
ホームページ >テクノロジー周辺機器 >AI >Google DeepMind: 大規模モデルと強化学習を組み合わせて、ロボットが世界を認識するためのインテリジェントな脳を作成
Google DeepMind: 大規模モデルと強化学習を組み合わせて、ロボットが世界を認識するためのインテリジェントな脳を作成

- WBOY転載
- 2023-09-22 09:53:141100ブラウズ
ロボット学習手法を開発する際、大規模で多様なデータセットを統合し、強力な表現モデル (Transformer など) と組み合わせることができれば、ロボットが学習できるように一般化機能と広く適用可能な戦略を開発することが期待されます。さまざまなタスクをうまく処理するため。たとえば、これらの戦略により、ロボットは自然言語の指示に従い、多段階の行動を実行し、さまざまな環境や目標に適応し、さらにはさまざまなロボットの形状に適用することができます。
しかし、ロボット学習の分野で最近登場した強力なモデルはすべて、教師あり学習手法を使用してトレーニングされています。したがって、結果として得られる戦略のパフォーマンスは、人間のデモンストレーターが高品質のデモンストレーション データを提供できる程度によって制限されます。この制限には 2 つの理由があります。
- 第一に、私たちはロボット システムが人間の遠隔操作者よりも熟練し、ハードウェアの可能性を最大限に活用してタスクを迅速、スムーズ、確実に完了できるようにしたいと考えています。
- 第二に、ロボット システムが高品質のデモンストレーションに完全に依存するのではなく、経験を自動的に蓄積する能力が向上することを期待しています。
原則として、強化学習はこれら 2 つの能力を同時に提供できます。
最近、有望な開発がいくつかあり、大規模なロボット強化学習が、ロボットの掴みや積み上げ能力、ロボットによる学習など、さまざまな応用シナリオで成功できることが示されています。人間が指定した報酬付きのさまざまなタスク、マルチタスク戦略の学習、目標ベースの戦略の学習、ロボット ナビゲーション。ただし、強化学習を使用して Transformer などの強力なモデルをトレーニングすると、大規模に効果的にインスタンス化することがより困難になることが研究で示されています。
