
ホームページ >テクノロジー周辺機器 >AI >「言葉は少なく、情報量は多い」SalesforceとMITの研究者がGPT-4の「改訂」を教える、データセットはオープンソース化
「言葉は少なく、情報量は多い」SalesforceとMITの研究者がGPT-4の「改訂」を教える、データセットはオープンソース化

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-09-20 23:57:02948ブラウズ
自動要約テクノロジーは、主にアノテーション付きデータセットの教師あり微調整から GPT-4 などのゼロショット プロンプトに大規模言語モデル (LLM) を使用するというパラダイム シフトにより、近年大きく進歩しました。 。追加のトレーニングを行わなくても、慎重に設計されたプロンプトにより、概要の長さ、トピック、スタイル、その他の機能をきめ細かく制御できます
しかし、見落とされがちな 1 つの側面、それは概要の情報密度です。理論的には、別のテキストを圧縮した要約は、ソース ファイルよりも密度が高く、つまりより多くの情報が含まれている必要があります。 LLM デコードの待ち時間が長いことを考慮すると、特にリアルタイム アプリケーションの場合は、より少ないワードでより多くの情報をカバーすることが重要です。
ただし、情報密度については未解決の問題です。要約に含まれる詳細が不十分な場合は、情報がないのと同じであり、情報が多すぎる場合、全体の長さは増加しません。 、わかりにくくなってしまいます。一定の語彙予算内でより多くの情報を伝えるには、抽象化、圧縮、融合を組み合わせる必要があります。
最近の研究では、Salesforce、MIT、その他の機関の研究者が次のことを目指しました。この制限は、GPT-4 によって生成される、ますます密度の高い要約セットに対する人間の好みを求めることによって決定されます。この方法は、GPT-4 などの大規模な言語モデルの「表現能力」を向上させるための多くのインスピレーションを提供します。

論文リンク: https://arxiv.org/pdf/2309.04269.pdf
データ設定アドレス: https://huggingface.co/datasets/griffin/chain_of_density
具体的には、この方法では、タグごとのエンティティの平均数を密度のプロキシとして使用し、初期値を生成します。エンティティが希薄な概要。次に、合計の長さを増やさずに (合計の長さは元のサマリーの 5 倍です)、前のサマリーから欠落している 1 ~ 3 個のエンティティを繰り返し識別して融合します。これにより、各サマリー内のタグに対するエンティティの比率が前のサマリーよりも高くなります。人間の嗜好データの分析を通じて、著者らは最終的に、人間が書いた要約とほぼ同じ密度で、通常の GPT-4 プロンプトによって生成される要約よりも密度の高い要約形式を特定しました。研究 彼の全体的な貢献には次のものが含まれます:
