
ホームページ >テクノロジー周辺機器 >AI >厄介なことに、ロボット犬はすでにこの能力を持っています
厄介なことに、ロボット犬はすでにこの能力を持っています

- 王林転載
- 2023-10-03 15:33:091149ブラウズ
単一のニューラル ネットワークを使用して操作を実現することは、四足ロボットの分野における大きな技術的進歩です
パルクールは参加が必要なエクストリーム スポーツですロボットは非常にダイナミックな方法で障害物を乗り越えることができます。ほとんどの場合「不器用」なロボットにとって、これは手の届かないもののように思えますが、ロボット制御の分野では最近いくつかの技術的進歩の傾向が見られます。数週間前、このサイトでは、強化学習手法を使用してロボット犬にパルクールを実現し、良好な結果を達成した研究について報告しました。 最近、カーネギー メロン大学 (CMU) によって行われた新しい研究では、ロボット犬のパルクールに挑戦するための驚くべき新しい方法が提案され、その効果は人々が「素晴らしい」と評価するまでにさらに改善されました
カーネギーでの研究メロン大学は、ロボット犬が障害物コースの競技者のように不連続なボックスを自動的に横切り、異なる角度で傾斜した斜面の間を簡単に走ったりジャンプしたりできるようにしました






- プロジェクトアドレス: https://github.com/chengxuxin/extreme-parkour
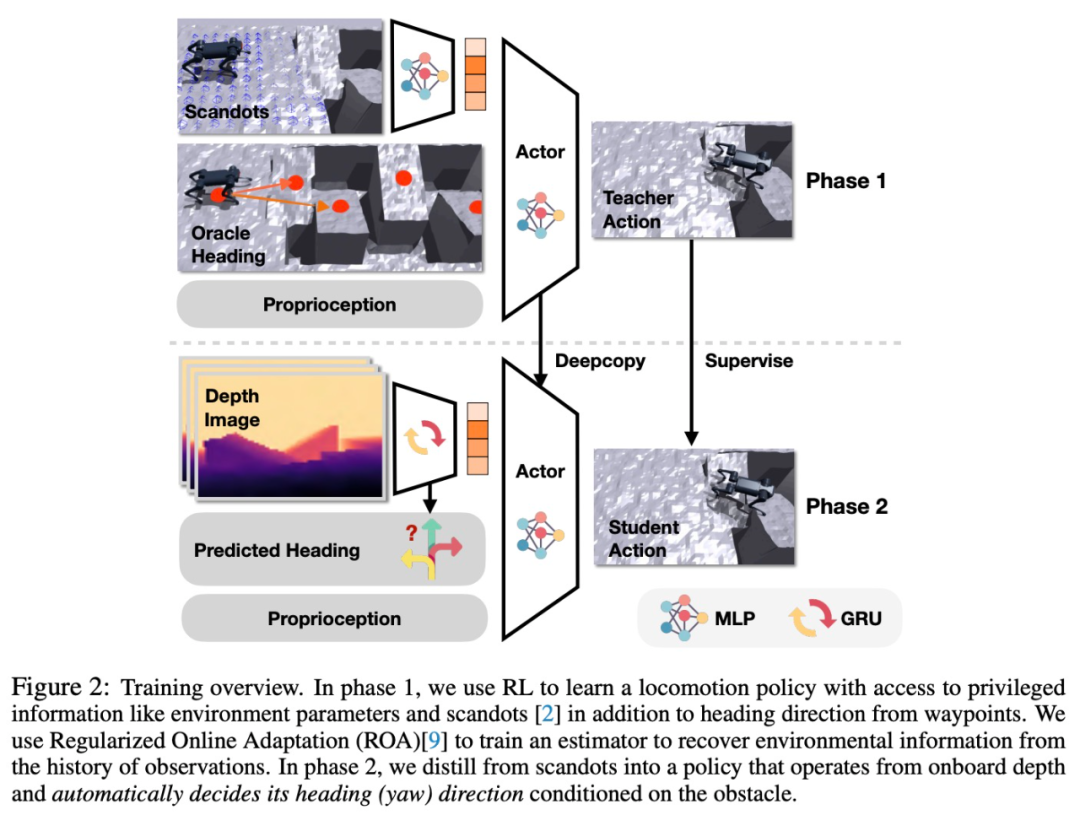
- 方法の紹介 この研究では、エンドツーエンドのデータ駆動型強化学習フレームワークを使用して、ロボット犬に「パルクール」能力を備えさせます。ロボット犬が展開時に障害物の種類に応じて自己調整できるようにするために、この研究では新しい二重蒸留方法を提案します。この戦略は、柔軟なモーション コマンドを出力できるだけでなく、入力された深度画像に応じて方向を迅速に調整することもできます。
#単一のニューラル ネットワークでさまざまなパルクール スキルの動作を表現できるようにするために、この研究では、内積に基づいたシンプルで効果的な普遍的な報酬設計原理を提案します。 具体的には、この研究は、生の深度およびオンボードセンシングから関節角度コマンドまで直接ニューラルネットワークをトレーニングすることを目的としています。適応的な動作戦略を訓練するために、この研究では、極端なパルクール タスクに重要な修正を加えた正規化オンライン適応 (ROA) 手法を採用しました。
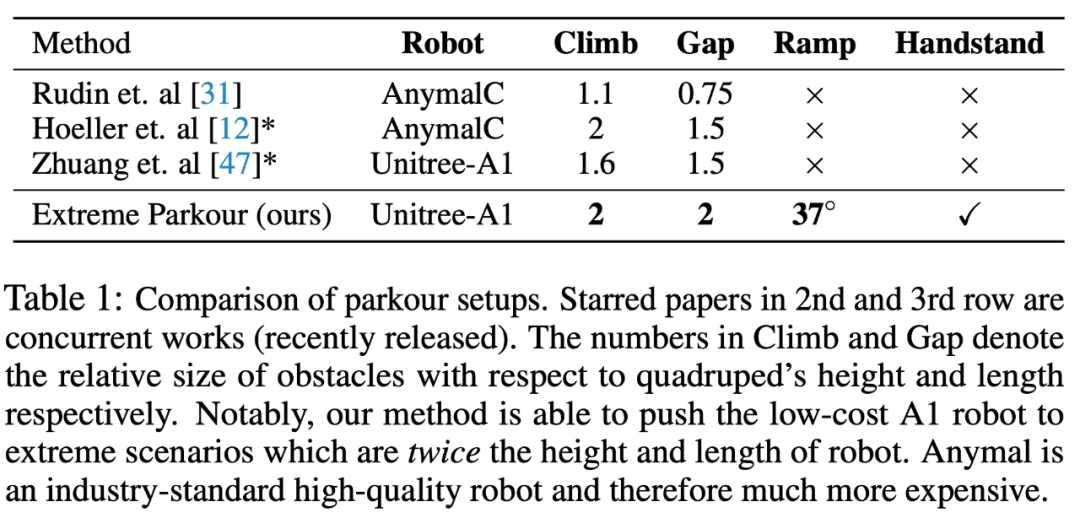
