
ホームページ >テクノロジー周辺機器 >AI >対数スペクトログラムに基づく深層学習心音分類
対数スペクトログラムに基づく深層学習心音分類

- PHPz転載
- 2023-09-29 17:21:081603ブラウズ
この論文は非常に興味深いもので、心音信号の対数スペクトログラムに基づいた 2 つの心拍音分類モデルを提案しています。スペクトログラムが音声認識で広く使用されていることは誰もが知っています。この論文では、心音信号を音声信号として処理し、良好な結果を達成しています
心音信号を同じ長さのフレームに分割し、その対数スペクトログラム特徴を抽出します。抽出された特徴に基づいて心拍音を分類するために、長短期記憶 (LSTM) と畳み込みニューラル ネットワーク (CNN) という 2 つの深層学習モデルが使用されます。
心音データセット
画像診断には、心臓磁気共鳴画像法 (MRI)、CT スキャン、心筋灌流画像法が含まれます。これらのテクノロジーの欠点も明らかです。最新の機械と専門家に対する高い要件と、長い診断時間です。
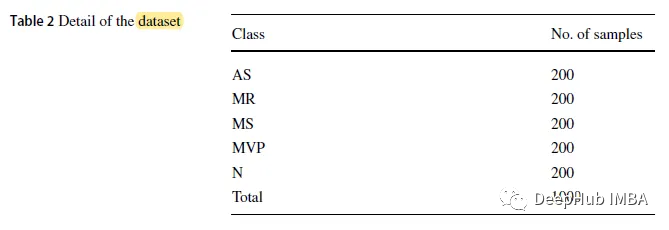
この論文で使用されているデータ セットは公開データ セットであり、サンプリング周波数 8 kHz の .wav 形式の 1000 個の信号サンプルが含まれています。 。データセットは、1 つの正常カテゴリー (N) と、大動脈弁狭窄症 (AS)、僧帽弁逆流 (MR)、僧帽弁狭窄症 (MS)、および僧帽弁閉鎖不全症 (MR) の 4 つの異常カテゴリーを含む 5 つのカテゴリーに分割されています。 )
大動脈弁狭窄症 (AS) は、大動脈弁が小さすぎる、狭い、または硬すぎる場合です。大動脈弁狭窄症の典型的な雑音は、高音の「ダイヤモンド形」の雑音です。
僧帽弁閉鎖不全症 (MR) は、心臓の僧帽弁が適切に閉じることができず、血液が送り出されずに心臓に逆流してしまう状態です。胎児の心臓を聴診する場合、雑音の音量が S2 までに増加するまで、S1 音は非常に低い (場合によっては大きくなる) ことがあります。 S3