Google DeepMind は最近、Q-Transformer を提案しました。現実世界の多様なデータセットに基づく大規模なロボット学習と、強力なトランスフォーマーに基づく最新のポリシー アーキテクチャを組み合わせる

- #論文: https://q-transformer.github.io/assets/q-transformer.pdf
- プロジェクト: https: / /q-transformer.github.io/
原則として、Transformer を直接使用して既存のアーキテクチャ (ResNets やより小さな畳み込みニューラル ネットワーク) は概念的には単純ですが、このアーキテクチャを効果的に利用できるスキームを設計するのは非常に困難です。大規模なモデルは、大規模で多様なデータ セットを使用できる場合にのみ効果的です。小規模で狭いモデルには、この機能は必要なく、この機能の恩恵を受けられます
#ただし、シミュレーション データを使用して作成した以前の研究もあります。このようなデータセットでは、最も代表的なデータは現実世界から取得されます。したがって、DeepMind は、この研究の焦点はオフライン強化学習を通じて Transformer を利用し、以前に収集された大規模なデータ セットを統合することであると述べました
オフライン強化学習方法は、特定のデータセットに基づいて最も効果的な可能な戦略を導き出すことを目的として、以前に利用可能なデータを使用してトレーニングされます。もちろん、このデータセットは自動的に収集された追加データで強化することもできますが、トレーニング プロセスはデータ収集プロセスとは別のものであるため、大規模なロボット アプリケーションに追加のワークフローが提供されます
Transformer モデルを使用して強化学習を実装する場合、もう 1 つの大きな問題は、このモデルを効果的にトレーニングできる強化学習システムを設計することです。効果的なオフライン強化学習方法は、通常、時間差更新を通じて Q 関数推定を実行します。 Transformer は離散トークン シーケンスをモデル化するため、Q 関数推定問題を離散トークン シーケンス モデリング問題に変換でき、シーケンス内の各トークンに対して適切な損失関数を設計できます。
