



NLP 用 Python: 複数列のデータを含む PDF テキストを処理するにはどうすればよいですか?
概要:
自然言語処理 (NLP) の発展により、PDF テキストの処理は非常に重要なタスクになりました。ただし、PDF テキストに複数列のデータが含まれる場合、その処理はより複雑になります。この記事では、Python を使用して複数列のデータを含む PDF テキストを処理し、有用な情報を抽出し、適切なデータ処理を実行する方法を紹介します。
ステップ 1: 必要なライブラリをインストールする
まず、PDF テキストの処理を容易にするために必要な Python ライブラリをいくつかインストールする必要があります。これらのライブラリには pdfplumber と pandas が含まれます。これらは、次のコマンドを使用してインストールできます。
pip install pdfplumber pandas
ステップ 2: 必要なライブラリをインポートする
実際のコードの作成を開始する前に、必要なライブラリをインポートする必要があります。次のコマンドを実行して、pdfplumber ライブラリと pandas ライブラリをインポートできます。
import pdfplumber import pandas as pd
ステップ 3: PDF ファイルを読み取ってテキストを抽出します
次に、PDF ファイルを読み取ってテキストを抽出する必要があります。 PDF ファイルは、pdfplumber ライブラリの pdfplumber.open() 関数を使用して開き、すべてのテキストは extract_text() メソッドを使用して抽出できます。以下に簡単な例を示します。
with pdfplumber.open('multi_column_data.pdf') as pdf:
text = ""
for page in pdf.pages:
text += page.extract_text()ステップ 4: テキストを DataFrame に変換する
テキストを抽出した後、処理に適したデータ構造に変換する必要があります。 PDF テキストには複数のデータ列が含まれているため、pandas ライブラリの DataFrame を使用してこのデータを処理できます。テキストを DataFrame に変換する例を次に示します。
data = pd.DataFrame([row.split('
') for row in text.split('
') if row.strip() != '']) 上記のコードでは、split() メソッドを使用してテキストを行ごとに分割し、split('
') List を使用して各行をさらに分割しています。 。また、split('
')を使用してデータを行間で分割し、判定条件を使用して空白行を削除します。
ステップ 5: データの処理とクリーニングを行う
テキストを DataFrame に変換したので、データの処理とクリーニングを開始できます。複数列のデータを処理する場合、pandas が提供するさまざまなメソッドや関数を使用して処理できます。一般的なデータ処理操作の例をいくつか示します。
-
特定の列を選択します:
selected_data = data[[0, 1]]
-
列の名前を変更します:
data.columns = ['Column1', 'Column2']
-
欠損値のある行の削除:
data.dropna(inplace=True)
-
データ型の変換:
data['Column1'] = data['Column1'].astype(int)
ステップ 6: データの保存
