



特徴重要度分析は、予測を行う際の各特徴 (変数または入力) の有用性または値を理解するために使用されます。目標は、モデルの出力に最も大きな影響を与える最も重要な特徴を特定することであり、これは機械学習でよく使用される方法です。
#特徴重要度分析が重要なのはなぜですか?
数十または偶数の数値を含む特徴がある場合それぞれが機械学習モデルのパフォーマンスに寄与する可能性がある数百の特徴のデータセット。ただし、すべての機能が同じように作成されているわけではありません。一部は冗長または無関係である可能性があるため、モデリングの複雑さが増し、過剰適合につながる可能性があります。
機能重要度分析では、最も有益な機能を特定して焦点を当てることができ、その結果、いくつかの利点が得られます。 1. 洞察の提供: 特徴の重要性を分析することで、データ内のどの特徴が結果に最も大きな影響を与えるかについて洞察を得ることができ、データの性質をより深く理解するのに役立ちます。 2. モデルの最適化: 主要な機能を特定することで、モデルのパフォーマンスを最適化し、不必要なコンピューティングとストレージのオーバーヘッドを削減し、モデルのトレーニングと予測の効率を向上させることができます。 3. 特徴の選択: 特徴の重要度分析は、最も予測力の高い特徴を選択するのに役立ち、それによってモデルの精度と汎化能力が向上します。 4. モデルの説明: 特徴重要度分析は、モデルの予測結果を説明し、モデルの背後にあるパターンと因果関係を明らかにし、モデルの解釈可能性を高めるのにも役立ちます
- モデルのパフォーマンスの向上
- 過学習の削減
- トレーニングと推論の高速化
- 解釈性の強化
# Python での特徴重要度分析のいくつかの方法を詳しく見てみましょう。
特徴重要度分析メソッド
1. Permutation ImportancePermutationImportance
このメソッドの値各特徴量の特徴量をランダムに配置し、モデルの性能劣化の度合いを監視します。減少が大きい場合、その特徴がより重要であることを意味します
from sklearn.datasets import load_breast_cancer from sklearn.ensemble import RandomForestClassifier from sklearn.inspection import permutation_importance from sklearn.model_selection import train_test_split import matplotlib.pyplot as plt cancer = load_breast_cancer() X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, random_state=1) rf = RandomForestClassifier(n_estimators=100, random_state=1) rf.fit(X_train, y_train) baseline = rf.score(X_test, y_test) result = permutation_importance(rf, X_test, y_test, n_repeats=10, random_state=1, scoring='accuracy') importances = result.importances_mean # Visualize permutation importances plt.bar(range(len(importances)), importances) plt.xlabel('Feature Index') plt.ylabel('Permutation Importance') plt.show()

2. 組み込みの特徴の重要度 (coef_ または feature_importances_)
線形回帰やランダム フォレストなどの一部のモデルは、特徴量重要度スコアを直接出力できます。これらは、最終予測に対する各特徴の寄与を示します。
from sklearn.datasets import load_breast_cancer from sklearn.ensemble import RandomForestClassifier X, y = load_breast_cancer(return_X_y=True) rf = RandomForestClassifier(n_estimators=100, random_state=1) rf.fit(X, y) importances = rf.feature_importances_ # Plot importances plt.bar(range(X.shape[1]), importances) plt.xlabel('Feature Index') plt.ylabel('Feature Importance') plt.show()
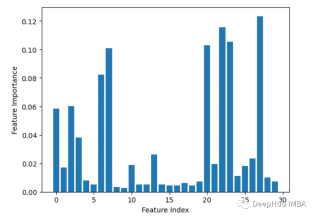
3. Leave-one-out
一度に 1 つのフィーチャを繰り返し削除して評価します正確さ。
from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score import matplotlib.pyplot as plt import numpy as np # Load sample data X, y = load_breast_cancer(return_X_y=True) # Split data into train and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1) # Train a random forest model rf = RandomForestClassifier(n_estimators=100, random_state=1) rf.fit(X_train, y_train) # Get baseline accuracy on test data base_acc = accuracy_score(y_test, rf.predict(X_test)) # Initialize empty list to store importances importances = [] # Iterate over all columns and remove one at a time for i in range(X_train.shape[1]):X_temp = np.delete(X_train, i, axis=1)rf.fit(X_temp, y_train)acc = accuracy_score(y_test, rf.predict(np.delete(X_test, i, axis=1)))importances.append(base_acc - acc) # Plot importance scores plt.bar(range(len(importances)), importances) plt.show()