DeepMind が採用している手法は、アクション ベースの指数関数的な爆発を避けるための次元による離散化スキームです。具体的には、アクション空間の各次元は、強化学習における独立した時間ステップとして扱われます。離散化における異なるビンは、異なるアクションに対応します。この次元的に離散化されたスキームにより、分布遷移を処理する保守的な正則化機能を備えた単純な離散アクション Q 学習方法を使用できるようになります。
DeepMind は、未使用の値を最小化することを目的とした特殊な A 正則化機能を提案します。行動。研究によると、この方法は狭い範囲のデモのようなデータを効果的に学習できるほか、探索ノイズを含む広範囲のデータも学習できることがわかっています。
最後に、モンテカルロと n ステップ回帰を時間差分バックアップと組み合わせたハイブリッド更新メカニズムも使用しました。結果は、このアプローチが大規模なロボット学習問題に対する Transformer ベースのオフライン強化学習法のパフォーマンスを向上できることを示しています。
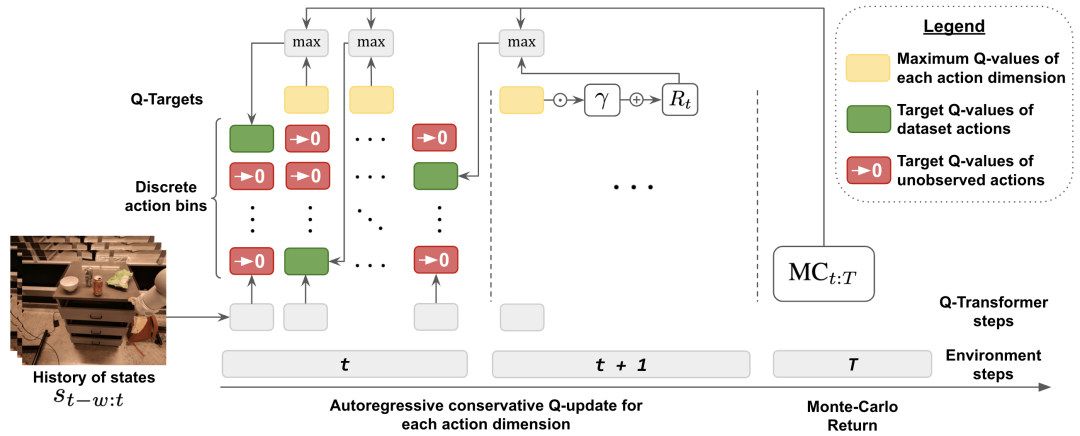
この研究の主な貢献は、Transformer アーキテクチャに基づいたロボットのオフライン強化学習の手法である Q-Transformer です。 Q-Transformer は次元ごとに Q 値をトークン化し、実世界のデータを含む大規模で多様なロボット データセットに適用することに成功しています。図 1 は、Q-Transformer のコンポーネントを示しています。

DeepMind は、厳密な評価を目的として、シミュレーション実験や大規模な実世界実験を含む実験評価を実施しました。比較と実際の検証。その中で、私たちは学習に大規模なテキストベースのマルチタスク戦略を採用し、Q-Transformer の有効性を検証しました。
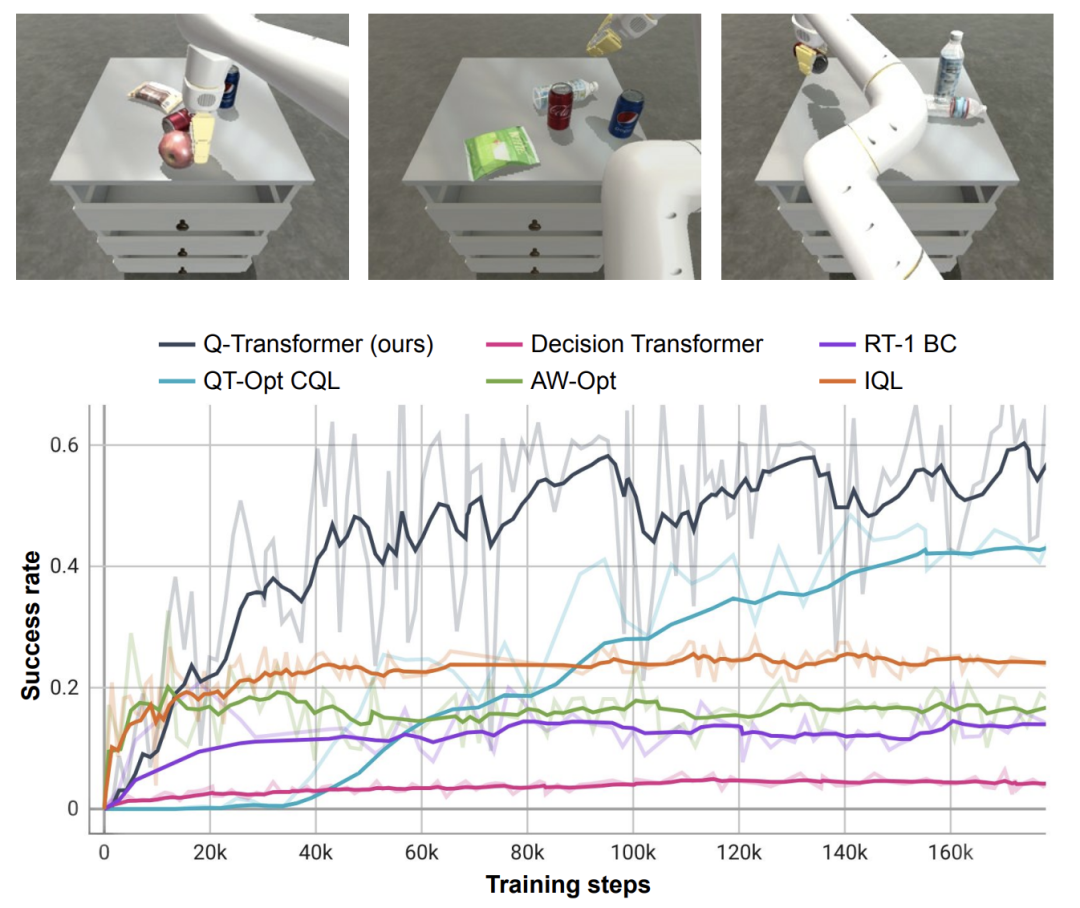
