
ホームページ >テクノロジー周辺機器 >AI >SupFusion: Lidar とカメラが融合した 3D 検出ネットワークを効果的に監視する方法を模索していますか?
SupFusion: Lidar とカメラが融合した 3D 検出ネットワークを効果的に監視する方法を模索していますか?

- 王林転載
- 2023-09-28 21:41:071427ブラウズ
LiDAR カメラ フュージョンに基づく 3D 検出は、自動運転にとって重要なタスクです。近年、多くの LIDAR カメラ フュージョン手法が登場し、優れたパフォーマンスを達成していますが、これらの手法には常に、適切に設計され、効果的に監視されたフュージョン プロセスが欠けています。
この記事では、補助機能を提供する SupFusion と呼ばれる新しいトレーニング戦略を紹介します。 -LIDAR カメラフュージョンのレベル監視により、検出パフォーマンスが大幅に向上します。この方法には、まばらなターゲットを暗号化し、補助モデルをトレーニングして監視用の高品質な特徴を生成するためのポーラー サンプリング データ拡張方法が含まれています。これらの機能は、LIDAR カメラ フュージョン モデルをトレーニングし、融合されたフィーチャを最適化して高品質のフィーチャの生成をシミュレートするために使用されます。さらに、シンプルでありながら効果的な深層融合モジュールが提案されており、SupFusion戦略を使用した以前の融合方法と比較して優れたパフォーマンスを継続的に達成します。この論文の方法には次の利点があります。 まず、SupFusion は補助的な特徴レベルの監視を導入します。これにより、追加の推論コストを増加させることなく、LIDAR カメラの検出パフォーマンスを向上させることができます。第二に、提案されている深層融合により、検出器の機能を継続的に向上させることができます。提案された SupFusion およびディープ フュージョン モジュールはプラグ アンド プレイであり、この論文では広範な実験を通じてその有効性を実証しています。複数の LIDAR カメラに基づく 3D 検出の KITTI ベンチマークでは、3D mAP が約 2% 向上しました。
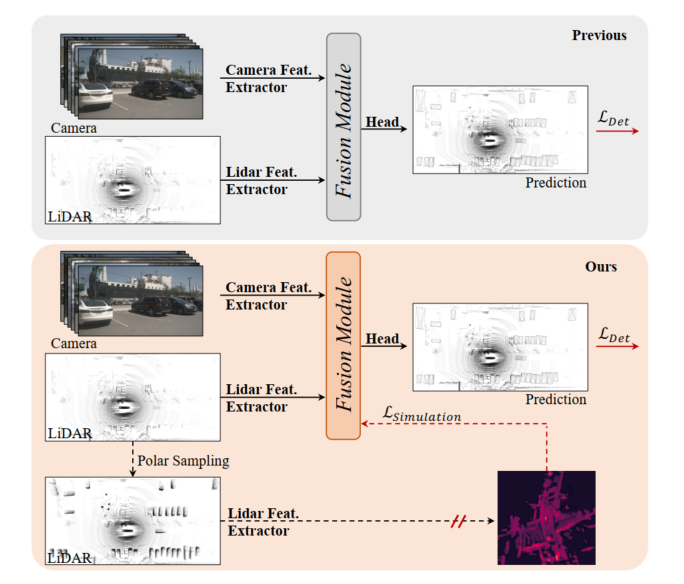
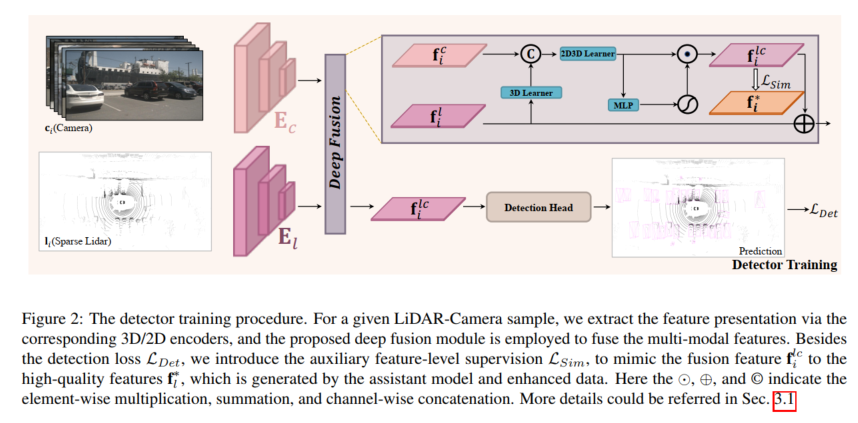
