



- 論文リンク: https://arxiv.org/pdf/2309.07864.pdf
- LLM -ベースのエージェントペーパーリスト: https://github.com/WooooDyy/LLM-Agent-Paper-List
モデルの固有の機能を強化することが、インテリジェント エージェントのさらなる開発を促進する重要な要素であることがわかりました。
- #制御端末
- : 通常、LLM で構成され、インテリジェント エージェントの中核となります。記憶や知識を保存するだけでなく、情報処理や意思決定などの不可欠な機能も担います。インテリジェントエージェントの一般化と移転可能性を反映して、推論と計画のプロセスを提示し、未知のタスクにうまく対処できます。
- : インテリジェント エージェントの知覚空間を純粋なテキストから拡張して、テキスト、視覚、聴覚などのマルチモーダル フィールドを含めます。周囲環境からの情報をより効果的に取得し、活用します。
- : 通常のテキスト出力に加えて、エージェントにはツールを具体化して使用する機能も与えられるため、環境の変化によりよく適応できます。フィードバックは環境と相互作用し、環境を形作ることもあります。
著者は、例を使用して LLM ベースのエージェントのワークフローを説明します。人間が雨が降るかどうか尋ねると、知覚端 (Perception) は指示を出します。 LLM が理解できる表現に変換されます。そして、制御端末(ブレイン)は、現在の天気やインターネット上の天気予報に基づいて推論と行動計画を開始します。最後に、アクションが応答して人間に傘を渡します。
上記のプロセスを繰り返すことにより、インテリジェント エージェントは継続的にフィードバックを取得し、環境と対話することができます。
#制御端末: 脳
自然言語インタラクション:
- 含意の理解: 直観的に表示されるコンテンツに加えて、言語は話者の意図や好みなどの情報も伝えることがあります。これは、エージェントがより効率的に通信し、協力するのに役立つことを意味しており、大規模なモデルはすでにこの点での可能性を示しています。
知識:
メモリ:
- 要約: 記憶を要約して、エージェントが記憶から重要な詳細を抽出する能力を強化します。
- 圧縮メモリ (圧縮): ベクトルまたは適切なデータ構造を使用してメモリを圧縮することにより、メモリの検索効率を向上させることができます。
推論と計画:
- 計画の振り返り: 計画を立てた後、それを振り返り、その長所と短所を評価できます。この種の反映は一般に 3 つの側面から生じます: 内部フィードバック メカニズムの使用、人間との対話からのフィードバックの取得、環境からのフィードバックの取得。
移行可能性と一般化:
- 視覚入力を対応するテキスト説明に変換します (画像キャプション): LLM が直接理解でき、解釈可能性が高くなります。
- 視覚情報をエンコードして表現します。ビジュアルベーシックモデル LLM のパラダイムを使用して認識モジュールを形成し、アライメント操作を通じてモデルがさまざまなモダリティの内容を理解できるようにします。エンドツーエンド方式のトレインで実行されます。
テキスト出力:
ツールの使用法:
具体化されたアクション:
これらのアトミック アクションを組み合わせることで、エージェントはより複雑なタスクを完了できます。たとえば、「キッチンにあるスイカはボウルより大きいですか?」などの QA タスクを具体化します。この問題を解決するには、エージェントはキッチンに移動し、両方のサイズを観察した後、答えを導き出す必要があります。 - 物理世界のハードウェアのコストが高く、具体化されたデータ セットが不足しているため、具体化されたアクションに関する現在の研究は依然として主にゲーム プラットフォーム「Minecraft」に焦点を当てています。仮想サンドボックス環境。したがって、著者らは、より現実に近いタスクパラダイムと評価基準を期待している一方で、関連するデータセットの効率的な構築についてさらなる探求も必要としています。