実際の実験では、使用されたデータセットには次のものが含まれていました。 38,000 件の成功したデモンストレーションと 20,000 件の失敗した自動的に収集されたシナリオのデータは、700 を超えるタスクに関して 13 台のロボットによって収集されました。 Q-Transformer は、以前に提案された大規模ロボット強化学習用のアーキテクチャや、以前に提案された Decision Transformer などの Transformer ベースのモデルよりも優れたパフォーマンスを発揮します。
方法の概要
Q 学習に Transformer を使用するために、DeepMind はアクション空間の離散化と自己回帰処理のアプローチを採用します
TD 学習を使用して Q 関数を学習するための古典的な方法は、ベルマン更新ルールに基づいています。
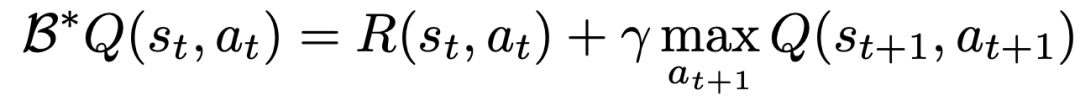
研究者らは、問題の元の MDP を、各アクション次元が Q 学習のステップとして扱われる MDP に変換することで、各アクション次元に対して実行できるようにベルマン アップデートを修正しました。
具体的には、特定のアクション ディメンション d_A に対して、新しいベルマン更新ルールは次のように表現できます。
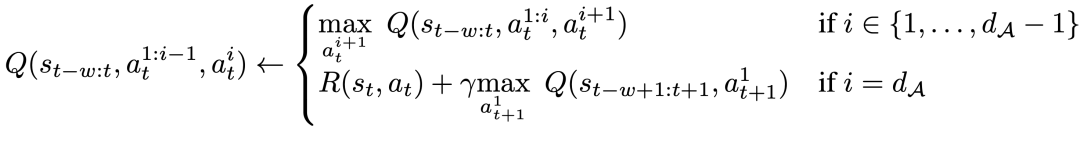
 #オフライン学習プロセス中の分布の変化を考慮するために、DeepMind はシンプルな正則化テクノロジも導入しました。目に見えない行動の価値を最小限に抑えることです。
#オフライン学習プロセス中の分布の変化を考慮するために、DeepMind はシンプルな正則化テクノロジも導入しました。目に見えない行動の価値を最小限に抑えることです。
学習をスピードアップするために、モンテカルロ帰還法も使用しました。このアプローチでは、特定のエピソードに対してリターンツーゴーを使用するだけでなく、次元の最大化をスキップできる n ステップのリターンも使用します
##実験結果
##DeepMind は実験で、現実世界のさまざまなタスクをカバーする Q-Transformer を評価しました。同時に、データをタスクあたり 100 人の人間によるデモのみに制限しました。