図 1: 上、以前の LIDAR カメラ 3D 検出モデル、フュージョン モジュールは検出損失によって最適化されています。下: この記事で提案されている SupFusion は、補助モデルによって提供される高品質な機能を通じて補助監視を導入します。
LiDAR カメラ フュージョンに基づく 3D 検出は、自動運転とロボット工学において重要かつ困難なタスクです。以前の方法では、常にカメラ入力を LIDAR BEV またはボクセル空間に投影して、LIDAR とカメラの機能を調整していました。次に、単純な連結または合計を使用して、最終的な検出用の融合された特徴が取得されます。さらに、いくつかの深層学習ベースの融合手法は、有望なパフォーマンスを達成しています。ただし、以前の融合手法は常に、検出損失を通じて 3D/2D 特徴抽出および融合モジュールを直接最適化しており、特徴レベルでの注意深い設計と効果的な監視が不足しており、パフォーマンスが制限されています。
近年、蒸留法により、3D 検出の特徴レベルの監視が大幅に改善されました。一部のメソッドは、カメラ入力に基づいて深度情報を推定するように 2D バックボーンをガイドする LIDAR 機能を提供します。さらに、一部のメソッドは、LIDAR バックボーンを監視して LIDAR 入力からグローバルおよびコンテキスト表現を学習する LIDAR カメラ フュージョン機能を提供します。より堅牢で高品質な機能をシミュレートすることで機能レベルの補助監視を導入することで、検出器はわずかな改善を促進できます。これにヒントを得て、LIDAR カメラの機能の融合を処理する自然なソリューションは、より強力で高品質の機能を提供し、LIDAR カメラの 3D 検出に補助監視を導入することです。
LIDAR カメラに基づくフュージョン 3D 検出のパフォーマンスを向上させるために、この記事では SupFusion と呼ばれる教師あり LIDAR カメラ フュージョン手法を提案します。この方法では、高品質の特徴を生成し、融合および特徴抽出プロセスを効果的に監視することでこれを実現します。まず、高品質の機能を提供するために補助モデルをトレーニングします。より大きなモデルや追加データを利用する以前の方法とは異なり、ポーラー サンプリングと呼ばれる新しいデータ拡張方法を提案します。極サンプリングは、まばらな LIDAR データからターゲットの密度を動的に高めて、ターゲットを検出しやすくし、正確な検出結果などのフィーチャの品質を向上させます。