3. ユーザーの手を解放した後は、脳を解放してみてください: 最先端の科学分野の可能性を最大限に発揮し、革新的で探索的な作業を完了します。
これに基づいて、エージェントのアプリケーションには 3 つのパラダイムがあります:

タスク指向展開では、エージェントは人間のユーザーが基本的な日常タスクを処理するのを支援します。基本的なコマンドの理解、タスクの分解、環境と対話する能力が必要です。具体的には、既存のタスク タイプに応じて、エージェントの実際のアプリケーションをシミュレートされたネットワーク環境とシミュレートされた生活シナリオに分けることができます。 イノベーション指向の展開では、エージェントは最先端の科学分野における独立した調査の可能性を実証できます。固有の複雑さと専門分野からのトレーニング データの欠如がインテリジェント エージェントの構築を妨げていますが、化学、材料、コンピューターなどの分野ではすでに多くの研究が進歩しています。 ライフサイクル指向の展開では、エージェントはオープンワールドで継続的に探索、学習、新しいスキルを使用し、長期間生存することができます。このセクションでは、著者はゲーム「Minecraft」を例として取り上げます。ゲーム内のサバイバル チャレンジは現実世界の縮図と見なすことができるため、多くの研究者がエージェントの包括的な機能を開発およびテストするための独自のプラットフォームとしてゲームを使用してきました。

- すべてのエージェントが自分の意見や意見を自由に表現し、非連続的な方法で協力する場合、それは無秩序な協力と呼ばれます。
- すべてのエージェントが、流れ作業の形で自分の意見を 1 つずつ表明するなど、特定のルールに従う場合、協力プロセス全体が秩序正しくなり、これを秩序ある協力と呼びます。
名前が示すように、人間とエージェントの対話、インテリジェントエージェントは人間と協力してタスクを完了します。エージェントの動的な学習能力はコミュニケーションによってサポートされる必要がある一方で、現在のエージェントシステムは解釈性がまだ不十分であり、安全性や合法性などに問題がある可能性があるため、人間の関与が必要です。そして監督。
著者は、論文の中でヒューマン エージェントのインタラクションを次の 2 つのモードに分けています。
インストラクター兼実行者モード: 人間がインストラクターとして機能し、指示とフィードバックを与えます。エージェントは、指示に従って段階的に実行者として機能します。調整して最適化します。このモデルは、教育、医療、ビジネスなどの分野で広く使用されています。 イコール パートナーシップ モード: 一部の研究では、エージェントが人間とのコミュニケーションにおいて共感を示したり、平等な中間としてタスクの実行に参加したりできることが観察されています。知能エージェントは日常生活への応用の可能性を示しており、将来的には人間社会に組み込まれることが期待されています。
- ##左側の部分:
個人レベルでは、エージェントは計画、推論、考察など、内面化されたさまざまな行動を示します。さらに、エージェントは、認知、感情、性格の側面にわたる本質的な性格特性を示します。 - 中間部分:
単一のエージェントは、他の個々のエージェントとグループを形成して、共同で協力や他のグループ行動 (共同協力など) を実証できます。 - 右側の部分:
環境は、仮想サンドボックス環境または実際の物理世界の形式をとることができます。環境の要素には、人間と利用可能なさまざまなリソースが含まれます。単一のエージェントの場合、他のエージェントも環境の一部となります。 - 全体的なインタラクション:
エージェントは、外部環境を感知してアクションを実行することで、インタラクション プロセス全体に積極的に参加します。
##エージェントの社会的行動と性格
この記事では、外部の行動と内部の性格の観点から社会におけるエージェントのパフォーマンスを検証しています:
社会的な観点から出発点出発点として、行動は個人と集団の 2 つのレベルに分けることができます。
個人の行動は、エージェントの運用と開発の基礎を形成します。自体。これには、知覚によって表される入力、アクションによって表される出力、およびエージェント自身の内面化された行動が含まれます。
群集行動とは、2 人以上のエージェントが自発的に対話するときに発生する行動を指します。これには、協力に代表されるポジティブな行動、対立に代表されるネガティブな行動、そして群れに従う、監視するなどの中立的な行動が含まれます。
認知、感情、個性を含みます。人間が社会化のプロセスを通じて徐々に特性を発達させるのと同じように、エージェントも、グループや環境との相互作用を通じて徐々に人格を形成する、いわゆる「人間のような知性」を示します。
認知能力: エージェントが知識を獲得し、理解するプロセスをカバーします。研究によると、LLM ベースのエージェントは、いくつかの側面で人間のようなレベルを実証できます。熟慮と知性の。
心の知能指数: 喜び、怒り、悲しみ、喜びなどの主観的な感情や感情状態、そして同情や共感を示す能力が含まれます。 性格描写: LLM の性格特性を理解し分析するために、研究者はビッグ 5 性格テストや MBTI テストなどの成熟した評価方法を使用して、性格の多様性を調査してきました。そして複雑さ。
- 実際の物理環境:
物理環境は、エージェントが観察する実際のオブジェクトと空間で構成される具体的な環境です。そしてアクション。この環境では、豊富な感覚入力 (視覚、聴覚、空間) が導入されます。仮想環境とは異なり、物理空間ではエージェントの動作に対してより多くの要求が課されます。つまり、エージェントは物理環境に適応でき、実行可能なモーション コントロールを生成する必要があります。 著者は、物理環境の複雑さを説明するために例を挙げました: 工場内でロボット アームを操作するインテリジェント エージェントを想像してください。ロボット アームを操作するとき、異なる材質の物体の損傷を避けるには力が必要であり、さらに、エージェントは物理的なワークスペース内を移動し、障害物を回避してロボット アームの移動軌道を最適化するために、時間内に移動経路を調整する必要があります。 #これらの要件により、物理環境におけるエージェントの複雑さと課題が増大します。 #シミュレーション、開始!
#記事の中で、著者らは、模擬社会はオープンで永続的で状況に応じて組織化されている必要があると考えています。開放性はエージェントがシミュレーションされた社会に自律的に出入りすることを可能にします;永続性は社会が時間の経過とともに発展する一貫した軌道を持つことを意味します;文脈性は特定の環境における主体の存在と動作を強調します;組織化はシミュレーション社会が物理的な世界を持つことを保証します-ルールや制限など。
