デコーダ専用構造 (GPT や LLAMA シリーズ モデルなど)、エンコーダ専用構造 (BERT など)、エンコーダ デコーダ構造 (T5 など) とそのバリアント モデルを含む大規模言語モデル (LLM) )目覚ましい成功を収め、さまざまな言語処理やマルチモーダル タスクで広く使用されています。 このような成功にもかかわらず、LLM のトレーニングは非常に高価であるため、それを行う余裕のある企業はわずかです。さらに、現在の傾向は、将来的にはより大きなトレーニング データが使用されることを示しており、これにより大規模モデルの開発コストがさらに増加することになります。たとえば、LLAMA-1 トレーニングでは 1 ~ 1.4 TB のトークンが使用されますが、Llama 2 では 2 TB に達します。 LLM 開発におけるもう 1 つの重要な課題は評価です。主流の評価方法は、知識評価 (MMLU および C-Eval) と NLP タスク評価の 2 つのカテゴリに分類されます。これらの評価方法は、データ漏洩の問題がある可能性があるため、モデルの機能を正確に反映していない可能性があります。つまり、評価データセットの一部がモデルのトレーニングプロセス中に使用されている可能性があります。さらに、知識指向の評価方法は、知能レベルの評価には適切ではない可能性があります。より公平で客観的な評価方法は、LLM の知能指数 (IQ) を測定することです。これは、トレーニング データには見られない条件やコンテキストに対して LLM を一般化することです。 #成長戦略。トレーニングコストの問題を解決するために、北京知源人工知能研究所や中国科学院コンピューティング技術研究所などの多くの機関が最近、いくつかの試みを行っている。つまり、学習コストの成長戦略を通じて1000億パラメータレベルのLLMをトレーニングするというものだ。初めて。成長とは、トレーニング中のパラメーターの数が固定されず、より小さなモデルからより大きなモデルに拡張されることを意味します。

- 論文: https://arxiv.org/pdf/2309.03852.pdf
- 必要書かれた内容は次のとおりです。 モデルリンク: https://huggingface.co/CofeAI/FLM-101B
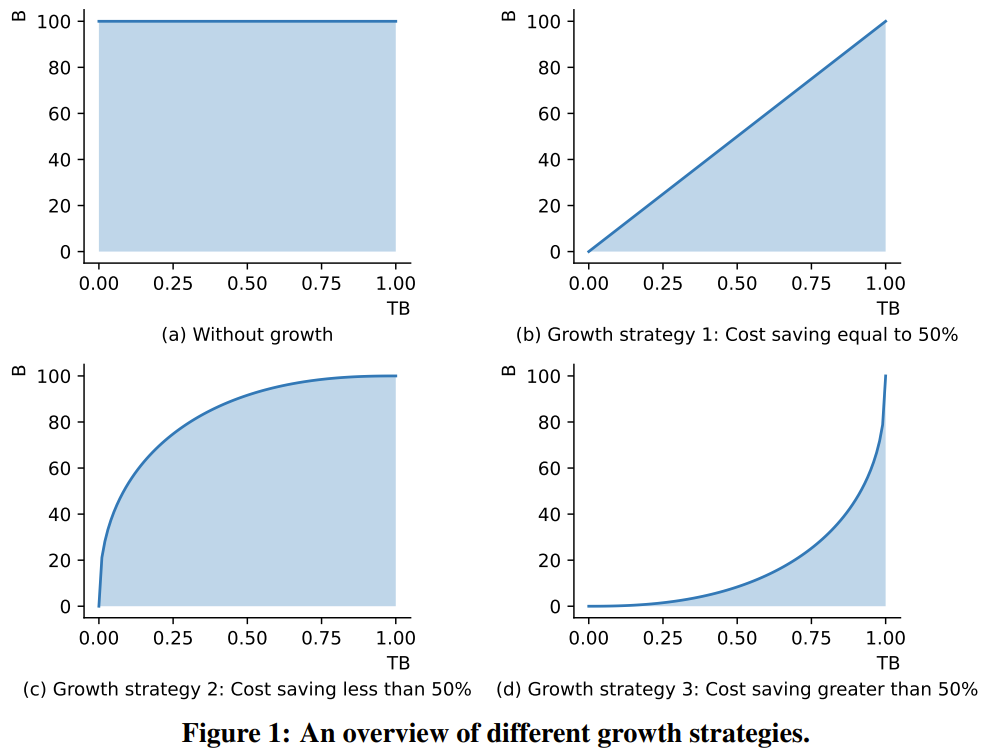
図 1 は、成長戦略の典型的な 3 つのシナリオを示しています。 LLM の FLOP はそのパラメータの数にほぼ比例するため、モデル パラメータの変化曲線と X 軸の間の面積はトレーニングの計算コストを表すことができます。