次に、LIDAR カメラ フュージョンに基づいて検出器をトレーニングし、補助機能レベルの監視を導入します。このステップでは、生の LIDAR とカメラの入力を 3D/2D バックボーンと融合モジュールに入力して、融合されたフィーチャを取得します。融合された特徴は最終予測のために検出ヘッドに供給され、補助監視は融合された特徴を高品質の特徴にモデル化します。これらの特徴は、事前トレーニングされた補助モデルと強化された LIDAR データを通じて取得されます。このようにして、提案された特徴レベルの監視により、融合モジュールがより堅牢な特徴を生成し、検出パフォーマンスをさらに向上させることができます。 LIDAR とカメラの機能をより適切に融合するために、スタックされた MLP ブロックとダイナミック フュージョン ブロックで構成される、シンプルで効果的なディープ フュージョン モジュールを提案します。 SupFusion はディープ フュージョン モジュールの機能を最大限に活用し、検出精度を継続的に向上させることができます。
この記事の主な貢献:
- 新しい教師付き融合トレーニング戦略 SupFusion を提案しました。これは主に高品質の特徴生成プロセスで構成され、堅牢な融合特徴抽出と正確な 3D 検出損失のための補助的な特徴レベルの監視を初めて提案しました。
- SupFusion で高品質の特徴を取得するために、まばらなターゲットを暗号化する「極性サンプリング」と呼ばれるデータ拡張手法が提案されています。さらに、検出精度を継続的に向上させるために、効果的な深層融合モジュールが提案されています。
- 異なる融合戦略を備えた複数の検出器に基づいて広範な実験が実施され、KITTI ベンチマークで約 2% の mAP 改善が得られました。
提案手法
高品質な特徴生成プロセスを次の図に示します。任意の LiDAR サンプルに対して、スパース暗号化は、polar によって実行されます。ターゲット、極ペーストでは、データベースから密なターゲットをクエリするために方向と回転を計算し、ペーストを通じて疎なターゲットに追加のポイントを追加します。この論文では、まず強化されたデータを使用して補助モデルをトレーニングし、強化された LIDAR データを補助モデルにフィードして、収束後に高品質の特徴 f* を生成します。
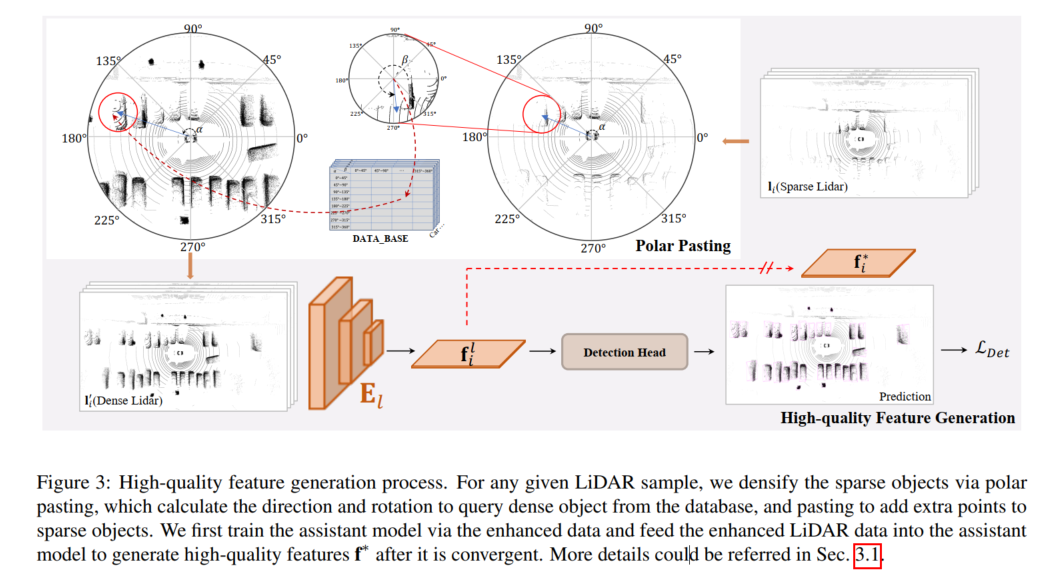