最後のステップは、処理されたデータを保存することです。 pandas ライブラリが提供する to_csv() メソッドを使用してデータを CSV ファイルとして保存することも、to_excel() メソッドを使用してデータを Excel ファイルとして保存することもできます。データを CSV ファイルとして保存する例を次に示します。
data.to_csv('processed_data.csv', index=False) 概要:
Python で pdfplumber ライブラリと pandas ライブラリを使用すると、複数列のデータを含む PDF テキストを簡単に処理できます。まず、pdfplumber ライブラリを使用してテキストを抽出し、処理に適したデータ構造に変換します。次に、データの処理とクリーニングに pandas ライブラリを使用します。最後に、処理されたデータを CSV または Excel ファイルとして保存できます。この記事が、複数列のデータを含む PDF テキストを処理する簡単かつ効果的な方法を提供することを願っています。
以上がNLP 用 Python: 複数列のデータを含む PDF テキストを処理するには?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 如何利用Python for NLP将PDF文件中的文本进行翻译?Sep 28, 2023 pm 01:13 PM
如何利用Python for NLP将PDF文件中的文本进行翻译?Sep 28, 2023 pm 01:13 PM如何利用PythonforNLP将PDF文件中的文本进行翻译?随着全球化的进程日益加深,跨语言翻译的需求也越来越大。而PDF文件作为一种常见的文档形式,其中可能包含了大量的文本信息。如果我们想将PDF文件中的文字内容进行翻译,可以运用Python的自然语言处理(NLP)技术来实现。本文将介绍一种利用PythonforNLP进行PDF文本翻译的方法,并
 如何利用Python for NLP处理PDF文件中的表格数据?Sep 27, 2023 pm 03:04 PM
如何利用Python for NLP处理PDF文件中的表格数据?Sep 27, 2023 pm 03:04 PM如何利用PythonforNLP处理PDF文件中的表格数据?摘要:自然语言处理(NaturalLanguageProcessing,简称NLP)是一个涉及计算机科学和人工智能领域的重要领域,而处理PDF文件中的表格数据是NLP中一个常见的任务。本文将介绍如何使用Python和一些常用的库来处理PDF文件中的表格数据,包括提取表格数据、数据预处理和转换
 Python for NLP:如何处理包含多个章节的PDF文件?Sep 27, 2023 pm 08:55 PM
Python for NLP:如何处理包含多个章节的PDF文件?Sep 27, 2023 pm 08:55 PMPythonforNLP:如何处理包含多个章节的PDF文件?在自然语言处理(NLP)任务中,我们常常需要处理包含多个章节的PDF文件。这些文件往往是学术论文、小说、技术手册等,每个章节都有其特定的格式和内容。本文将介绍如何使用Python处理这类PDF文件,并提供具体的代码示例。首先,我们需要安装一些Python库来帮助我们处理PDF文件。其中最常用的是
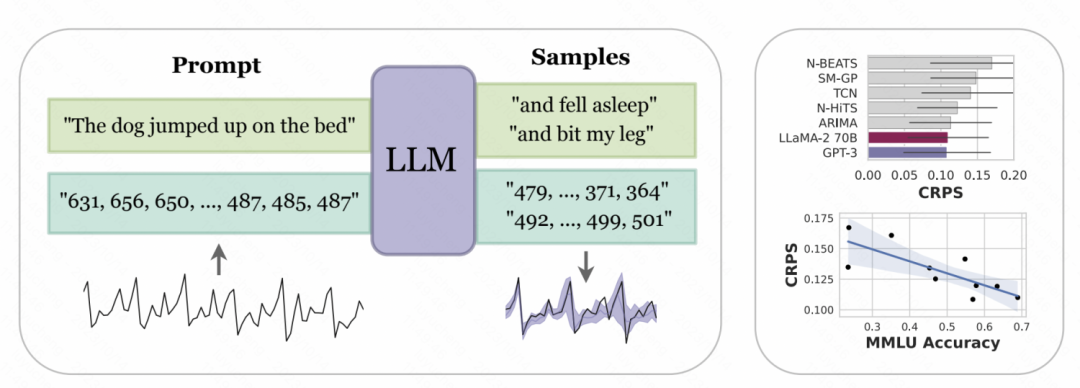 一篇学会大模型浪潮下的时间序列预测Nov 06, 2023 am 08:13 AM
一篇学会大模型浪潮下的时间序列预测Nov 06, 2023 am 08:13 AM今天跟大家聊一聊大模型在时间序列预测中的应用。随着大模型在NLP领域的发展,越来越多的工作尝试将大模型应用到时间序列预测领域中。这篇文章介绍了大模型应用到时间序列预测的主要方法,并汇总了近期相关的一些工作,帮助大家理解大模型时代时间序列预测的研究方法。1、大模型时间序列预测方法最近三个月涌现了很多大模型做时间序列预测的工作,基本可以分为2种类型。重写后的内容:一种方法是直接使用NLP的大型模型进行时间序列预测。在这种方法中,使用GPT、Llama等NLP大型模型来进行时间序列预测,关键在于如何将
