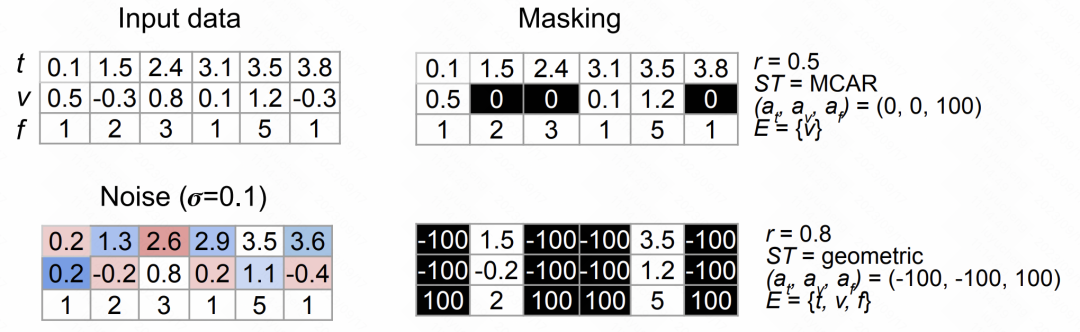
この記事では、2 つのデータ強化手法を提案します。 1 つ目の方法は、データにランダムな干渉を導入してノイズを追加し、データの多様性を高める方法です。 2 番目の方法はランダム マスキングです。これは、マスクするデータの部分をランダムに選択することで、モデルがより堅牢な特徴を学習することを促進します。これらのデータ拡張方法は、モデルのパフォーマンスと一般化能力を向上させるのに役立ちます。
元のシーケンスの各値または時点について、ガウス ノイズを追加することでノイズを増やすことができます。具体的な計算方法は以下の通りです。
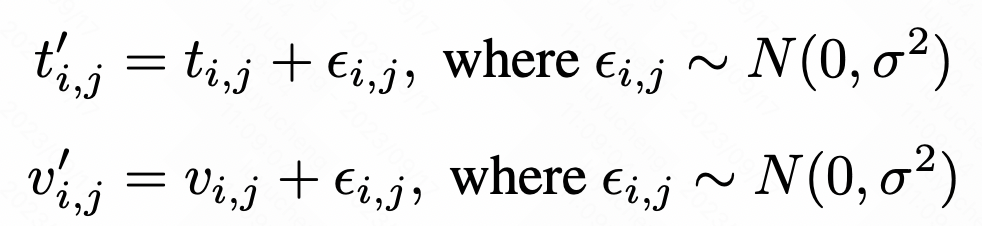 図
図
ランダム マスク手法は、ランダム マスキングと置換のために時間、特徴、値、その他の要素をランダムに選択し、順次強化していきます。
次の図は、上記の 2 種類のデータ拡張方法の効果を示しています。
 図
図
#さらに、この記事では、異なる時系列データに対して、学習方法などの組み合わせを変え、その組み合わせから最適な事前学習方法を探索します。
5. 実験結果
この記事では、これらのデータセットに対するさまざまな事前トレーニング方法の効果を比較するために、複数のデータセットに対して実験が行われました。この記事で提案されている事前トレーニング方法により、ほとんどのデータ セットでパフォーマンスが大幅に向上したことがわかります
# ###### ###写真### #################################### #
以上がGoogle: 不等周波数サンプリングによる時系列表現を学習する新しい方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。