模擬社会の重要性については、スタンフォード大学の生成エージェントタウンがすべての人に鮮明な例を提供しています。エージェント社会は、次のようなグループインテリジェンスの能力の境界を探求するために使用できます。エージェントが共同でバレンタイン デー パーティーを企画したり、ソーシャル ネットワークをシミュレートしてコミュニケーション現象を観察するなど、社会科学研究を加速するためにも使用できます。さらに、倫理的な意思決定シナリオをシミュレーションすることでエージェントの背後にある価値観を探ったり、政策が社会に与える影響をシミュレーションすることで意思決定を支援したりする研究も行われています。
さらに、著者は、これらのシミュレーションには、有害な社会現象、固定観念と偏見、プライバシーとセキュリティの問題、その他のリスクを含むがこれらに限定されない特定のリスクも伴う可能性があると指摘しています。 -依存性と大人の中毒性。
最後にこの論文では、著者はいくつかの将来を見据えた未解決の質問についても議論し、読者に次のことについて考えるためのインスピレーションを提供しています。モデルはお互いを促進し、一緒に開発しますか?LLM ベースのエージェントはどのような課題や懸念をもたらすのでしょうか? インテリジェント エージェントを本当に実装できるかどうかには、現実世界への危害を避けるための厳密なセキュリティ評価が必要です。著者は、違法虐待、失業のリスク、人間の幸福への影響など、さらに多くの潜在的な脅威を要約しています。 #スケールアップはどのような機会と課題をもたらすのでしょうか? シミュレーション社会では、個人の数を増やすことでシミュレーションの信頼性と信頼性を大幅に向上させることができます。ただし、エージェントの数が増加するにつれて、通信およびメッセージ配布の問題は非常に複雑になり、情報の歪曲、誤解、または幻覚によってシミュレーション システム全体の効率が大幅に低下します。 LLM ベースのエージェントが AGI への適切なパスであるかどうかについて、インターネット上で議論があります。 研究者の中には、GPT-4 に代表される大規模モデルは十分なコーパスでトレーニングされており、これに基づいて構築されたエージェントは AGI への扉を開く鍵となる可能性があると信じている人もいます。しかし、他の研究者は、自己回帰言語モデリングは反応するだけなので、本当の知能は示さないと考えています。ワールド モデルなどのより完全なモデリング手法は、AGI につながる可能性があります。#群知能の進化。群知能は、多くの人々の意見を収集し、それらを意思決定に変換するプロセスです。 しかし、エージェントの数を増やすだけで真の「知性」は生み出されるのでしょうか?さらに、知的エージェントの社会が「集団思考」や個人の認知バイアスを克服できるようにするために、個々のエージェントをどのように調整すればよいでしょうか? サービスとしてのエージェント (AaaS)。 LLM ベースのエージェントは大規模モデル自体よりも複雑であり、中小企業や個人がローカルに構築するのはより困難であるため、クラウド ベンダーはサービスの形式でインテリジェント エージェントを実装することを検討できます。サービスとしてのエージェント。他のクラウド サービスと同様、AaaS には、ユーザーに高い柔軟性とオンデマンドのセルフサービスを提供する可能性があります。
以上がFudan NLP チームは、AI エージェントの現状と将来の概要を 1 つの記事で提供する、80 ページにわたる大規模モデル エージェントの概要を発表しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

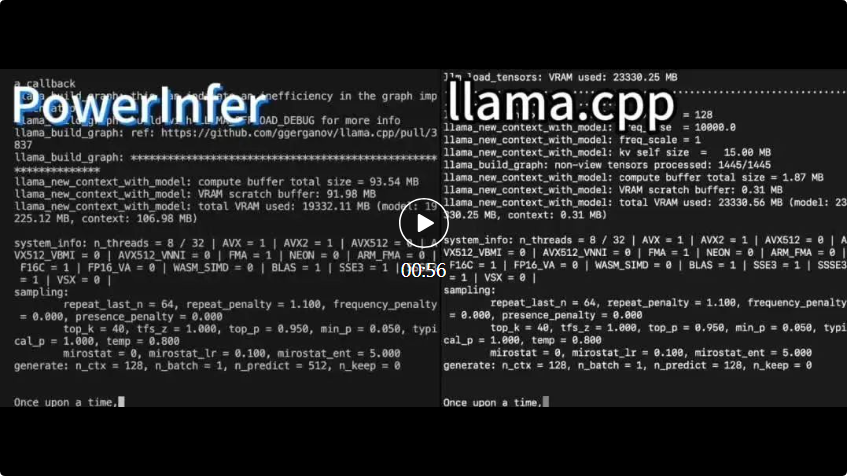 4090生成器:与A100平台相比,token生成速度仅低于18%,上交推理引擎赢得热议Dec 21, 2023 pm 03:25 PM