サマリーのエンティティ密度をますます高めるためのプロンプトベースの反復手法 (CoD) の開発;
- CNN/デイリー メール記事の高密度化する要約を手動および自動で評価し、有益性 (より多くのエンティティを優先) と明確さ (より少数のエンティティを優先) をより深く理解します。);
- 開くソース GPT-4 要約、注釈、および評価または改良用の 5000 個の注釈なし CoD 要約のセット。
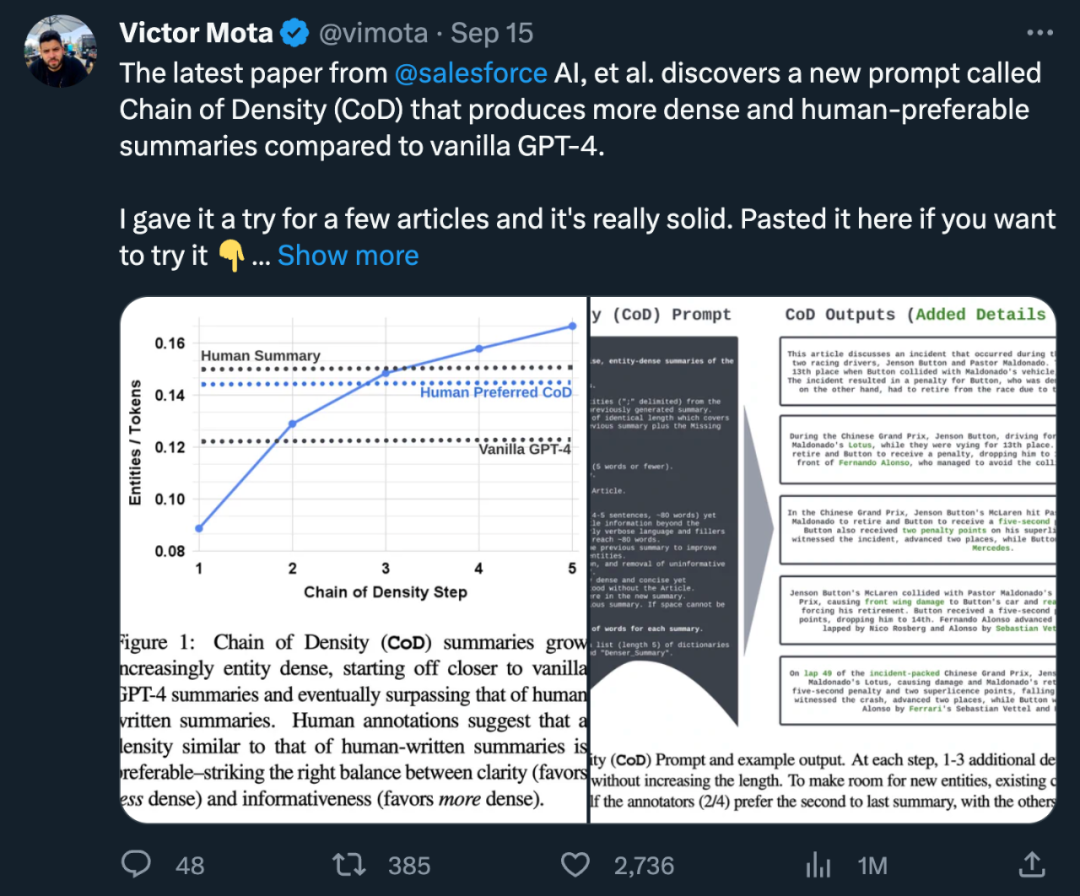
著者は「CoD」というゲームを立ち上げました (密度チェーン) 初期概要を生成し、そのエンティティ密度を徐々に増加させるためのヒント。具体的には、一定数のインタラクション内で、ソース テキスト内の一連の一意の顕著なエンティティが識別され、長さを増やすことなく前の概要にマージされます。
図 2 では、プロンプトと出力が行われます。例が示されています。著者はエンティティの種類を明示的に指定していませんが、欠落しているエンティティを次のように定義しています:
関連: メイン ストーリーに関連する;
- 具体的: 説明的だが簡潔 (5 単語以下);
- 小説: 以前の要約には登場していない;忠実: 記事内に存在します;
- Anywhere: 記事内の任意の場所にあります。
 #統計状況
#統計状況
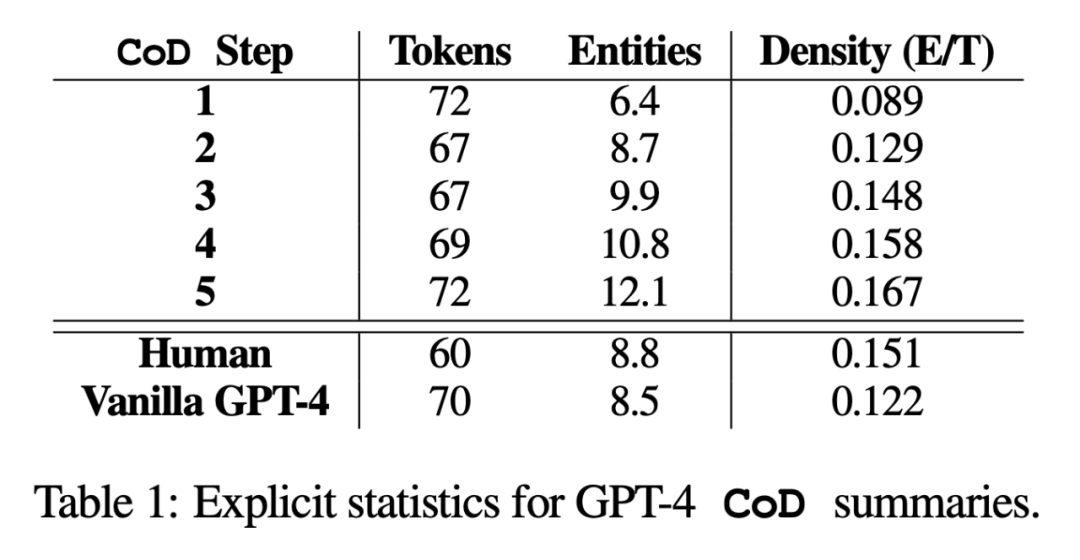
研究では、著者は直接統計データと間接統計データの 2 つの側面から要約しました。直接統計 (トークン、エンティティ、エンティティ密度) は CoD によって直接制御されますが、間接統計は高密度化の予期される副産物です。
書き換えられた内容は次のとおりです。 統計によると、長い要約から不要な単語を削除することで、第 2 ステップの平均の長さが 5 トークン短縮されました (72 から 67 に)。初期エンティティ密度は 0.089 で、ヒトおよびバニラ GPT-4 (0.151 および 0.122) よりも低く、5 つの高密度化ステップの後、最終的に 0.167
 まで上昇します。
まで上昇します。
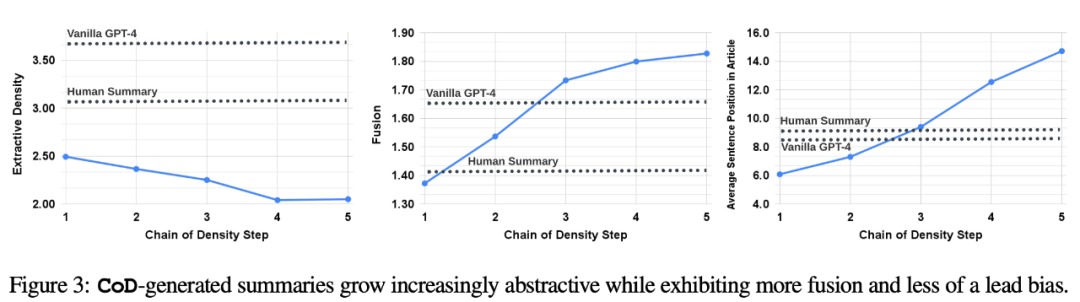