デモでは、デモに加えて、自動的に収集された障害イベント フラグメントも追加して、データセット。このデータセットには、デモからの 38,000 の肯定的な例と、自動的に収集された 20,000 の否定的な例が含まれています
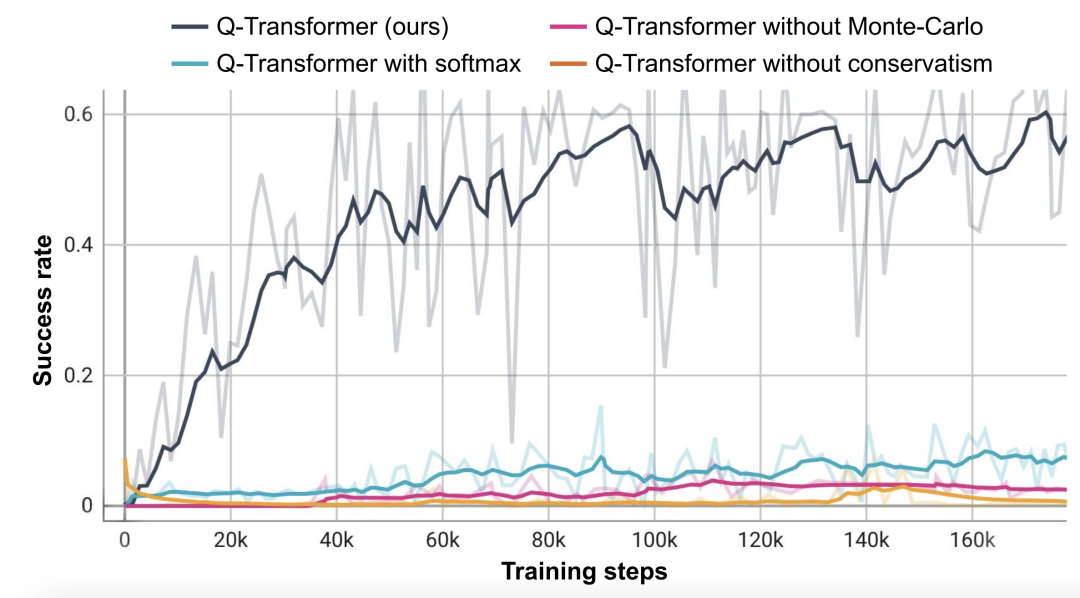
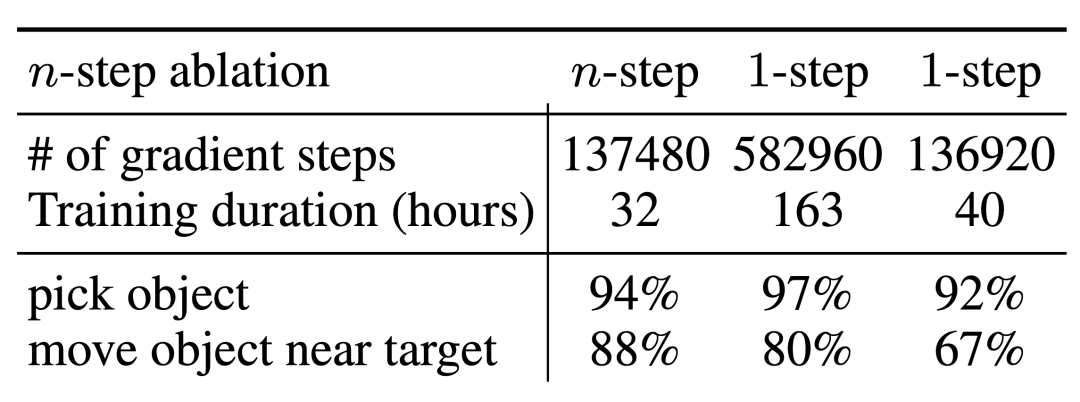
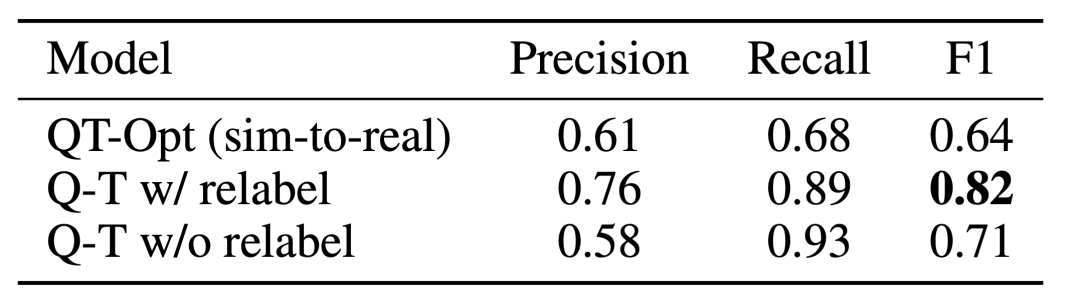
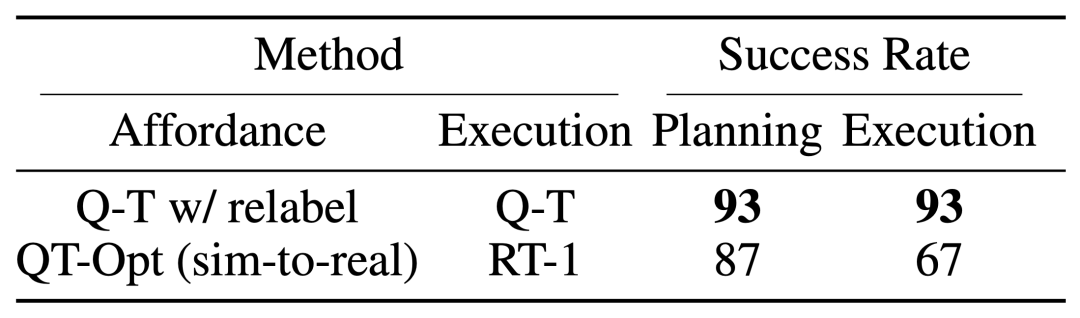
RT-1、IQL、Decision Transformer (DT) などのベースライン手法と比較して、Q-Transformer は自動イベント フラグメントを効果的に利用して、引き出しからのピックアップやスキルの使用などの能力を大幅に向上させることができます。オブジェクトを配置し、ターゲットの近くにオブジェクトを移動し、引き出しを開閉します。 研究者らはまた、困難なシミュレートされた物体検索タスクで新しく提案された方法をテストしました - このタスクでは、データの約 8% のみが正の例であり、残りはノイズの多い負の例でした。 このタスクでは、QT-Opt、IQL、AW-Opt、Q-Transformer などの Q 学習メソッドの方が、動的プログラミングを利用してポリシーを学習できるため、通常はパフォーマンスが向上します。 、そして、負の例を使用して最適化します このオブジェクト検索タスクに基づいて、研究者はアブレーション実験を実施し、次のことを発見しました。パフォーマンスを維持するには、レギュラー化と MC リターンの両方が重要です。 Softmax 正則化プログラムに切り替えると、ポリシーがデータ分散に過度に制限されるため、パフォーマンスが大幅に低下します。これは、ここで DeepMind によって選択された正則化機能がこのタスクにより適切に対処できることを示しています。 彼らの n ステップ リターンに関するアブレーション実験では、バイアスが生じる可能性はあるものの、この方法は同等の高いパフォーマンスを達成できることがわかりました。