4090生成器:与A100平台相比,token生成速度仅低于18%,上交推理引擎赢得热议Dec 21, 2023 pm 03:25 PMPowerInfer提高了在消费级硬件上运行AI的效率上海交大团队最新推出了超强CPU/GPULLM高速推理引擎PowerInfer。PowerInfer和llama.cpp都在相同的硬件上运行,并充分利用了RTX4090上的VRAM。这个推理引擎速度有多快?在单个NVIDIARTX4090GPU上运行LLM,PowerInfer的平均token生成速率为13.20tokens/s,峰值为29.08tokens/s,仅比顶级服务器A100GPU低18%,可适用于各种LLM。PowerInfer与
 思维链CoT进化成思维图GoT,比思维树更优秀的提示工程技术诞生了Sep 05, 2023 pm 05:53 PM
思维链CoT进化成思维图GoT,比思维树更优秀的提示工程技术诞生了Sep 05, 2023 pm 05:53 PM要让大型语言模型(LLM)充分发挥其能力,有效的prompt设计方案是必不可少的,为此甚至出现了promptengineering(提示工程)这一新兴领域。在各种prompt设计方案中,思维链(CoT)凭借其强大的推理能力吸引了许多研究者和用户的眼球,基于其改进的CoT-SC以及更进一步的思维树(ToT)也收获了大量关注。近日,苏黎世联邦理工学院、Cledar和华沙理工大学的一个研究团队提出了更进一步的想法:思维图(GoT)。让思维从链到树到图,为LLM构建推理过程的能力不断得到提升,研究者也通
 复旦NLP团队发布80页大模型Agent综述,一文纵览AI智能体的现状与未来Sep 23, 2023 am 09:01 AM
复旦NLP团队发布80页大模型Agent综述,一文纵览AI智能体的现状与未来Sep 23, 2023 am 09:01 AM近期,复旦大学自然语言处理团队(FudanNLP)推出LLM-basedAgents综述论文,全文长达86页,共有600余篇参考文献!作者们从AIAgent的历史出发,全面梳理了基于大型语言模型的智能代理现状,包括:LLM-basedAgent的背景、构成、应用场景、以及备受关注的代理社会。同时,作者们探讨了Agent相关的前瞻开放问题,对于相关领域的未来发展趋势具有重要价值。论文链接:https://arxiv.org/pdf/2309.07864.pdfLLM-basedAgent论文列表:
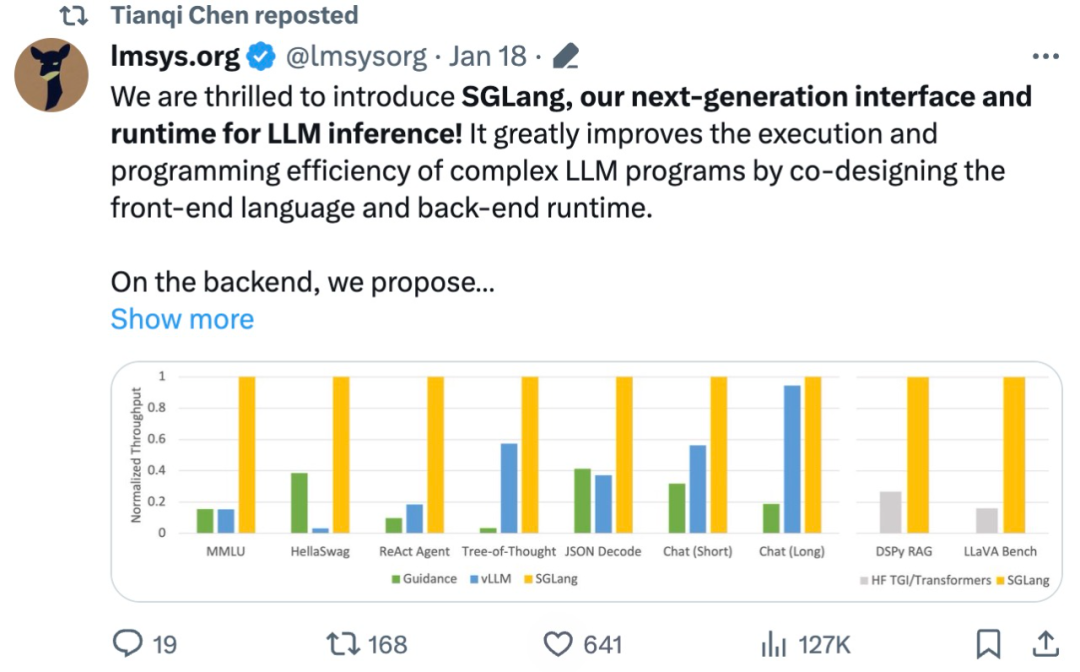 吞吐量提升5倍,联合设计后端系统和前端语言的LLM接口来了Mar 01, 2024 pm 10:55 PM
吞吐量提升5倍,联合设计后端系统和前端语言的LLM接口来了Mar 01, 2024 pm 10:55 PM大型语言模型(LLM)被广泛应用于需要多个链式生成调用、高级提示技术、控制流以及与外部环境交互的复杂任务。尽管如此,目前用于编程和执行这些应用程序的高效系统却存在明显的不足之处。研究人员最近提出了一种新的结构化生成语言(StructuredGenerationLanguage),称为SGLang,旨在改进与LLM的交互性。通过整合后端运行时系统和前端语言的设计,SGLang使得LLM的性能更高、更易控制。这项研究也获得了机器学习领域的知名学者、CMU助理教授陈天奇的转发。总的来说,SGLang的
 大模型也有小偷?为保护你的参数,上交大给大模型制作「人类可读指纹」Feb 02, 2024 pm 09:33 PM