##間接的な統計。追加のエンティティごとにスペースを確保するために要約が繰り返し書き直されるため、CoD の各ステップで抽象化のレベルが増加するはずです。著者らは、抽出密度、つまり抽出されたフラグメントの平均平方長を使用して抽象化を測定しています (Grusky et al., 2018)。同様に、概念融合は、エンティティが固定長の要約に追加されるにつれて単調に増加する必要があります。著者らは統合度を各要約文に並べられた原文の平均数で表現した。位置合わせには、著者らは相対 ROUGE ゲイン法 (Zhou et al., 2018) を使用します。この方法では、追加の文の相対 ROUGE ゲインが正でなくなるまで、ソース文とターゲット文を位置合わせします。また、コンテンツの配布や、要約コンテンツの記事内での位置の変更も予想されていました。
具体的には、著者らは、Call of Duty (CoD) の概要が当初は強い「ブートストラッピング バイアス」を示すこと、つまり、より多くのエンティティが記事の冒頭で紹介されることを予想していました。ただし、記事が進むにつれて、この誘導バイアスは徐々に弱まり、記事の中盤と最後からエンティティが導入され始めます。これを測定するために、フュージョンでのアライメント結果を使用し、すべてのアライメントされたソース文の平均文ランクを測定しました。
図 3 は、これらの仮説を裏付けています。書き換えステップでは、数値が増加するにつれて、抽象化も増加し (左側の抽出密度が低くなります)、融合率が増加し (中央の画像)、要約に記事の中間と末尾のコンテンツが組み込まれ始めます (右の画像)。興味深いことに、すべての CoD 要約は、人間が作成した要約やベースライン要約と比較してより抽象的です。 #CoD サマリーのトレードオフをより深く理解するために、著者らは好みに基づく人間の研究を実施し、GPT-4
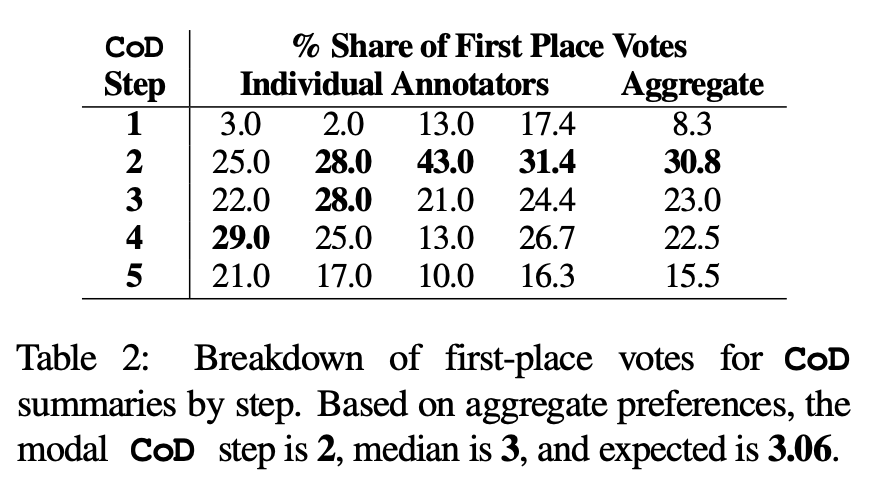
 humanpreference を利用して評価に基づく評価を実施しました。具体的には、同じ 100 件の論文 (5 ステップ *100 = 合計 500 件の要約) について、著者は「再作成された」CoD 要約と記事をランダムに論文の最初の 4 人の著者に見せました。各アノテーターは、Stiennon et al. (2020) の「良い要約」の定義に基づいて、自分のお気に入りの要約を提供しました。表 2 は、CoD 段階での各アノテーターの 1 位の投票と、各アノテーターの概要を示しています。全体として、1 位の抄録の 61% (23.0 22.5 15.5) には 3 つ以上の高密度化ステップが含まれていました。好ましい CoD ステップ数の中央値は中央 (3) で、予想ステップ数は 3.06 です。