4. 相関分析
書き換える必要がある内容は、計算機能と目標 変数間の相関、相関が高いほど、特徴の重要性が高くなります#import pandas as pd from sklearn.datasets import load_breast_cancer X, y = load_breast_cancer(return_X_y=True) df = pd.DataFrame(X, columns=range(30)) df['y'] = y correlations = df.corrwith(df.y).abs() correlations.sort_values(ascending=False, inplace=True) correlations.plot.bar()
 ##5. 再帰的特徴の削除
##5. 再帰的特徴の削除
フィーチャを再帰的に削除し、それがモデルのパフォーマンスにどのような影響を与えるかを確認します。削除したときにドロップが大きくなる機能の方が重要です。
from sklearn.ensemble import RandomForestClassifier from sklearn.feature_selection import RFE import pandas as pd from sklearn.datasets import load_breast_cancer import matplotlib.pyplot as plt X, y = load_breast_cancer(return_X_y=True) df = pd.DataFrame(X, columns=range(30)) df['y'] = y rf = RandomForestClassifier() rfe = RFE(rf, n_features_to_select=10) rfe.fit(X, y) print(rfe.ranking_)出力は [6 4 11 12 7 11 18 21 8 16 10 3 15 14 19 17 20 13 11 11 12 9 11 5 11]
#6. XGBoost 機能の重要性
データの分割で機能が使用される回数を計算します。この機能はすべてのツリーで使用されます。分割数が多いほど重要性が高くなります
import xgboost as xgb import pandas as pd from sklearn.datasets import load_breast_cancer import matplotlib.pyplot as plt X, y = load_breast_cancer(return_X_y=True) df = pd.DataFrame(X, columns=range(30)) df['y'] = y model = xgb.XGBClassifier() model.fit(X, y) importances = model.feature_importances_ importances = pd.Series(importances, index=range(X.shape[1])) importances.plot.bar()
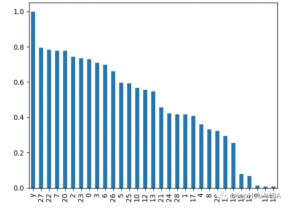
7. 主成分分析 PCA
pair 主成分分析を実行します。特徴を確認し、各主成分の説明された分散比を表示します。最初のいくつかのコンポーネントの負荷が高い特性はより重要です。
from sklearn.decomposition import PCA import pandas as pd from sklearn.datasets import load_breast_cancer import matplotlib.pyplot as plt X, y = load_breast_cancer(return_X_y=True) df = pd.DataFrame(X, columns=range(30)) df['y'] = y pca = PCA() pca.fit(X) plt.bar(range(pca.n_components_), pca.explained_variance_ratio_) plt.xlabel('PCA components') plt.ylabel('Explained Variance')
8. 分散分析 ANOVA
f_classif() を使用して分散分析を取得します。各特徴の f 値。 f 値が大きいほど、フィーチャとターゲットの間の相関が強くなります。
from sklearn.feature_selection import f_classif import pandas as pd from sklearn.datasets import load_breast_cancer import matplotlib.pyplot as plt X, y = load_breast_cancer(return_X_y=True) df = pd.DataFrame(X, columns=range(30)) df['y'] = y fval = f_classif(X, y) fval = pd.Series(fval[0], index=range(X.shape[1])) fval.plot.bar()
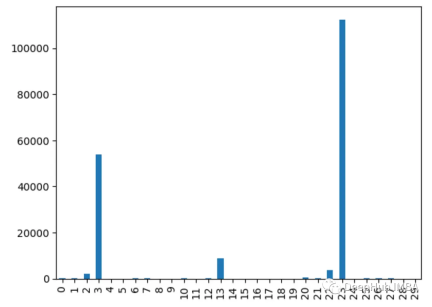
9. カイ二乗検定
chi2() 関数を使用して値を取得します各特徴のカイ二乗統計。スコアが高い特徴はターゲット変数から独立している可能性が高くなります
from sklearn.feature_selection import chi2 import pandas as pd from sklearn.datasets import load_breast_cancer import matplotlib.pyplot as plt X, y = load_breast_cancer(return_X_y=True) df = pd.DataFrame(X, columns=range(30)) df['y'] = y chi_scores = chi2(X, y) chi_scores = pd.Series(chi_scores[0], index=range(X.shape[1])) chi_scores.plot.bar()
为什么不同的方法会检测到不同的特征?