高品質の特徴生成
SupFusion で機能レベルの監視を提供するために、補助モデルを採用して高品質の特徴を生成します。 -図 3 に示すように、品質の特徴がデータに取り込まれます。まず、高品質の機能を提供するために補助モデルがトレーニングされます。 D のサンプルについては、まばらな LIDAR データが拡張され、極ペーストによって強化されたデータが取得されます。これにより、極グループ化で生成されたポイントのセットを追加することで代替ターゲットが暗号化されます。次に、補助モデルが収束した後、強化されたサンプルが最適化された補助モデルに入力され、LIDAR カメラの 3D 検出モデルをトレーニングするための高品質の特徴がキャプチャされます。特定の LIDAR カメラ検出器により適切に適用し、実装を容易にするために、ここでは単に LIDAR 分岐検出器を補助モデルとして採用します。
検出器トレーニング
任意の LIDAR カメラ検出器について、モデルは、特徴レベルで提案された補助監視を使用してトレーニングされます。サンプル 、 が与えられると、LIDAR とカメラはまず 3D および 2D エンコーダーに入力され、対応するフィーチャをキャプチャします。これらのフィーチャはフュージョン モデルに入力されてフュージョン フィーチャを生成し、検出ヘッドに流れます。最終予想用に。さらに、提案された補助監視は、事前トレーニングされた補助モデルと強化された LIDAR データから生成された高品質の特徴と融合した特徴をシミュレートするために使用されます。上記のプロセスは次のように定式化できます。
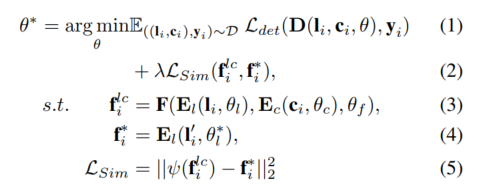
極サンプリング
高品質の機能を提供するために、この文書では次のように説明します。提案された SupFusion 検出失敗の原因となることが多いスパース性の問題に対処するための、Polar Sampling と呼ばれる新しいデータ拡張方法。この目的を達成するために、密なターゲットを処理する方法と同様に、LIDAR データ内の疎なターゲットの密な処理を実行します。極座標サンプリングは、極座標のグループ化と極座標の貼り付けの 2 つの部分で構成されます。極座標グループ化では、主に密なターゲットを保存するデータベースを構築します。これは極座標の貼り付けに使用され、疎なターゲットがより密になるようにします。