僧帽弁狭窄症 (MS) は、僧帽弁が損傷し、完全に開くことができない状態です。心音の聴診により、初期の僧帽弁狭窄症ではS1が悪化し、重度の僧帽弁狭窄症ではS1が柔らかくなることがわかります。肺高血圧症が進行すると、S2音が強調されます。純粋な MS 患者には左心室 S3 がほとんどありません。
僧帽弁逸脱(MVP)は、心臓の収縮中に僧帽弁の小葉が左心房内に脱出することです。 MVP は通常良性ですが、僧帽弁閉鎖不全症、心内膜炎、臍帯破裂などの合併症を引き起こす可能性があります。兆候には、収縮期中期のクリック音と収縮期後期の雑音 (逆流がある場合) が含まれます。
前処理と特徴抽出
音声信号の長さは異なります。したがって、サンプルレートは録音ファイルごとに固定する必要があります。音声信号に少なくとも 1 つの完全な心拍周期が含まれるようにするために、長さをトリミングします。成人の心拍数は 1 分間に 65 ~ 75 回であり、心拍周期は約 0.8 秒であるという事実に基づいて、信号サンプルを 2.0 秒、1.5 秒、1.0 秒のセグメントに分割しました。 #離散フーリエリーフ変換 (DFT) に基づいて、心音信号の元の波形を対数スペクトログラムに変換します。音声信号のDFT y(k)は式(1)であり、対数スペクトルsは式(2)のように定義されます。
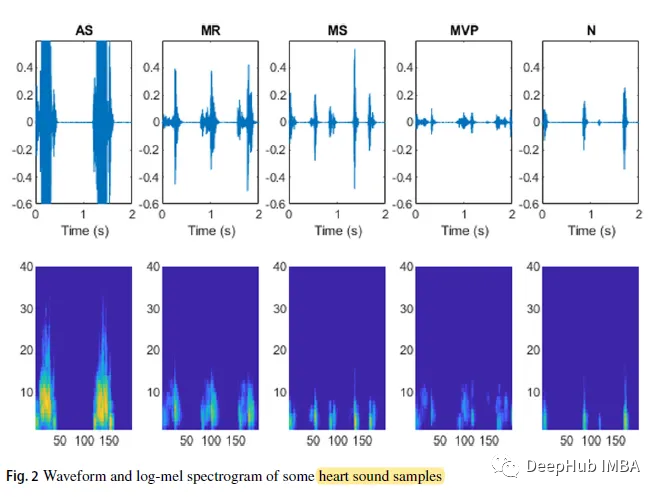
#式では、N はベクトル x の長さ、ε = 10^(- 6) は小さなオフセットです。いくつかの心音サンプルの波形と対数スペクトログラムは次のとおりです。
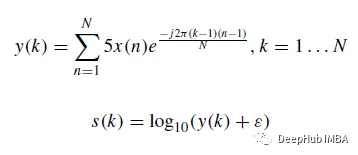
深層学習モデル
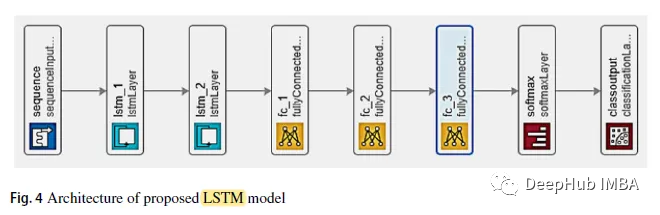
1. LSTM
LSTM モデルは、2 層の直接接続と、それに続く 3 層の完全接続で設計されています。 3 番目の完全に接続された層は、ソフトマックス分類器を入力します。
2. CNN モデル