図 1 (a) は、モデルの成長を伴わない標準的なトレーニング戦略を示しています。1 (b) は、コストの 50% を節約できる線形成長戦略です。1 (c)は中程度の成長戦略であり、コストの 50% 未満を節約できます。1 (d) は急進的な成長戦略で、コストの 50% 以上を節約できます。この分析は、コンピューティング コストをできるだけ節約するには、積極的な成長戦略を採用する必要があることを示しています。 この新しい研究の成長演算子の設計は、論文「マスクされた構造成長による言語モデルの事前トレーニングの 2 倍高速化」の MSG からインスピレーションを受けています。 complete Transformer 構造の 4 つの成長次元すべてをカバーする一連の操作。さらに重要なのは、MSG は機能をしっかりと維持しながら成長できることです。したがって、小さなモデルはより小さなパラメーター検索空間で迅速に学習できますが、その知識は後続のより大きなモデルに継承される可能性があります。これにより、成長戦略では、同じかそれ以下の計算コストを使用して、より優れたパフォーマンスを達成することが可能になります。 オープンソースの FLM-101B モデル。 Zhiyuan Research Institute の研究者は、段階的な成長を通じて 1,010 億個のパラメーターを備えた LLM モデルをトレーニングし、このモデルをオープンソースとしてリリースする予定であるとも述べました。このモデルのアーキテクチャは FreeLM を進化させたものです。したがって、研究者らはこれを FLM-101B (F は Free の略) と名付けました。 #FreeLM フレームワークには 2 つの事前トレーニング目標があり、それぞれ言語シグナルと教師シグナルによって導かれます。この新しい研究では、これら 2 つの目標が共通の言語モデリング パラダイムに統合されます。 IQ 評価ベンチマーク。低コストのトレーニング パラダイムに加えて、チームは、LLM の知能指数 (IQ) 評価のための体系的なベンチマーク セットを提案するという別の貢献も行いました。 これまでの研究では、パープレキシティ レベル (PPL) 指標は生成されたテキストの品質をある程度反映できるものの、信頼できるものではないことが示されています。一方で、LLMの学習データの規模が大きすぎるため、そのモデルが単に知識データを引用しているだけなのか、本当に人間のような推論・分析・汎化能力を実現しているのかを区別することが困難です。この研究が IQ Foundation を定義するもの。一般的に使用される評価指標の一部 (英語の場合は MMLU、中国語の場合は C-Eval) は明らかに知識指向であり、モデルのインテリジェンス レベルを完全に反映することはできません。 健全性チェックのために、チームはテストを実施しました。世界的に有名な大学の 5 人のコンピューター サイエンス研究者が、C-Eval の化学テスト問題を使用して試験を受けました。ボランティアのほとんどは化学について学んだことを忘れていたため、彼らの精度はランダムな推測とほぼ同じくらい優れていたことが判明しました。したがって、専門知識を重視する評価ベンチマークは、モデルの IQ を測るには適切ではありません。 LLM の IQ を包括的に測定するために、チームは IQ の 4 つの主要な側面 (シンボル マッピング、ルール理解、パターン マイニング、アンチ干渉。