 Python for NLP:如何从PDF文件中提取并分析脚注和尾注?Sep 28, 2023 am 11:45 AM
Python for NLP:如何从PDF文件中提取并分析脚注和尾注?Sep 28, 2023 am 11:45 AMPythonforNLP:如何从PDF文件中提取并分析脚注和尾注引言:自然语言处理(NLP)是计算机科学和人工智能领域中的一个重要研究方向。PDF文件作为一种常见的文档格式,在实际应用中经常遇到。本文介绍如何使用Python从PDF文件中提取并分析脚注和尾注,为NLP任务提供更全面的文本信息。文章将结合具体的代码示例进行介绍。一、安装和导入相关库要实现从
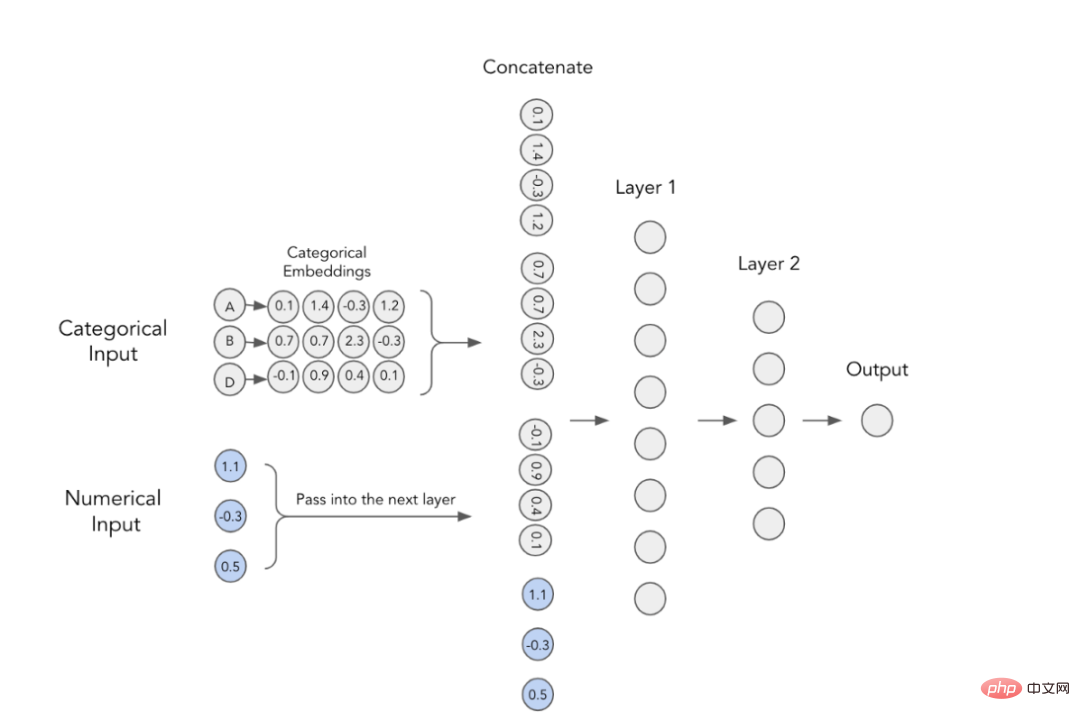 TabTransformer转换器提升多层感知机性能深度解析Apr 17, 2023 pm 03:25 PM
TabTransformer转换器提升多层感知机性能深度解析Apr 17, 2023 pm 03:25 PM如今,转换器(Transformers)成为大多数先进的自然语言处理(NLP)和计算机视觉(CV)体系结构中的关键模块。然而,表格式数据领域仍然主要以梯度提升决策树(GBDT)算法为主导。于是,有人试图弥合这一差距。其中,第一篇基于转换器的表格数据建模论文是由Huang等人于2020年发表的论文《TabTransformer:使用上下文嵌入的表格数据建模》。本文旨在提供该论文内容的基本展示,同时将深入探讨TabTransformer模型的实现细节,并向您展示如何针对我们自己的数据来具体使用Ta
 Python for NLP:如何处理包含大量超链接的PDF文本?Sep 28, 2023 am 10:09 AM
Python for NLP:如何处理包含大量超链接的PDF文本?Sep 28, 2023 am 10:09 AMPythonforNLP:如何处理包含大量超链接的PDF文本?引言:在自然语言处理(NLP)领域中,处理PDF文本是常见的任务之一。然而,当PDF文本中包含大量超链接时,会给处理带来一定的挑战。本文将介绍使用Python处理包含大量超链接的PDF文本的方法,并提供具体的代码示例。安装依赖库首先,我们需要安装两个依赖库:PyPDF2和re。PyPDF2用于
 用Python for NLP快速处理文本PDF文件的技巧Sep 28, 2023 am 11:57 AM
用Python for NLP快速处理文本PDF文件的技巧Sep 28, 2023 am 11:57 AM用PythonforNLP快速处理文本PDF文件的技巧随着数字化时代的到来,大量的文本数据以PDF文件的形式存储。对这些PDF文件进行文本处理,以提取信息或进行文本分析是自然语言处理(NLP)中的一个关键任务。本文将介绍如何使用Python来快速处理文本PDF文件,并提供具体的代码示例。首先,我们需要安装一些Python库来处理PDF文件和文本数据。主要


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

Safe Exam Browser
Safe Exam Browser は、オンライン試験を安全に受験するための安全なブラウザ環境です。このソフトウェアは、あらゆるコンピュータを安全なワークステーションに変えます。あらゆるユーティリティへのアクセスを制御し、学生が無許可のリソースを使用するのを防ぎます。

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