LIDAR センサーの特性を考慮すると、収集された点群データは当然のことながら、特定の密度分布。たとえば、オブジェクトの LIDAR センサーに面する表面にはより多くのポイントがあり、反対側にはより少ないポイントがあります。密度分布は主に方向と回転によって影響を受けますが、点の密度は主に距離に依存します。 LIDAR センサーに近いオブジェクトほど、ポイントの密度が高くなります。これに触発されて、この論文の目標は、疎なターゲットの方向と回転に従って、長距離の疎なターゲットと近距離の密なターゲットを高密度化し、密度分布を維持することです。シーンの中心と特定のターゲットに基づいて、シーン全体とターゲットの極座標系を確立し、LIDAR センサーの正の方向を 0 度と定義して、対応する方向と回転を測定します。次に、同様の密度分布を持つ (たとえば、同様の方向と回転を持つ) ターゲットを収集し、極グループ化のグループごとに密なターゲットを生成し、これを極ペーストで使用して高密度の疎なターゲットに使用します
極グループ化
図 4 に示すように、極グループ化の方向と回転に従って、生成された密オブジェクト点集合 l を格納するデータベース B がここで構築されます。
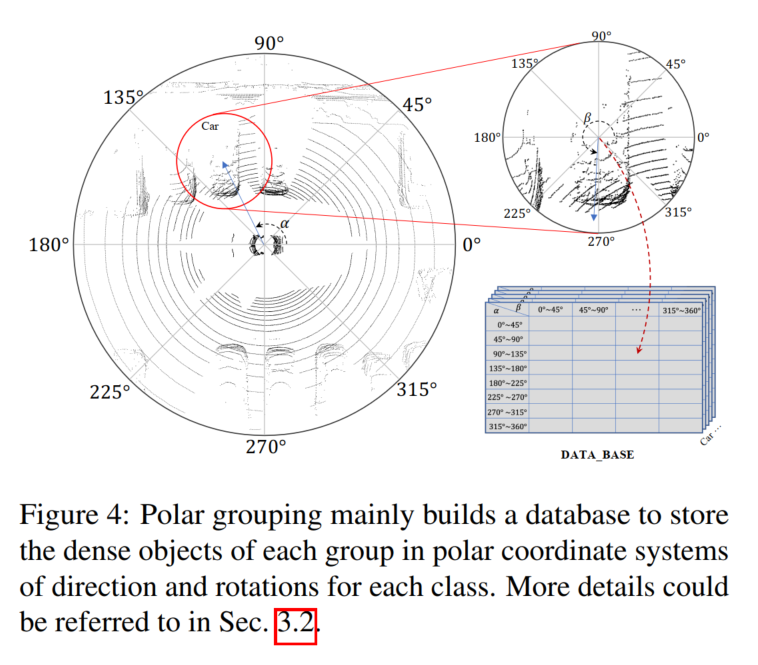
まず、データセット全体が検索され、すべてのターゲットの極角が位置によって計算され、回転がデータムに提供されます。次に、極角に基づいてターゲットをグループに分割します。向きと回転を手動で N 個のグループに分割し、任意のターゲット ポイント セット l をインデックスに従って対応するグループに入れることができます。
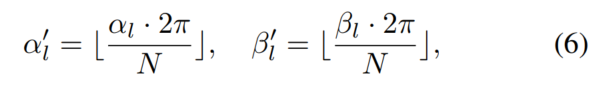
極貼り付け
図 2 に示すように、極貼り付けは、まばらな LIDAR データを強化して補助モデルをトレーニングし、高解像度を生成するために使用されます。品質特性。 LiDAR サンプル ,,,, にターゲットが含まれているとすると、任意のターゲットについて、グループ化プロセスと同じ方向と回転を計算でき、ラベルとインデックスに基づいて B の密なターゲットをクエリできます。式6から取得できます。 強化されたサンプル内のすべてのターゲットを取得し、強化されたデータを取得します。
ディープ フュージョン