由于不同的特征重要性方法,有时可以确定哪些特征是最重要的
1、他们用不同的方式衡量重要性:
有的使用不同特特征进行预测,监控精度下降
像XGBOOST或者回归模型使用内置重要性来进行特征的重要性排序
而PCA着眼于方差解释
2、不同模型有不同模型的方法:
线性模型偏向于处理线性关系,而树模型则更倾向于捕捉接近根节点的特征
3、交互作用:
有些方法可以获取特征之间的相互关系,而有些方法则不行,这会导致结果的不同
3、不稳定:
使用不同的数据子集,重要性值可能在同一方法的不同运行中有所不同,这是因为数据差异决定的
4、Hyperparameters:
通过调整超参数,例如主成分分析(PCA)组件或决策树的深度,也会对结果产生影响
所以不同的假设、偏差、数据处理和方法的可变性意味着它们并不总是在最重要的特征上保持一致。
选择特征重要性分析方法的一些最佳实践
- 尝试多种方法以获得更健壮的视图
- 聚合结果的集成方法
- 更多地关注相对顺序,而不是绝对值
- 差异并不一定意味着有问题,检查差异的原因会对数据和模型有更深入的了解
以上が一般的に使用される 9 つの Python 特徴重要度分析方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 Gemma Scope:AI'の思考プロセスを覗くためのGoogle'の顕微鏡Apr 17, 2025 am 11:55 AM
Gemma Scope:AI'の思考プロセスを覗くためのGoogle'の顕微鏡Apr 17, 2025 am 11:55 AMジェマの範囲で言語モデルの内部の仕組みを探る AI言語モデルの複雑さを理解することは、重要な課題です。 包括的なツールキットであるGemma ScopeのGoogleのリリースは、研究者に掘り下げる強力な方法を提供します
 ビジネスインテリジェンスアナリストは誰で、どのようになるか?Apr 17, 2025 am 11:44 AM
ビジネスインテリジェンスアナリストは誰で、どのようになるか?Apr 17, 2025 am 11:44 AMビジネスの成功のロック解除:ビジネスインテリジェンスアナリストになるためのガイド 生データを組織の成長を促進する実用的な洞察に変換することを想像してください。 これはビジネスインテリジェンス(BI)アナリストの力です - GUにおける重要な役割
 SQLに列を追加する方法は? - 分析VidhyaApr 17, 2025 am 11:43 AM
SQLに列を追加する方法は? - 分析VidhyaApr 17, 2025 am 11:43 AMSQLの変更テーブルステートメント:データベースに列を動的に追加する データ管理では、SQLの適応性が重要です。 その場でデータベース構造を調整する必要がありますか? Alter Tableステートメントはあなたの解決策です。このガイドの詳細は、コルを追加します
 ビジネスアナリストとデータアナリストApr 17, 2025 am 11:38 AM
ビジネスアナリストとデータアナリストApr 17, 2025 am 11:38 AM導入 2人の専門家が重要なプロジェクトで協力している賑やかなオフィスを想像してください。 ビジネスアナリストは、会社の目標に焦点を当て、改善の分野を特定し、市場動向との戦略的整合を確保しています。 シム
 ExcelのCountとCountaとは何ですか? - 分析VidhyaApr 17, 2025 am 11:34 AM
ExcelのCountとCountaとは何ですか? - 分析VidhyaApr 17, 2025 am 11:34 AMExcelデータカウントと分析:カウントとカウントの機能の詳細な説明 特に大規模なデータセットを使用する場合、Excelでは、正確なデータカウントと分析が重要です。 Excelは、これを達成するためにさまざまな機能を提供し、CountおよびCounta関数は、さまざまな条件下でセルの数をカウントするための重要なツールです。両方の機能はセルをカウントするために使用されますが、設計ターゲットは異なるデータ型をターゲットにしています。 CountおよびCounta機能の特定の詳細を掘り下げ、独自の機能と違いを強調し、データ分析に適用する方法を学びましょう。 キーポイントの概要 カウントとcouを理解します
 ChromeはAIと一緒にここにいます:毎日何か新しいことを体験してください!!Apr 17, 2025 am 11:29 AM
ChromeはAIと一緒にここにいます:毎日何か新しいことを体験してください!!Apr 17, 2025 am 11:29 AMGoogle Chrome'sAI Revolution:パーソナライズされた効率的なブラウジングエクスペリエンス 人工知能(AI)は私たちの日常生活を急速に変換しており、Google ChromeはWebブラウジングアリーナで料金をリードしています。 この記事では、興奮を探ります
 ai' s Human Side:Wellbeing and the Quadruple bottuntApr 17, 2025 am 11:28 AM
ai' s Human Side:Wellbeing and the Quadruple bottuntApr 17, 2025 am 11:28 AMインパクトの再考:四重材のボトムライン 長い間、会話はAIの影響の狭い見方に支配されており、主に利益の最終ラインに焦点を当てています。ただし、より全体的なアプローチは、BUの相互接続性を認識しています
 5ゲームを変える量子コンピューティングの使用ケースあなたが知っておくべきであるApr 17, 2025 am 11:24 AM
5ゲームを変える量子コンピューティングの使用ケースあなたが知っておくべきであるApr 17, 2025 am 11:24 AM物事はその点に向かって着実に動いています。量子サービスプロバイダーとスタートアップに投資する投資は、業界がその重要性を理解していることを示しています。そして、その価値を示すために、現実世界のユースケースの数が増えています


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

ドリームウィーバー CS6
ビジュアル Web 開発ツール

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