上の図に示すように、最初の 2 つの畳み込み層の後最大プーリング層が重なっています。 3 番目の畳み込み層は、最初の全結合層に直接接続されています。 2 番目の全結合層は、5 つのクラス ラベルを持つソフトマックス分類器に供給されます。各畳み込み層の後に BN と ReLU を使用します
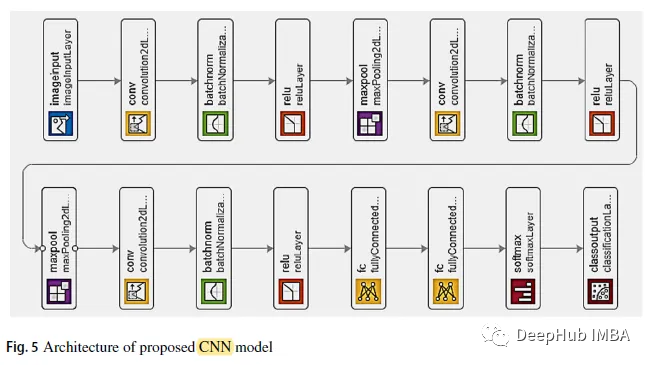
3、トレーニングの詳細
結果
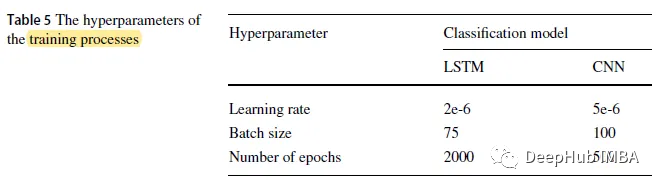
#トレーニング セットはデータ セット全体の 70% を占め、テスト セットには残りの部分が含まれます
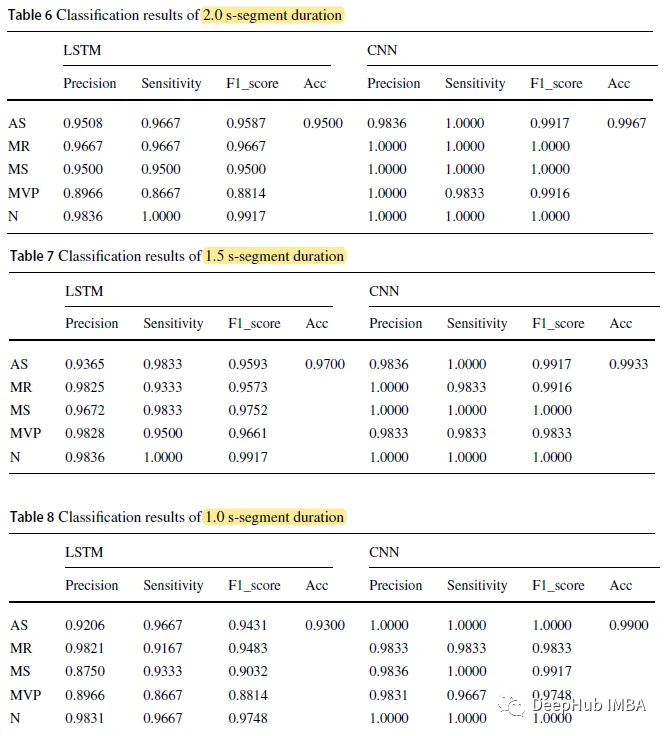
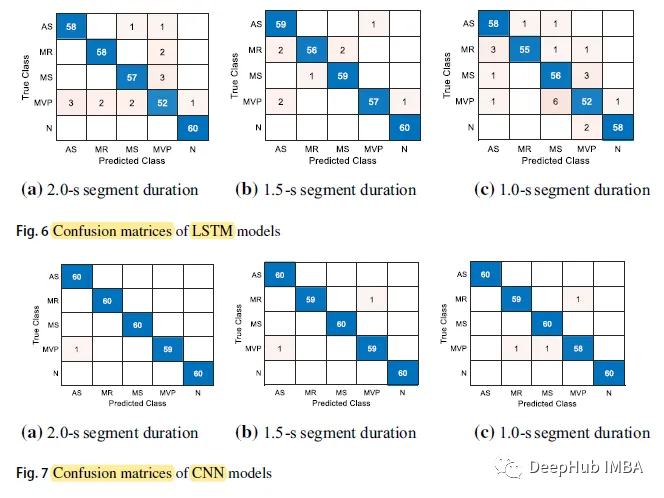
CNN モデルの全体的な精度はそれぞれ 0.9967、0.9933、0.9900 で、セグメント期間はそれぞれ 2.0 秒、1.5 秒、1.0 秒ですが、LSTM モデルの 3 つの数値は 0.9500、0.9700、0.9300 です。 各期間における CNN モデルの予測精度は、LSTM モデルの予測精度よりも高くなります。 以下は混同行列です。 N クラス (ノーマル) の予測精度が最も高く、5 つのケースで 60 に達しますが、MVP クラスの予測精度はすべての中で最も低くなります。ケース。 LSTM モデルの入力時間長は 2.0 秒、最大予測時間は 9.8631 ミリ秒です。分類時間が 1.0 秒の CNN モデルの予測時間は 4.2686 ミリ秒と最も短くなります。 他の SOTA と比較して、一部の研究は非常に高い精度を持っていますが、これらの研究には 2 つのカテゴリ (正常と異常) のみが含まれており、私たちの研究は5 つのカテゴリに分類されます 同じデータセット (0.9700) を使用した他の研究と比較して、論文研究は大幅に改善されており、最高精度は 0.9967 でした。 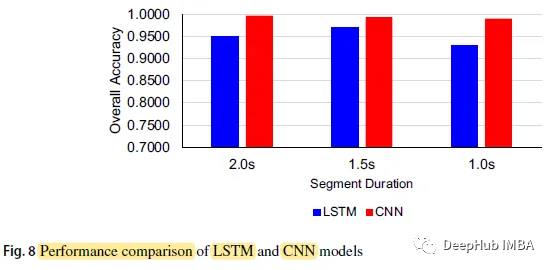

以上が対数スペクトログラムに基づく深層学習心音分類の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。