強化された LiDAR データによって生成された高品質の特徴をシミュレートするために、フュージョン モデルは以下から生成するように設計されています。カメラ入力 豊富な色とコンテキスト特徴からまばらなオブジェクトの欠落情報を抽出します。この目的を達成するために、この論文では、画像の特徴を利用し、完全な LIDAR のデモンストレーションを行うためのディープ フュージョン モジュールを提案します。提案された深層融合は主に 3D 学習器と 2D-3D 学習器で構成されます。 3D ラーナーは、3D レンダリングを 2D 空間に転送するために使用される単純な畳み込み層です。次に、2D 機能と 3D レンダリング (たとえば、2D 空間内) を接続するために、2D-3D 学習器を使用して LiDAR カメラ機能を融合します。最後に、融合されたフィーチャは MLP およびアクティベーション関数によって重み付けされ、ディープ フュージョン モジュールの出力として元の LIDAR フィーチャに再度追加されます。 2D-3D 学習器は、深さ K の積み重ねられた MLP ブロックで構成され、カメラ機能を活用して疎なターゲットの LIDAR 表現を完成させ、密な LIDAR ターゲットの高品質な特徴をシミュレートする方法を学習します。
実験比較分析
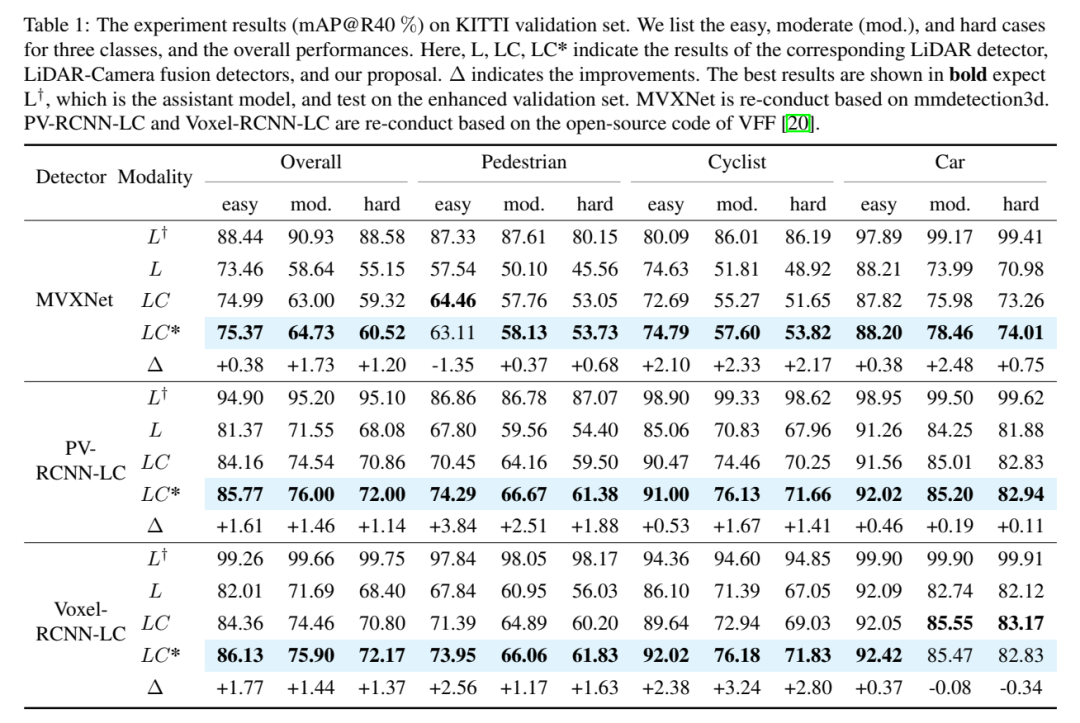
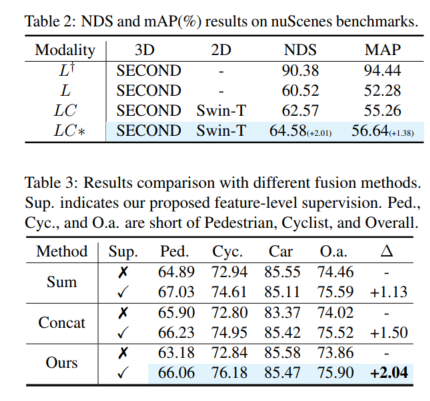
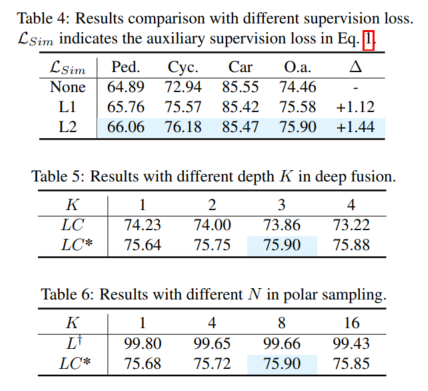
実験結果 (mAP@R40%)。ここでは、イージー、ミディアム (モード)、ハード ケースの 3 つのカテゴリと全体的なパフォーマンスを示します。ここで、L、LC、LC* は、対応する LIDAR 検出器、LIDAR カメラフュージョン検出器、および本論文の提案の結果を表します。 Δは改善を表します。最良の結果は太字で示されており、L が補助モデルであることが予想され、拡張された検証セットでテストされます。 MVXNet は mmdetection3d に基づいて再実装されています。 PV-RCNN-LC および Voxel RCNN LC は、VFF のオープン ソース コードに基づいて再実装されています。

以上がSupFusion: Lidar とカメラが融合した 3D 検出ネットワークを効果的に監視する方法を模索していますか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。