大幅に少ない勾配ステップで、多くの問題を効果的に処理します 研究者らは、より大きなデータセットで Q-Transformer を実行することも試みました。彼らは、正の例の数を 115,000 に、負の例の数を 185,000 に拡張し、その結果、300,000 のイベント クリップを含むデータ セットが得られました。この大規模なデータセットを使用すると、Q-Transformer は依然として RT-1 BC ベンチマークよりも優れた学習とパフォーマンスを実現できます 最後に、彼らは Q-Transformer によってアフォーダンス モデルとしてトレーニングされた Q 関数を、SayCan と同様の言語プランナーと組み合わせました。 Q-Transformer アフォーダンス推定の効果は、QT-Opt を使用してトレーニングされた以前の Q 関数によるものです。トレーニング中にサンプリングされていないタスクが現在のタスクの負の例として再ラベル付けされる場合、効果はより良くなる可能性があります。 Q-Transformer は QT-Opt トレーニングで使用される sim-to-real トレーニングを必要としないため、適切なシミュレーションが不足している場合は Q-Transformer を使用する方が簡単です。 完全な「計画実行」システムをテストするために、可用性の推定と実際のポリシーの実行を同時に行うために Q-Transformer を使用する実験を行いました。その結果、それが以前のシステムよりも優れていることが示されました。以前の QT-Opt RT-1 と組み合わせました。 #指定された画像のタスク アフォーダンス値の例から、下流「「計画実行」フレームワークで高品質なアフォーダンス価値を提供可能 詳しくは原文をお読みください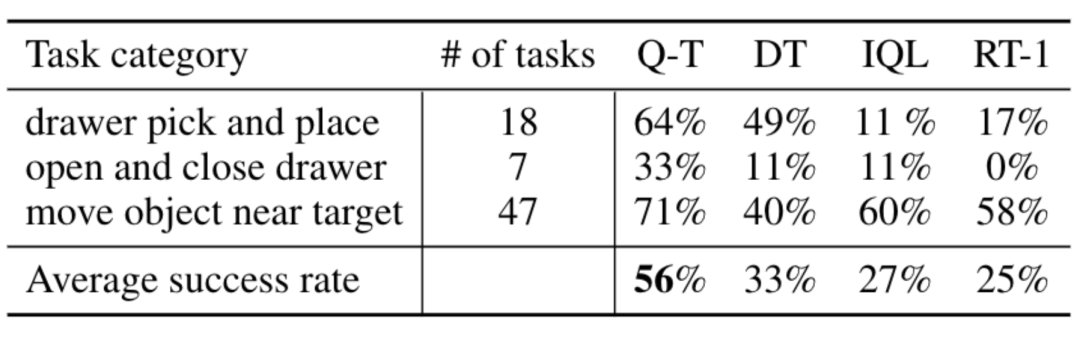

以上がGoogle DeepMind: 大規模モデルと強化学習を組み合わせて、ロボットが世界を認識するためのインテリジェントな脳を作成の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。