言語は本質的に象徴的なものです。 LLM の知能レベルを評価するために、カテゴリ ラベルではなくシンボルを使用した研究がいくつかあります。同様に、チームはシンボリック マッピング アプローチを使用して、目に見えないコンテキストを一般化する LLM の機能をテストしました。
人間の知性の重要な能力は、与えられたルールを理解し、対応するアクションを実行することです。このテスト方法は、さまざまなレベルのテストで広く使用されています。したがって、ここではルールの理解が第二のテストになります。
書き直された内容: パターン マイニングはインテリジェンスの重要な部分であり、帰納と演繹が含まれます。科学の発展の歴史において、この方法は重要な役割を果たします。さらに、さまざまな競技会のテスト問題では、この解答能力が求められることがよくあります。これらの理由から、3 番目の評価指標としてパターン マイニングを選択しました。
最後の非常に重要な指標は、インテリジェンスの中核機能の 1 つでもある耐干渉能力です。研究では、言語と画像の両方がノイズによって容易に妨害されることが指摘されています。これを念頭に置いて、チームは干渉耐性を最終評価基準として使用しました。
もちろん、これら 4 つの指標は、LLM IQ 評価の最終決定ではありませんが、その後の研究開発を刺激する出発点として機能し、最終的にはLLM IQ 評価フレームワークの包括的なセットにつながります。
研究者らは、これは成長戦略を使用して、より多くのトレーニングを行う研究であると述べています。 1,000 人をゼロから、10 億のパラメータに対する LLM 研究の試み。同時に、これは現在最も低コストの 1,000 億パラメータ モデルでもあり、コストはわずか 10 万米ドルです。
FreeLM トレーニング目標、潜在的なハイパーパラメータ検索方法、および機能を維持した成長を改善することにより、この研究は不安定性の問題に取り組んでいます。研究者らは、この方法がより広範な科学研究コミュニティにも役立つと信じています。
研究者らはまた、知識指向ベンチマークや新しく提案された系統的 IQ 評価ベンチマークの使用など、新しいモデルと以前の強力なモデルとの実験的な比較も実施しました。実験結果は、FLM-101B モデルが競争力があり堅牢であることを示しています
チームは、1,000億パラメータ規模の中国語と英語のバイリンガルLLMの研究開発を促進するため、モデルチェックポイント、コード、関連ツールなどをリリースします。
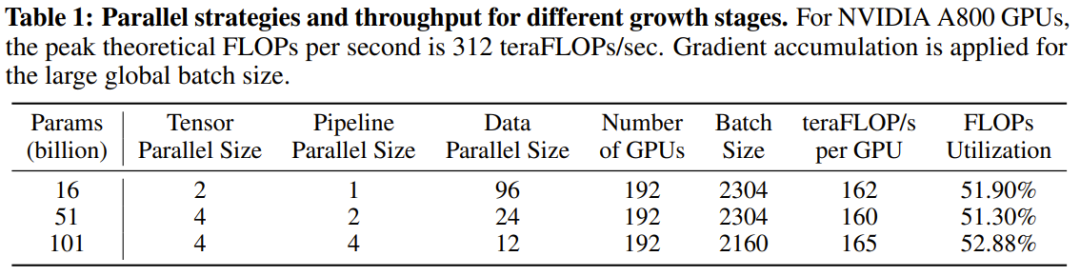
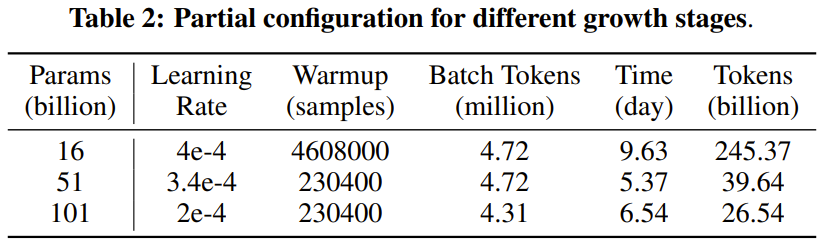