大模型也有小偷?为保护你的参数,上交大给大模型制作「人类可读指纹」Feb 02, 2024 pm 09:33 PM将不同的基模型象征为不同品种的狗,其中相同的「狗形指纹」表明它们源自同一个基模型。大模型的预训练需要耗费大量的计算资源和数据,因此预训练模型的参数成为各大机构重点保护的核心竞争力和资产。然而,与传统软件知识产权保护不同,对预训练模型参数盗用的判断存在以下两个新问题:1)预训练模型的参数,尤其是千亿级别模型的参数,通常不会开源。预训练模型的输出和参数会受到后续处理步骤(如SFT、RLHF、continuepretraining等)的影响,这使得判断一个模型是否基于另一个现有模型微调得来变得困难。无
 FATE 2.0发布:实现异构联邦学习系统互联Jan 16, 2024 am 11:48 AM
FATE 2.0发布:实现异构联邦学习系统互联Jan 16, 2024 am 11:48 AMFATE2.0全面升级,推动隐私计算联邦学习规模化应用FATE开源平台宣布发布FATE2.0版本,作为全球领先的联邦学习工业级开源框架。此次更新实现了联邦异构系统之间的互联互通,持续增强了隐私计算平台的互联互通能力。这一进展进一步推动了联邦学习与隐私计算规模化应用的发展。FATE2.0以全面互通为设计理念,采用开源方式对应用层、调度、通信、异构计算(算法)四个层面进行改造,实现了系统与系统、系统与算法、算法与算法之间异构互通的能力。FATE2.0的设计兼容了北京金融科技产业联盟的《金融业隐私计算
 220亿晶体管,IBM机器学习专用处理器NorthPole,能效25倍提升Oct 23, 2023 pm 03:13 PM
220亿晶体管,IBM机器学习专用处理器NorthPole,能效25倍提升Oct 23, 2023 pm 03:13 PMIBM再度发力。随着AI系统的飞速发展,其能源需求也在不断增加。训练新系统需要大量的数据集和处理器时间,因此能耗极高。在某些情况下,执行一些训练好的系统,智能手机就能轻松胜任。但是,执行的次数太多,能耗也会增加。幸运的是,有很多方法可以降低后者的能耗。IBM和英特尔已经试验过模仿实际神经元行为设计的处理器。IBM还测试了在相变存储器中执行神经网络计算,以避免重复访问RAM。现在,IBM又推出了另一种方法。该公司的新型NorthPole处理器综合了上述方法的一些理念,并将其与一种非常精简的计算运行
 制作莫比乌斯环,最少需要多长纸带?50年来的谜题被解开了Oct 07, 2023 pm 06:17 PM
制作莫比乌斯环,最少需要多长纸带?50年来的谜题被解开了Oct 07, 2023 pm 06:17 PM自己动手做过莫比乌斯带吗?莫比乌斯带是一种奇特的数学结构。要构造一个这样美丽的单面曲面其实非常简单,即使是小孩子也可以轻松完成。你只需要取一张纸带,扭曲一次,然后将两端粘在一起。然而,这样容易制作的莫比乌斯带却有着复杂的性质,长期吸引着数学家们的兴趣。最近,研究人员一直被一个看似简单的问题困扰着,那就是关于制作莫比乌斯带所需纸带的最短长度?布朗大学RichardEvanSchwartz谈到,对于莫比乌斯带来说,这个问题没有解决,因为它们是「嵌入的」而不是「浸入的」,这意味着它们不会相互渗透或自我


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

PhpStorm Mac バージョン
最新(2018.2.1)のプロフェッショナル向けPHP統合開発ツール

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

SAP NetWeaver Server Adapter for Eclipse
Eclipse を SAP NetWeaver アプリケーション サーバーと統合します。

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境
ホットトピック
 7445
7445 15137252
15137252