humanpreference を利用して評価に基づく評価を実施しました。具体的には、同じ 100 件の論文 (5 ステップ *100 = 合計 500 件の要約) について、著者は「再作成された」CoD 要約と記事をランダムに論文の最初の 4 人の著者に見せました。各アノテーターは、Stiennon et al. (2020) の「良い要約」の定義に基づいて、自分のお気に入りの要約を提供しました。表 2 は、CoD 段階での各アノテーターの 1 位の投票と、各アノテーターの概要を示しています。全体として、1 位の抄録の 61% (23.0 22.5 15.5) には 3 つ以上の高密度化ステップが含まれていました。好ましい CoD ステップ数の中央値は中央 (3) で、予想ステップ数は 3.06 です。
#ステップ 3 の要約の平均密度に基づいて、すべてのサマリーの優先エンティティ密度を大まかに推測できます。 CoD 候補は 〜 0.15 です。表 1 からわかるように、この密度は人間が書いた要約 (0.151) と一致していますが、通常の GPT-4 プロンプトで書かれた要約 (0.122) よりも大幅に高くなります。
#自動測定。人間による評価 (下記) の補足として、著者らは GPT-4 を使用して、情報提供性、品質、一貫性、帰属性、全体性の 5 つの側面に沿って CoD 概要を採点しました (1 ~ 5 ポイント)。表 3 に示すように、密度は情報提供力と相関していますが、スコアはステップ 4 (4.74) でピークに達し、限界まで相関しています。
各次元の平均スコアから、CoD の最初と最後のステップのスコアが最も低く、中間のスコアが高くなります。 3 つのステップのスコアは近いです (それぞれ 4.78、4.77、4.76)。 ############定性分析。要約の一貫性/読みやすさと有益性の間には、明らかなトレードオフがあります。図 4 は、2 つの CoD ステップを示しています。1 つのステップの概要はより詳細な情報によって改善されていますが、もう 1 つのステップの概要は損なわれています。全体として、中間 CoD 要約はこのバランスを達成できますが、このトレードオフは今後の作業で正確に定義し、定量化する必要があります。 論文の詳細については、原論文を参照してください。 
以上が「言葉は少なく、情報量は多い」SalesforceとMITの研究者がGPT-4の「改訂」を教える、データセットはオープンソース化の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。