FLM-101B はアーキテクチャ的に、バックボーン ネットワークとして FreeLM を使用します。そしてxPosを統合します。モデル サイズに関しては、新しい成長戦略のおかげで、研究者は 1 回のトレーニングで 16B、51B、101B の 3 サイズのモデルを取得できます。 FLM-101B は、トレーニング前の設定に関して、FreeLM のトレーニング戦略を継承しています。 成長戦略の観点からは、異なるサイズのモデルを個別にトレーニングする一般的な方法の代わりに、チームは 16B、51B、および 101B のパラメーターを使用して 3 つのモデルを順番にトレーニングできます。これらの各モデルは、その前の小さなモデルの知識を継承します。 #トレーニング ハードウェアとしては、24 台の DGX-A800 GPU (8x80G) サーバーのクラスターが使用され、FLM-101B のトレーニング時間は 26 日未満です。複数並列戦略とモデル構成については、以下の表 1 および 2 を参照してください。
#FLM-101B のトレーニングの安定性
損失発散や勾配爆発などの不安定な問題を解決するために、研究者らは有望な解決策を提案しました。これについては次のように簡単に説明します。 #損失予測。学習の安定性を実現するために新しく提案された方法は次のとおりです。
まず、FLM-16B 学習を開始する前にデータの分布を決定します。
次に、学習率、初期化標準偏差、出力層のソフトマックス温度を含む 3 つのハイパーパラメーターに対してグリッド検索を実行します。グリッド検索は、隠れ状態の次元 (モデル幅) 256、ヘッド数 2、およびパラメーター数 4,000 万のサロゲート モデルを実行することによって実行されます。この代理モデルの他のすべての構造ハイパーパラメーターとトレーニング データは FLM-16B と同じです。 6 ノードでのデータ並列処理を使用した場合、グリッド検索の実行には 24.6 時間かかりました。これは、24 ノード構成を使用するとおよそ 6 時間に相当します。
このグリッド検索を通じて、研究者らは最適なハイパーパラメータを発見しました: 学習率 = 4e-4、標準偏差 = 1.6e-2、ソフトマックス温度 = 2.0。
その後、これらのハイパーパラメータを µP 経由で移行して、不安定性の問題を回避するシームレスなトレーニング エクスペリエンスを実現します。 MSG を組み合わせて使用すると、LM-51B と FLM-101B ではその後の成長発散の問題が発生しません。
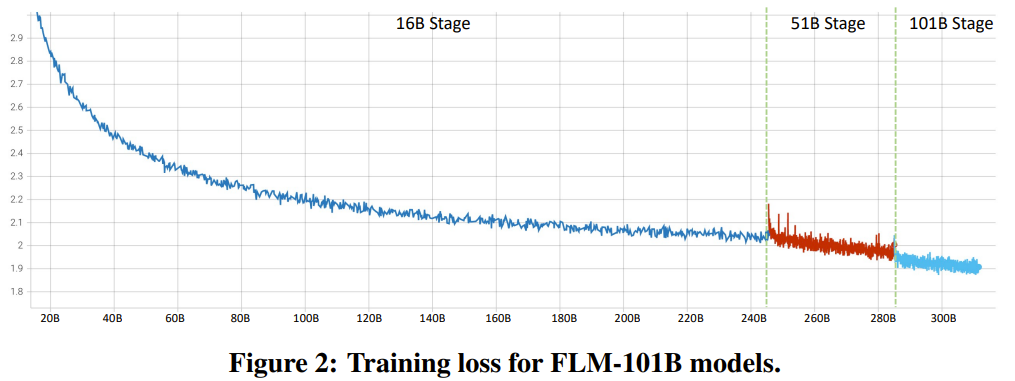
# 図 2 は、完全なトレーニング損失曲線を示しています。
Bfloat16 による混合精度。混合精度を使用する目的は、実行時のメモリと時間のコストを節約することですが、ここでは Bfloat16 を選択しました。
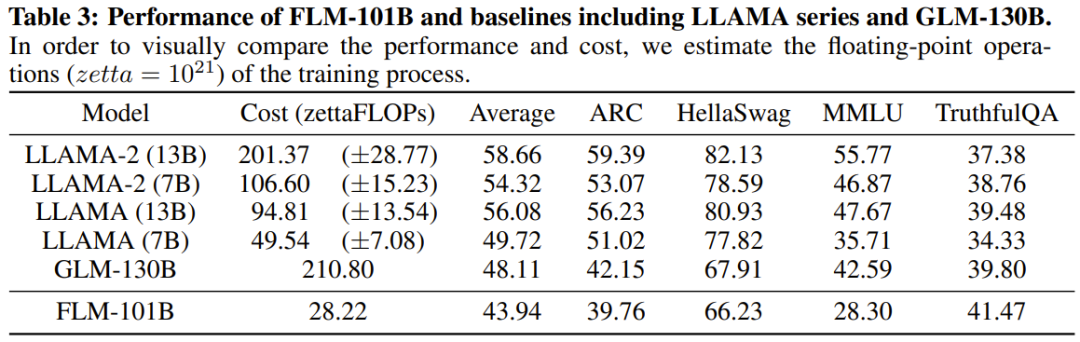