この研究の目標は、ロボット犬によじ登る、段差を飛び越える、坂道で走ったり跳んだり、立つという4技能を習得させることです。逆さまに。以下の表 1 は、他のいくつかの方法との比較結果を示しています
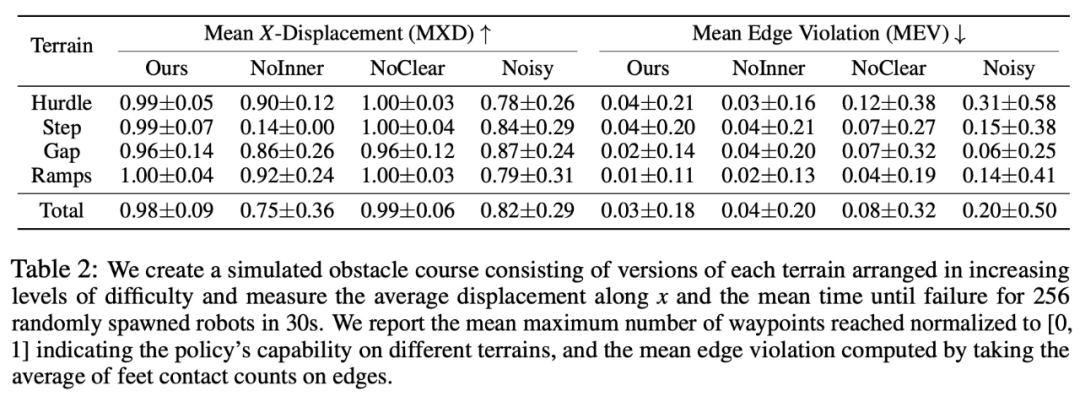
システム内の各部分の役割を検証するために、調査では 2 つのベースライン セットが提案されました。この研究では、最初に報酬設計と全体的なプロセスをテストしました。その結果を以下の表 2 に示します。
2 番目のベースライン セットの目的は、蒸留設定をテストすることです。 、方向予測BCやアクション用のダガーに使用されるものが含まれます。実験結果を表 3 に示します

#さらに、この研究では実際の実験も多数実施し、成功率を記録し、NoClear と比較しました。および NoDir ベースライン。実験結果を図 7 に示します。
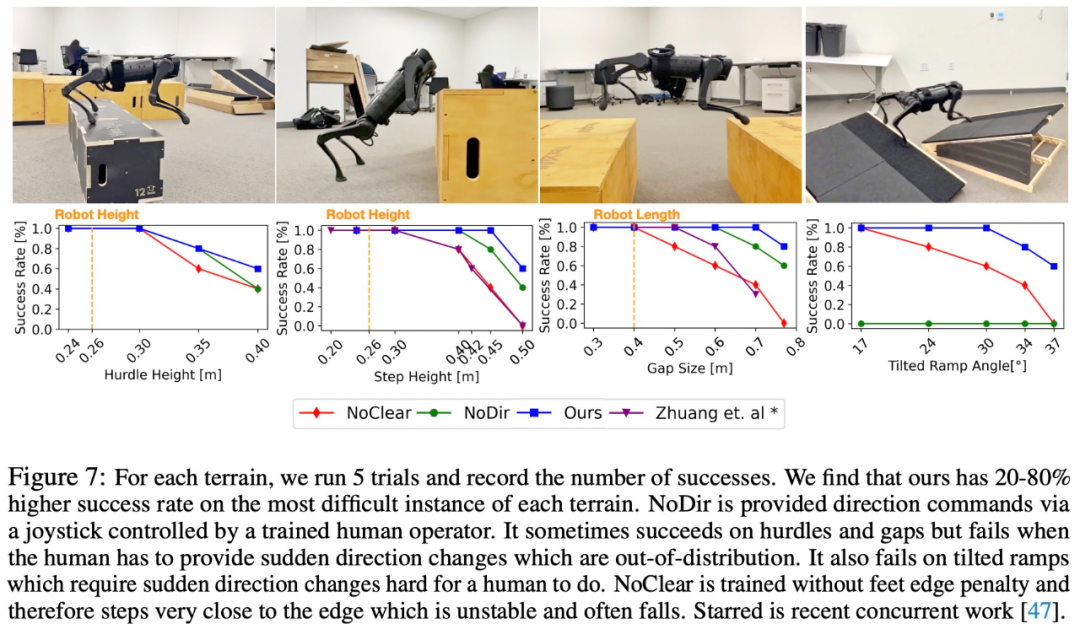
#興味のある読者は論文の原文を読んで、研究内容についてさらに詳しく知ることができます。
以上が厄介なことに、ロボット犬はすでにこの能力を持っていますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。