表 3 は、FLM-101B と他のパフォーマンスの比較です。強力なベースラインモデル(LLAMAシリーズモデルおよびGLM-130B)の。
研究者らは、これらの結果はFLM-101Bが事実知識において何の利点も持たないことを示しており、より多くのトレーニングデータを使用できればそのパフォーマンスは継続すると述べています。
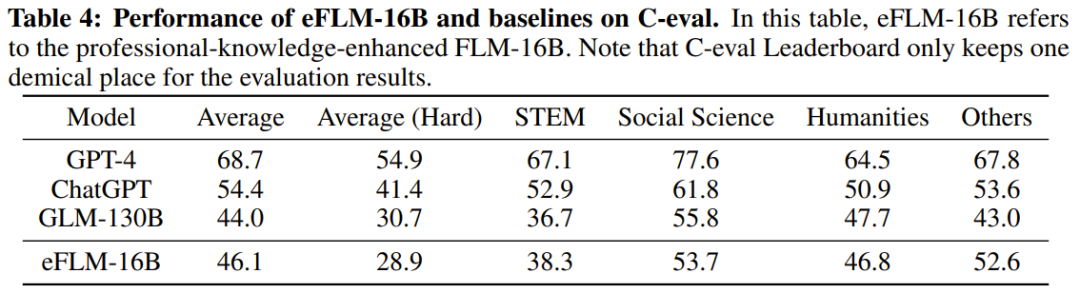
#表 4 は、専門知識の評価に関する eFLM-16B とベースライン モデルの結果を示しています。 特定のトレーニング データが圧倒的な貢献をしている可能性があるため、専門知識を強調するデータセットのスコアは LLM のインテリジェンスのレベルを反映していないことが判明しました。
#表 5 は、FLM モデルの各段階のパフォーマンスを示しています。
予想どおり、モデルが増えるにつれて FLM のパフォーマンスは向上します。 FLM-101B は、ほぼすべてのミッションで最高のパフォーマンスを発揮しました。これは、モデルが成長するたびに、前の段階からの知識が継承されることを意味します。 実験では、 LLM の IQ より体系的な評価を行うために、知的財産研究所のチームは既存の IQ 関連データセットを使用し、必要な修正を加え、新しい合成データも生成しました。 具体的には、彼らが提案した IQ 評価では、シンボル マッピング、ルール理解、パターン マイニング、および耐干渉の 4 つの側面が主に考慮されています。これらのタスクには重要な共通点が 1 つあります。それは、すべてが新しいコンテキストでの推論と一般化に依存しているということです。
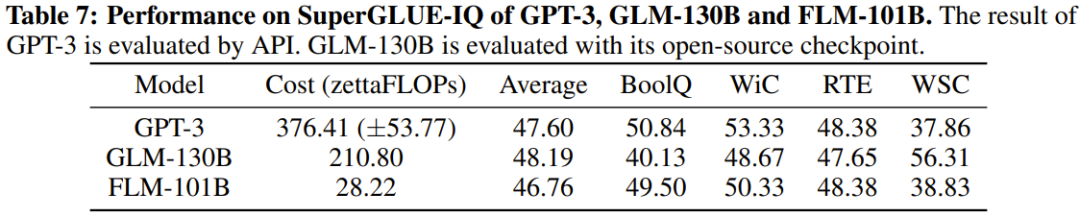
##これらの表から、4 つの IQ 評価ベンチマークにおいて、FLM-101B は GPT-3 に匹敵し、はるかに低い計算コストで GLM-130B よりも優れた結果を達成しています。
研究者らは、トレーニング データの影響に加えて、この利点は、初期段階の小さなモデルがより小さな探索空間を洗練するためである可能性があると推測しています。モデルがさらに大きくなり、より広くなり、汎化機能が強化されても、この利点は引き続き発揮されます。 以上が100,000 米ドル + 26 日で、1,000 億パラメータの低コスト LLM が誕生の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。




 ##これらの表から、4 つの IQ 評価ベンチマークにおいて、FLM-101B は GPT-3 に匹敵し、はるかに低い計算コストで GLM-130B よりも優れた結果を達成しています。
##これらの表から、4 つの IQ 評価ベンチマークにおいて、FLM-101B は GPT-3 に匹敵し、はるかに低い計算コストで GLM-130B よりも優れた結果を達成しています。